perlbrew
Das System-Perl zu verwenden hat viele Nachteile. Diese können behoben werden, wenn man ein eigenes Perl in seinem Benutzerverzeichnis installiert. Mit dem Werkzeug perlbrew kannst du mehrere Perl-Installationen nebeneinander auf einem System konfliktfrei betreiben.
Die Probleme mit dem System-Perl
Die Anwendungsentwicklung mit dem System-Perl zu koppeln bringt viele Nachteile mit sich. Hier einige Beispiele:
- Perl kann nicht unabhängig vom System aktualisiert werden, wenn du Probleme beheben möchtest, neue Sprach-Features nutzen willst – oder vielleicht sogar ganz bewusst ein Perl nutzen möchtest, das älter als das System-Perl ist.
- In Organisationen sind Entwickler häufig von den Systemadministratoren abhängig, die die Stabilität des gesamten Systems und nicht nur einer Anwendung beachten müssen, und deswegen nicht »einfach so« Perl aktualisieren können.
- Die Installation von CPAN-Modulen ist wegen fehlender Berechtigungen nicht möglich.
- Der Test von Anwendung unter neueren Perl-Versionen auf einem System ist nicht einfach möglich.
Eine Lösung ist perlbrew, das die Installation mehrerer Perl-Versionen im Benutzerverzeichnis ermöglicht, so dass keine Administratorrechte benötigt werden. Das Werkezeug isoliert diese Installationen voneinander und ermöglicht einen einfachen Wechsel zwischen ihnen.
Admin-freie Installation von Perl-Versionen
Die Installation von perlbrew ist auf zwei Wegen möglich. Die einfachste geht über cpanm:
$ cpanm App::perlbrew
$ perlbrew init
Solltest du keine Module von CPAN installieren können (siehe meine Anmerkung oben zu fehlenden Adminstratorrechten), kannst du dir ein Installationsskript herunterladen und es von der Shell ausführen lassen. Aus Sicherheitsgründen verweise ich dich dafür auf die Homepage.
perlbrew kann alle offiziell verfügbaren Perl-Versionen bauen und installieren. Welche das sind, kannst du dir auflisten lassen:
$ perlbrew available
perl-5.33.7
perl-5.32.1
perl-5.30.3
perl-5.28.3
perl-5.26.3.tar.bz2
...
perl-5.8.9.tar.bz2
perl-5.6.2
perl5.005_03
perl5.004_05
cperl-5.29.2
cperl-5.30.0
cperl-5.30.0-RC1
Aus diesen Versionen wählst du dir eine aus. Diese wird dann in das Verzeichnis perl5/perlbrew im Benutzerverzeichnis installiert:
perlbrew install perl-5.33.7
$ perlbrew install perl-5.33.7
Fetching perl 5.33.7 as $HOME/perl5/perlbrew/dists/perl-5.33.7.tar.gz
Download http://www.cpan.org/src/5.0/perl-5.33.7.tar.gz to $HOME/perl5/perlbrew/dists/perl-5.33.7.tar.gz
Installing /Users/glauschwuffel/perl5/perlbrew/build/perl-5.33.7/perl-5.33.7 into ~/perl5/perlbrew/perls/perl-5.33.7
This could take a while. You can run the following command on another shell to track the status:
tail -f ~/perl5/perlbrew/build.perl-5.33.7.log
Wenn du den in der letzten Zeile angegeben Befehl in einer zweiten Shell ausführt, kannst du dem Installationprozess »zusehen«.
Welches Perl die Shell ausführt, wird durch den Ausführungspfad bestimmt. Durch die Änderung dieses Ausführungspfads wird zwischen den installierten Perl-Versionen umgeschaltet. Dafür gibt es den perlbrew-Befehl use:
$ perlbrew use perl-5.33.7
Durch mehrfache Verwendung von perlbrew use kannst du in einer Arbeitssitzung in der Shell zwischen den Versionen wechseln. Beim Öffnen einer weiteren Shell wird aber weiterhin das System-Perl verwendet. Wenn du dauerhaft eine Perl-Version verwenden möchtest, kann du mit dem Befehl switch die gewünschte Version in der Shell-Konfiguration ablegen:
perlbrew switch perl-5.33.7
Gelegentlich kommt es bei der Arbeit mit perlbrew vor, dass kurzfristig das System-Perl benutzt werden soll:
perlbrew switch-off
Mit den hier gezeigten Befehlen hast du nun die grundlegenden Werkzeuge zusammen, um dir die Perl-Versionen zu installieren, die du benötigst. Da sich alles in deinem Benutzerverzeichnis abspielt, hast du die volle Kontrolle.
Zusammenfassung
In diesem Artikel habe ich einen kurzen Überblick über die Möglichkeiten gegeben, die perlbrew bietet. Dabei konnte ich vieles nur anreißen. Wenn du jetzt neugierig geworden bist und tiefer einsteigen möchtest, empfehle ich dir die Homepage des Projekts, um mehr über weitere Befehle zu erfahren.
Permalink: /2021-07-14-perlbrew
Bericht vom Deutschen Perl-/Raku-Workshop 2021
Der Deutsche Perl-/Raku-Workshop (German Perl Workshop
, GPW) ist eine Institution in der Perl-Community: Seit 1999 gibt es diese Konferenz rund um Perl (und seit ein paar Jahren Raku). Damit ist der GPW eine der ältesten Perl-Veranstaltungen überhaupt.
In diesem Jahr fand die Konferenz zum ersten Mal rein online statt. Wir waren als Sponsor und mit einigen Vorträgen auf der Konferenz vertreten. Die Vorträge waren auf drei Nachmittage vom 24.-26. März 2021 verteilt.
Über die Technik hinter dem Workshop wollen die Organisatoren noch ein Artikel auf perl.com veröffentlichen. Ein paar (für mich) besondere Vorträge will ich hier ganz kurz beleuchten.
Nach der allgemeinen Begrüßung gab es einen Talk von Paul Evans über Perl in 2025
, in dem er (mögliche) neue Features in Perl und den Weg dahin vorgestellt hat. Ein try {} catch {} hat es ja mittlerweile in den Perl-Core geschafft (wird demnächst mit Perl 5.34 als experimentelles Feature ausgeliefert) und weitere Features probiert Paul über CPAN-Module aus. Es lohnt sich, seinem CPAN-Account zu folgen und das Video zeigt viele interessante Ideen.
Ein etwas älteres Programm stellte Sec
vor: Beopardy, das jährlich auf dem CCC-Kongress beim Hacker Jeopardy
läuft und für die Jeopardy-typische Fragewand und das Handling der Buzzer zuständig ist. In dem Vortrag wird die interessante Entwicklung von Beopardy gezeigt... Meine letzten Erfahrungen mit Perl/Tk liegen schon einige Jahre zurück und ich habe so einige Probleme damit selbst erlebt.
Auch Raku war ein Thema auf der Konferenz. Es wurde z.B. das Pheix CMS vorgestellt. Ein CMS in Raku klingt gut, aber warum man Daten eines CMS in einer Blockchain speichern muss, weiß ich nicht.
Für mich weit relevanter war da der Vortrag von Jonathan Worthington über Things you may not know about Cro
. Ich nutze Cro derzeit, um Informationen über unsere Domains, Cloudserver etc. zu sammeln und konnte bei dem Vortrag einiges mitnehmen. Cro ist eine Sammlung von Bibliotheken zur Entwicklung von verteilten Systemen und bietet z.B. eine Klasse für HTTP-Server, Websockets und HTTP-Clients.
Da ich selbst schon ein paar Entwicklerversionen von Perl veröffentlicht habe, gab es beim Vortrag Perl-Release für jedermann
von Max Maischein nichts neues für mich. Wer wissen möchte, was hinter einem Release von Perl steckt, sollte sich aber das Video dazu anschauen.
Die Videos der Talks sind unter https://media.ccc.de/c/gpw2021/GPW2021 erreichbar.
Eine Online-Konferenz ist bei weitem nicht das gleiche wie eine Präsenzveranstaltung – gerade wenn man sonst viele Freunde treffen würde. Aber der diesjährige GPW hat gezeigt, dass es auch in diesen Zeiten interessante Dinge gibt, über die gesprochen werden sollte.
Und auch die soziale Komponente blieb nicht ganz aus: Am zweiten Abend gab es noch ein gemeinsames
Kochen. Die Rezepte dazu sind online zu finden.
Auch dass die Vorträge nur nachmittags waren, fand ich gut. Zum einen ist es schwer, sich den ganzen Tag auf Videos zu konzentrieren und zum anderen konnte man den Vormittag noch anderweitig nutzen.
Wir hoffen, dass es im nächsten Jahr wieder vor Ort klappt. Angekündigt ist der 24. Deutsche Perl-/Raku-Workshop für den 30. März bis 01. April 2022 in Leipzig.
Permalink: /2021-06-23-bericht-vom-deutschen-perl-raku-workshop-2021
Kommandozeilenwerkzeuge mit App::Cmd
Das Schreiben von CLI-Tools erfordert einiges an Infrastrukturcode, um ein komfortables Tool mit Kommandos zu erstellen. Teile dieses Codes gleichen sich bei der Implementierung von Unterkommandos. Die Distribution App::Cmd hilft mit Mitteln der objektorientierten Entwicklung dabei, ein komfortables CLI-Tool schnell und erweiterbar zu implementieren.
Infrastrukturcode als lästige Notwendigkeit
Nutzer moderner Kommandozeilenwerkzeuge erwarten eine komfortable Nutzerführung mit Hilfetexten, Unterkommandos und einheitlicher Verwendung.
Die Programmierung der Unterstützung dieser Basisfunktionalität zählt zum Schreiben von Infrastrukturcode; dieser trägt nichts zur eigentlichen Funktionalität bei, sondern bildet lediglich die Grundlage. Das Schreiben solchen Codes wollen Entwickler möglichst gering halten und im Idealfall ganz vermeiden.
Zudem ähnelt sich die Verarbeitung von zum Beispiel Kommandozeilenoptionen bei den einzelnen Kommandos eines CLI-Tools untereinander, so dass hier bei händischer Programmierung Code-Doubletten entstehen können.
In diesem Artikel zeige ich den Einstieg in App::Cmd. Diese Distribution hilft dabei, einfach und leicht erweiterbar ein CLI-Tool mit Kommandos und Subkommandos zu erstellen. Das Schreiben von Infrastrukturcode wird dabei stark verringert.
Ein einfaches Beispiel
Um die einfache Verwendung von App::Cmd zu zeigen, implementieren wir hier ein Tool namens clitest, das ein einziges Kommando list kennt.
Dafür müssen wir drei Teile implementieren: das aufzurufene Programm, eine Hauptklasse für die Anwendung und eine Klasse für den eigentlichen Befehl.
Das Programm
Wir bauen das Werkzeug als Perl-Distribution auf. Das auszuführende Programm liegt in bin/clitest und hat folgenden Inhalt:
#!/usr/bin/perl
use CLITest;
CLITest->run;
Das Programm lädt die Hauptklasse der Anwendung und führt eine Methode aus, die sich dann um die Verarbeitung der Kommandozeilenargumente kümmert.
Die Anwendungsklasse
Die Hauptklasse der Anwendung ist ähnlich schlank wie das eben gezeigte Programm:
package CLITest;
use App::Cmd::Setup -app;
1;
Hier wird der Namensraum CLITest festgelegt, in dem sich alle Befehle als Packages befinden.
Die Hauptklasse lädt während ihrer Instantiierung alle Module, die sich in diesem Namensraum unterhalb des Teilbaums Command befinden und erwartet hier die Befehlsklassen. Die Klasse für unseren Befehl list implementieren wir nun.
Die Befehlsklasse
Wir haben eine Befehlsklasse CLITest::Command::list:
# ABSTRACT: list files
package CLITest::Command;
use CLITest -command;
use File::Find::Rule;
sub usage_desc { "list <dir>" }
sub description { "The list command lists ..." }
sub execute {
my ($self, $opt, $args) = @_;
my $path=$args->[0];
my $rule = File::Find::Rule->new;
$rule->file;
$rule->name('*');
my @files = $rule->in( $path );
print "$_\n" in @files;
}
1;
In ihr definieren wir die Methode execute. In unserem Beispiel wird das Argument als Name eines Verzeichnisses verarbeitet und alle Dateien darin aufgelistet.
Jetzt haben wir schon ein lauffähiges CLI-Tool und können es aufrufen:
perl -Ilib bin/clitest list
Das war es auch schon.
Die nächsten Schritte
In den nächsten Schritten wäre nun aus unserem kleinen Beispiel eine »echte« Distribution zu erstellen (etwa mit Dist::Zilla) und der angedachte Befehl list weiter auszugestalten.
App::Cmd bringt ein Tutorial mit, in dem der Autor beschreibt, wie der Entwickler …
- Hilfetexte für Befehle festgelegen kann,
- Optionen und Unterkommandos beschreiben kann,
- und wie über eine Konfigurationsdatei Vorgabewerte für Optionen festgelegt werden können.
Zusammenfassung
In diesem Artikel habe ich einen Einstieg in App::Cmd gezeigt. Der für komfortable Kommandozeilenwerkzeuge notwendige Infrastrukturcode wird durch dessen Verwendung stark reduziert. Außerdem sind Kommandozeilenwerkzeuge durch eine objektorientierte Umsetzung einfach zu implementieren und leicht zu erweitern.
Permalink: /2021-02-15-app-cmd
An Modul-Autoren: Badges für CPANCover
Sowohl für Nutzer als auch für Entwickler ist es ganz schön, wenn auf einen Blick der Zustand eines Moduls ersichtlich ist: Sind Fehler bekannt? Kann das Projekt gebaut werden? Wie ist die Testabdeckung?
Dazu können z.B. bei Gitlab oder GitHub sogenannte Badges angezeigt werden. Hier ein kleines Beispiel unseres Moduls Markdown::Table.
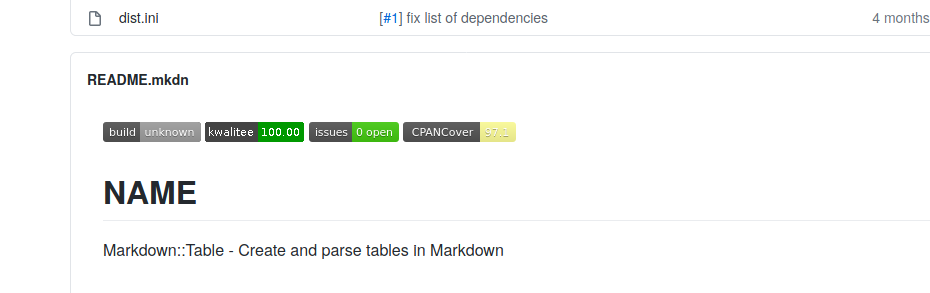
Paul Johnson stellt eine Seite bereit, auf der die Testabdeckung mit Devel::Cover angezeigt wird: CPANCover. Für das oben genannte Modul ist die Testabdeckung unter http://cpancover.com/latest//Markdown-Table-0.04/index.html zu finden.
Wir stellen einen Dienst bereit, der die Daten von CPANCover als einen solchen Badge zur Verfügung stellt: CPANCoverBadge. Das ist eine ganz kleine Anwendung, die auch auf CPAN liegt. Es werden einfach nur die Daten von CPANCover ausgelesen und mit Badge::Simple ein solches Badge erstellt. Für Markdown::Table 0.04 ist das Badge dann unter https://cpancoverbadge.perl-services.de/Markdown-Table-0.04 zu finden.
Um dieses Badge z.B. in der README.md anzuzeigen, muss mit Markdown-Mitteln die Grafik angezeigt werden:
[](https://cpancoverbadge.perl-services.de/Markdown-Table-0.04)
Für alle, die Dist::Zilla nutzen, gibt es ein Plugin, um diverse Badges einzubauen: Dist::Zilla::Plugin::GitHubREADME::Badge
Damit muss in der dist.ini ein Block eingefügt werden, in der die Badges konfiguriert werden:
[GitHubREADME::Badge]
badges = travis
badges = cpants
badges = issues
badges = cpancover
phase = build
place = top
Damit werden die vier oben gezeigten Badges eingeblendet.
Permalink: /2021-02-09-badges-cpancover
CPAN-News Januar 2021
Der Januar ist rum, Zeit mal nachzuschauen was wir im Januar so alles auf CPAN geladen haben.
Zurerst ein Blick auf komplett neue Module:
Dist-Zilla-Plugin-SyncCPANfile
Wir nutzen *cpanfile*s um die Abhängigkeiten in unseren Projekten zu definieren. Und wir nutzen Dist::Zilla zum Bauen von Distributionen. Dafür gibt es das Plugin Dist::Zilla::Plugin::CPANFile. Das erstellt das cpanfile aber erst in der Distribution. Wir möchten die Datei aber direkt im Repository haben.
Aus diesem Grund haben wir Dist::Zilla::Plugin::SyncCPANfile geschrieben, das die in der dist.ini gelisteten Abhängigkeiten in ein cpanfile schreibt.
Folgendes einfach in die dist.ini schreiben (aus der SYNOPSIS):
# in dist.ini
[SyncCPANfile]
# configure it yourself
[SyncCPANfile]
filename = my-cpanfile
comment = This is my cpanfile
OTRS-OPM-Validate
Ein weiteres Modul, das neu geschrieben wurde, ist OTRS::OPM::Validate. Mit diesem Modul ist es möglich, Erweiterungen für Ticketsysteme wie Znuny, OTOBO, ((OTRS)) Community Edition validieren. Die Dateien sind XML-Dateien mit bestimmten Inhalten.
Da die Entwicklung aber nicht mit einem bestimmten Schema erfolgte und XML::LibXML::Schema nicht das neueste XML-Schema unterstützt, musste was eigenes her.
Das Modul nutzt Reguläre Ausdrücke sehr intensiv...
Aber auch bestehende Module haben ein Update erfahren:
DNS::Hetzner
Dieses Modul ermöglicht es, das REST-API für DNS von Hetzner zu nutzen. Im Januar wurde das Modul mehr oder weniger komplett neu geschrieben, es hat etliche Tests bekommen und die Klassen für das API wurden neu generiert, so dass auch die neuesten Endpunkte unterstützt werden.
use DNS::Hetzner;
use Data::Printer;
my $dns = DNS::Hetzner->new(
token => 'ABCDEFG1234567', # your api token
);
my $records = $dns->records;
my $zones = $dns->zones;
my $all_records = $records->list;
p $all_records;
CPANfile::Parse::PPI
Da dieses Modul ein statischer Parser für *cpanfile*s ist, wurde ein strict-Modus eingeführt. Damit bricht das Modul ab, wenn dynamische Konstrukte wie
for my (qw/
IO::All
Zydeco::Lite::App
/) {
requires , '0';
}
in der Datei stehen.
use CPANfile::Parse::PPI -strict;
use Data::Printer;
my $required = do { local $/; <DATA> };
my $cpanfile = CPANfile::Parse::PPI->new( \$required );
my $modules = $cpanfile->modules;
__DATA__
for my $module (qw/
IO::All
Zydeco::Lite::App
/) {
requires $module, '0';
}
OTRS-OPM-Installer
Hier wurden nur ein paar Änderungen vorgenommen, weil OTRS::OPM::Parser auf Moo umgestellt wurde und sich das Verhalten ein wenig geändert hat (einige Attribute liefern keine Arrays mehr, sondern Arrayreferenzen).
OTRS-OPM-Parser
Jetzt wird zum Validieren der .opm-Dateien unser neues Module OTRS::OPM::Validate genutzt.
Permalink: /2021-02-06-cpannews-januar-2021
Sicherheit für Perl-Anwendungen: fail2ban
Ist eine Webanwendung öffentlich erreichbar, wird es nicht lange dauern und irgendwelche Bots versuchen sich anzumelden. Oder es werden wild irgendwelche URLs aufgerufen. Auch wenn die Anmeldeversuche wahrscheinlich scheitern, geht die Bot-Aktivität zu Lasten der Webanwendung. Und mit genügend versuchen klappt es vielleicht doch mal, dass sich jemand Unbefugtes anmeldet.
Aus diesem Grund sollte man IP-Adressen nicht dauerhaft auf die Webanwendung lassen. Sie sollten nach einer bestimmten Anzahl an Fehlversuchen ausgesperrt werden.
Unter Linux kann man das bequem mit iptables machen. Aber wie ist die Syntax um jemanden auszusperren? Und muss man die Fehlversuche selbst raussuchen und dann die IPs sperren? Nein. Für diese Aufgabe gibt es fail2ban.
fail2ban ist ein Tool, das die Firewallregeln von iptables aktualisiert. Also IP-Adressen sperren und die Sperre wieder aufheben kann. Nach der Installation mittels
apt install fail2ban
kann das Tool direkt loslegen und z.B. SSH-Loginversuche auswerten. Dazu nimmt es die SSH-Logs und durchsucht diese nach Fehlversuchen. Wird eine bestimmte Anzahl von Fehlversuchen registriert, werden die Regeln von iptables aktualisiert.
Damit das Tool nicht nur SSH-Logs durchsucht und Angriffsversuche entdeckt, werden sogenannte Filter für verschieden Anwendungen wie Apache, MySQL, Nagios und viele mehr zur Verfügung gestellt.
Man kann aber auch eigene Anwendungen schützen. Als Beispiel nehmen wir eine Mini-Anwendung, die mit Mojolicious umgesetzt ist:
#!/usr/bin/perl
use strict;
use warnings;
use Mojolicious::Lite -signatures;
get '/' => 'index';
post '/' => sub ($c) {
if ( $c->param('user') ne 'Test' ) {
return $c->redirect_to('/');
}
$c->session( logged_in => 1 );
$c->redirect_to( '/welcome' );
};
under '/' => sub ($c) {
if ( !$c->session('logged_in') ) {
$c->redirect_to('/');
return;
}
return 1;
};
get '/welcome' => sub ($c) {
$c->render( data => 'Welcome!' );
};
app->start;
__DATA__
@@ index.html.ep
<form action="/" method="post">
<input type="text" name="user">
</form>
Es gibt eine Route, um sich anzumelden und ist die Anmeldung erfolgreich bekommt man eine Willkommensseite. Nichts spezielles.
Um diese Anwendung mit fail2ban zu schützen, müssen wir etwas mehr loggen - nämlich die erfolglosen Loginversuche.
# [...]
if ( $c->param('user') ne 'Test' ) {
$c->app->log->warn(
sprintf "Login failed for host <%s>",
$c->tx->remote_address
);
return $c->redirect_to('/');
}
# [...]
Wenn wir jetzt die Anwendung aufrufen und ganz häufig die falschen Zugangsdaten eingeben oder nicht-existente Routen aufrufen, passiert nichts. Die Anwendung kann immer wieder aufgerufen werden.
Jetzt richten wir fail2ban ein.
Als erstes benötigen wir einen Filter. Dazu erstellen wir die Datei /etc/fail2ban/filter.d/app.conf mit folgendem Inhalt:
[Definition]
failregex = .* Login failed for host "<HOST>"
ignoreregex =
Bei failregex wird ein Regulärer Ausdruck angegeben, mit dem fail2ban einen Fehlversuch im Logfile erkennt. Das <HOST> ist ein spezieller Platzhalter, mit dem fail2ban IP-Adressen erkennt. Alternativ könnte man auch (?:::f{4,6}:)?(?P<host>\\S+) schreiben.
Diesen Filter können wir direkt testen
$ fail2ban-regex ~/app/log/development.log /etc/fail2ban/filter.d/app.conf
Running tests
=============
Use failregex filter file : app, basedir: /etc/fail2ban
Use log file : /home/dev/app/log/development.log
Use encoding : UTF-8
Results
=======
Failregex: 3 total
|- #) [# of hits] regular expression
| 1) [3] .* Login failed from host "<HOST>"
`-
Ignoreregex: 0 total
Date template hits:
|- [# of hits] date format
| [65] Year(?P<_sep>[-/.])Month(?P=_sep)Day 24hour:Minute:Second(?:,Microseconds)?
`-
Lines: 65 lines, 0 ignored, 3 matched, 62 missed [processed in 0.00 sec]
Missed line(s): too many to print. Use --print-all-missed to print all 62 lines
Da wir schon falsche Zugangsdaten eingegeben haben, sollte der Test ein paar Treffer finden.
Da der Filter noch nicht aktiv ist, schauen wir uns mal an, wie die iptables-Regeln aktuell aussehen:
$ sudo iptables -L
[sudo] Passwort für otrsvm:
Chain INPUT (policy ACCEPT)
target prot opt source destination
f2b-sshd tcp -- anywhere anywhere multiport dports ssh
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain f2b-sshd (1 references)
target prot opt source destination
RETURN all -- anywhere anywhere
Man sieht bei den Regeln für den eingehenden Datenverkert das Ziel f2b-sshd. Und weiter unten genauer aufgeführt was dieses Ziel bedeutet.
Wir müssen fail2ban jetzt so konfigurieren, dass es einen sogenannten Jail für unsere Anwendung gibt. Dazu fügen wir in der Datei /etc/fail2ban/jail.conf folgendes hinzu:
[app-name]
enabled = true
port = 3000
filter = app
logpath = /path/to/app/log/development.log
action = iptables[name=AppName, port=3000, protocol=tcp]
maxretry = 5
bantime = 60
Folgende Angaben werden hier gemacht:
- enabled = true heißt, dass dieses Jail aktiv ist
- filter = app bedeutet, dass der Filter app.conf genutzt wird
- logpath gibt den Pfad zu Logdatei an, die gefiltert werden soll
- Bei action gibt man an, was beim Erreichen der maximalen Funde gemacht werden soll. Hier wird ein iptables-Eintrag gemacht
- Unter maxretry gibt man die Anzahl der maximalen Funde an. Hier darf man maximal 5 Fehlversuche machen.
- bantime gibt die Zeit (in Sekunden) an, die eine IP-Adresse gebannt wird.
Jetzt versuchen wir uns wieder mehrfach anzumelden. Geben wir jetzt 5 mal die falschen Zugangsdaten, ist die Anwendung nicht mehr erreichbar:
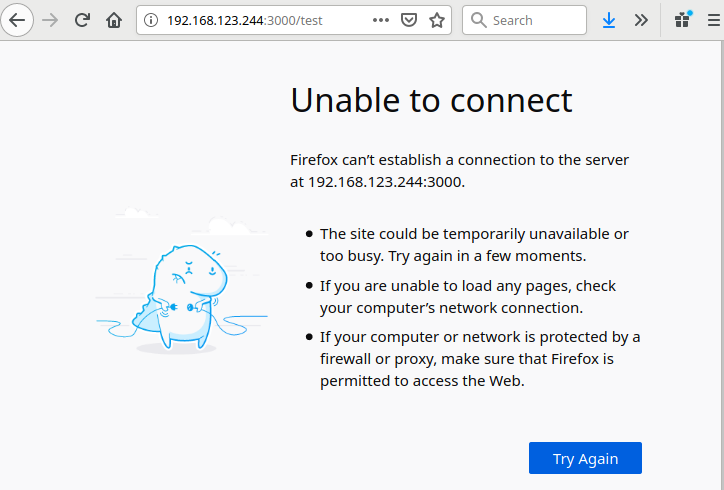
Im fail2ban.log ist jetzt folgendes zu finden:
2020-10-28 12:38:11,757 fail2ban.jail [472]: INFO Creating new jail 'app'
2020-10-28 12:38:11,757 fail2ban.jail [472]: INFO Jail 'app' uses pyinotify
2020-10-28 12:38:11,758 fail2ban.filter [472]: INFO Set jail log file encoding to UTF-8
2020-10-28 12:38:11,763 fail2ban.jail [472]: INFO Initiated 'pyinotify' backend
2020-10-28 12:38:11,818 fail2ban.actions [472]: INFO Set banTime = 60
2020-10-28 12:38:11,826 fail2ban.filter [472]: INFO Set maxRetry = 5
2020-10-28 12:38:11,829 fail2ban.filter [472]: INFO Set jail log file encoding to UTF-8
2020-10-28 12:38:11,894 fail2ban.filter [472]: INFO Added logfile = /home/dev/app/log/development.log
2020-10-28 12:38:12,173 fail2ban.filter [472]: INFO Set findtime = 600
2020-10-28 12:38:12,192 fail2ban.jail [472]: INFO Jail 'sshd' started
2020-10-28 12:38:12,203 fail2ban.jail [472]: INFO Jail 'app' started
2020-10-28 12:39:07,383 fail2ban.filter [472]: INFO [app] Ignore 127.0.0.1 by ip
2020-10-28 12:41:02,691 fail2ban.filter [472]: INFO [app] Found 192.168.123.1
2020-10-28 12:41:04,382 fail2ban.filter [472]: INFO [app] Found 192.168.123.1
2020-10-28 12:41:06,460 fail2ban.filter [472]: INFO [app] Found 192.168.123.1
2020-10-28 12:41:07,980 fail2ban.filter [472]: INFO [app] Found 192.168.123.1
2020-10-28 12:41:10,028 fail2ban.filter [472]: INFO [app] Found 192.168.123.1
2020-10-28 12:41:10,447 fail2ban.actions [472]: NOTICE [app] Ban 192.168.123.1
Wenn wir jetzt in die iptables-Regeln schauen, sehen wir eine Veränderung:
~$ sudo iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
f2b-AppName tcp -- anywhere anywhere tcp dpt:3000
f2b-sshd tcp -- anywhere anywhere multiport dports ssh
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain f2b-AppName (1 references)
target prot opt source destination
REJECT all -- 192.168.123.1 anywhere reject-with icmp-port-unreachable
RETURN all -- anywhere anywhere
Chain f2b-sshd (1 references)
target prot opt source destination
RETURN all -- anywhere anywhere
Beim Ziel f2b-AppName gibt es für die aufrufende IP jetzt einen REJECT-Eintrag. Durch die bantime=60-Angabe im Jail, wird der Eintrag nach 1 Minute aber wieder gelöscht.
Die Anwendung und der Filter sind auch im Gitlab-Repository zu finden.
Permalink: /2021-02-03-perl-anwendungen-fail2ban
User Story Mapping Teil 1
In der agilen Software-Entwicklung wird oft die formale Korrektheit von User Storys über ihren eigentlichen Zweck gestellt: Die Beteiligten erzählen einander Geschichten aus Anwendersicht. Während der Umsetzung der Software verlieren Beteiligte zudem oft den Blick »auf’s große Ganze«. Die Methode »User Story Mapping« möchte helfen, diese Probleme zu beheben und durch die enstehende Software das Leben der Anwender verbessern.
Problem 1: Nicht erzählte formal korrekte User Storys
User Storys sind in der agilen Entwicklung ein beliebtes Mittel, um aus Nutzersicht gewünschte Funktionalitäten umzusetzender Softwaredarzustellen.
Oftmals konzentrieren sich die Verfasser dieser User Storys auf die formale Korrektheit: Das Wer-Was-Warum wird mit der Formel »Als Rolle möchte ich eine Funktion ausführen, um damit folgenden Mehrwert zu schaffen« beschrieben.
Dabei sehen die Beteiligten die User Storys oft als Ergebnis (und damit Ende) der Konversation, das auf virtuelle oder echte Karten gebannt wird.
Die User Storys sollten aber vielmehr der Beginn laufender Unterhaltungen der an der Umsetzung beteiligten Personen sein.
Problem 2: Das Backlog als eindimensionale Sicht
Zur Planung der Umsetzung setzt der Product Owner in der Regel ein priorisiertes Backlog ein. Es ist eindimensional und gibt die Reihenfolge der Umsetzung vor. Diese Priorisierung von Storys reißt diese inhaltlich zusammen gehörenden Funktionalitäten zeitlich auseinander.
Die Beteiligten betrachten User Storys damit aus ihrem Kontext herausgelöst. Als Folge vermissen sie den Blick »auf’s große Ganze« und verlieren die Bedürfnisse des Benutzers aus den Augen.
Das User Story Mapping ist ein Werkzeug, um diese Probleme zu lösen und damit Software zu entwickeln, die die Probleme der Anwender löst.
Lösung: Die zweidimensionale Landkarte
Der Name des User Story Mappings deutet an, dass Storys auf einer Karte angeordnet werden. Diese Karte hat anders als das Backlog nicht nur eine Tiefe, sondern auch eine Breite.
Fachexperten, Entwickler und andere interessierte Parteien ermitteln die benötigte Funktionalität durch Erzählungen, wie Anwender handeln. Aus Sicht des Benutzers wird ein Ablauf erzählt.
Hierbei konzentrieren sie sich zunächst auf die Breite, um die Geschichte vom Anfang bis zum Ende zu erzählen. Der Erzählfluss wird dabei auf nebeneinander angeordneten Karten dargestellt. In anschließenden Diskussionen wird die Erzählung in die Tiefe ergänzt.
Die entstehenden Karten sind nur der Ausgangspunkt von Unterhaltungen: Sie werden laufend in die Hand genommen, ergänzt und bewegt.
Die dargestellte Erzählung ist ein beispielhafter Ablauf, der nur /eine/ mögliche Benutzung der Software darstellt. Die so entstandene Landkarte dient den Beteiligten als Hilfestellung und Orientierung während der Entwicklung.
Und wie erstellen wir nun eine solche Landkarte?
In diesem Artikel habe ich einen kurzen Überblick darüber gegeben, was das User Story Mapping ist und wofür es eingesetzt werden kann.
Im nächsten Teil einer kleinen Artikelreihe zeige ich, wie eine solche User Story Map aufgebaut werden kann und wie man damit Releases plant.
Weiterlesen
Permalink: /2021-01-28-user-story-mapping-teil1
Geodaten in Bildern und Videos können viel über Nutzer verraten
Am vorvergangenen Wochenende (9./10. Januar 2021) gab es relativ viel Wirbel um die Plattform Parler, die offensichtlich als Twitterersatz für hauptsächlich amerikanische Konservative
diente. Amazon Web Services (AWS) kündigte Parler alle Services, da dort jede Menge Hass verbreitet wurde. Bevor alles abgeschaltet war, wurden wohl alle öffentlich verfügbaren Daten über ein API heruntergeladen. Ein paar der Fehler, die bei dem API gemacht wurden, werde ich kurz in der Schulung im März erläutern.
In diesem Blogpost möchte ich auf einen Aspekt eingehen, der viel über Benutzer verraten kann: Metadaten bei Bildern und Videos. Bei den öffentlichen Bildern und Videos auf Parler waren in den Bildern noch alle Metadaten enthalten. So konnte der Twitternutzer kcimc ein Bild erstellen, auf der gut zu erkennen ist, woher die Parler-Nutzer kommen:
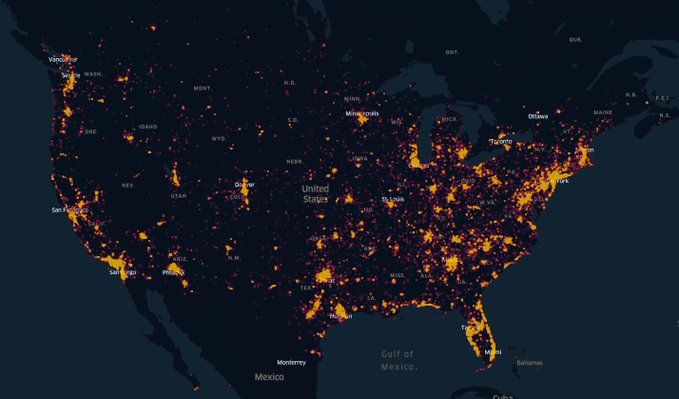
Quelle: https://twitter.com/kcimc/status/1348815246039805953
Sollte es nicht Sinn und Zweck der Veröffentlichung sein, den Besucher*innen die GPS-Daten zur Verfügung zu stellen, sollte man diese Metadaten entfernen.
Schauen wir uns aber erstmal an, welche Daten an einem Bild gespeichert sind. Dazu nehme ich ein Bild, dass ich mal in Frankfurt gemacht habe. Das Bild ist auch im Coderepository zu finden.
{kind=link}

Alle möglichen Daten – unter anderem die Geodaten, aber auch Daten zur verwendeten Kamera und deren Einstellungen für das Bild – finden sich in den sogenannten EXIF-Daten. EXIF steht hierbei für Exchangeable Image File Format
. Die Daten werden als Plain-Text in den Header des Bildes geschrieben. Es gibt sehr viele Programme, mit denen die Daten ausgelesen und geändert werden können, aber hier geht es mehr um die Serverseite.
Zur Bearbeitung der Metadaten mit Perl eignet sich das Modul Image::ExifTool. Das Auslesen der Daten damit sind nur wenige Zeilen Code:
use Data::Printer;
use File::Basename;
use Image::ExifTool;
my $image = $ARGV[0] || dirname(__FILE__) . '/20191106_171714.jpg';
my $exif = Image::ExifTool->new;
my $info = $exif->ImageInfo( $image );
p $info;
Aus den Informationen lässt sich viel herauslesen, z.B. die Kameraeinstellungen wie
Flash "Fired",
FlashpixVersion "0100",
FNumber 1.9,
FocalLength "3.7 mm",
FocalLengthIn35mmFormat "28 mm",
FocalLength35efl "3.7 mm (35 mm equivalent: 28.0 mm)",
ShutterSpeed "1/15",
ShutterSpeedValue "1/15",
Aber eben auch die GPS-Informationen:
GPSLatitude "50 deg 6' 41.10" N",
GPSLatitudeRef "North",
'GPSLatitude (1)' "50 deg 6' 41.10"",
GPSLongitude "8 deg 44' 6.90" E",
GPSLongitudeRef "East",
'GPSLongitude (1)' "8 deg 44' 6.90"",
GPSPosition "50 deg 6' 41.10" N, 8 deg 44' 6.90" E",
Und das Löschen ist damit genauso schnell erledigt:
use Data::Printer;
use File::Basename;
use Image::ExifTool;
my $image = dirname(__FILE__) . '/20191106_171714.jpg';
my $exif = Image::ExifTool->new;
my @tags = (
'GPSLatitude', 'GPSLatitudeRef', 'GPSLatitude (1)',
'GPSLongitude', 'GPSLongitudeRef', 'GPSLongitude (1)',
);
for my $tag ( @tags ) {
$exif->SetNewValue( $attr );
}
$exif->SaveNewValues();
$exif->WriteInfo( $image );
Nach der Instanziierung des ExifTools definieren wir einfach eine Liste der Tags, die wir löschen wollen. Wird bei SetNewValue nur der Name angegeben, wird das Tag gelöscht. Um alle Tags zu löschen, könnten wir auch einfach $exif->SaveNewValue('\*') aufrufen.
Wenn man als Benutzer*in ganz sicher sein möchte, dass die Geodaten nicht ungewollt preisgegeben werden, muss man entweder vor dem Hochladen/Posten diese Daten wie gezeigt entfernen oder gleich die Nutzung der Standortdaten durch die Kamera unterbinden. Nutzt man die Teilen
-Funktion bei der Foto-App auf Mobiltelefonen, werden die Geodaten bereits gelöscht.
Als Betreiber*in einer Seite, auf der Nutzer*innen Fotos hochladen können, sollte man sich überlegen, ob man einige der Daten nicht lieber entfernt. In den Metadaten können viele Datenschutzrelevante Informationen zu finden sein. Auf Dr. Datenschutz gibt es einen interessanten Artikel dazu: https://www.dr-datenschutz.de/metadaten-wer-wann-mit-wem-wie-lange/.
Allerdings ist zu beachten, dass in den EXIF-Daten auch Urherberdaten gespeichert sein können, die besser nicht gelöscht werden. Das musste auch Facebook 2016 erfahren...
Zusammenfassend lässt sich sagen, dass die EXIF-Daten für einige Zwecke sehr nützlich sind, aber auch ungewollt Daten preisgeben können. Man sollte sich also anschauen, was man mit Bildern und/oder Videos anfangen möchte und welche Informationen dafür notwendig sind.
Permalink: /2021-01-19-geodaten-bilder-videos-exif
Git-Hooks mit Perl
Git ist eine weit verbreitete Software zur Versionsverwaltung. Wir nutzen Git seit vielen Jahren, um unseren Perl-Code zu verwalten. Soll im Git-Workflow etwas erzwungen werden, kommen sogenannte Git-Hooks zum Einsatz.
Wenn Code committet oder zum Server ge*pusht* wird, werden diese Hooks ausgeführt. Das sind Skripte, die automatisch bei diesen Events ausgeführt werden. Eine Liste mit den ganzen Events ist im Git-Handbuch zu finden. Man unterscheidet die Hooks danach, ob sie auf dem Client oder auf dem Server ausgeführt werden.
Git ist bei den Hooks sehr flexibel und die Hooks können in allen möglichen Programmiersprachen umgesetzt werden – auch in Perl. Hier soll ein Beispiel gezeigt werden, wie ein solcher Hook aussehen kann. Ziel ist es, bei einem vorhandenen cpanfile die darin genannten Perl-Module zu prüfen, ob sie in CPAN::Audit genannt sind. Damit soll einfach sichergestellt werden, dass schon bei der Entwicklung auf Sicherheitslücken in eingesetzten Perl-Modulen hingewiesen wird.
Client-Hooks
Im ersten Schritt schreiben wir ein Skript, das auf dem Client ausgeführt wird. Die Hooks liegen im Ordner .git/hook. Dort erstellen wir eine Datei mit dem Namen des Events auf das wir reagieren wollen. In diesem Fall möchten wir die Prüfung nach jedem Commit machen. Daher erstellen wir die Datei post-commit und machen diese ausführbar.
In diesem Fall werden keine Paramter übergeben. Wir werten mit CPANfile::Parse::PPI die Datei cpanfile aus und prüfen dann die Module mittels CPAN::Audit:
#!/usr/bin/perl
use v5.24;
use strict;
use warnings;
use File::Basename;
use File::Spec;
use CPAN::Audit::DB;
use CPAN::Audit::Query;
use CPANfile::Parse::PPI;
my $basedir = File::Spec->catdir( dirname(__FILE__), '..','..');
my $file = File::Spec->catfile( $basedir, qw/cpanfile/ );
my $db = CPAN::Audit::DB->db;
my $query = CPAN::Audit::Query->new( db => $db );
my $cpanfile = CPANfile::Parse::PPI->new( $file );
MODULE:
for my $module ( $cpanfile->modules->@* ) {
my $distname = $db->{module2dist}->{$module->{name}};
next MODULE if !$distname;
my @advisories = $query->advisories_for( $distname, $module->{version} );
next MODULE if !@advisories;
print sprintf "There are advisories for %s %s\n", $module->{name}, $module->{version};
}
Angenommen wir haben folgendes cpanfile:
requires 'Mojolicious' => 8.42;
requires 'Archive::Zip' => 0;
Dann kommt bei einem Commit diese Meldung:

So kann schon während der Entwicklung sichergestellt werden, dass man auf Module aufmerksam gemacht wird, für die Sicherheitslücken bekannt sind.
Dieser Git-Hook ist ganz praktisch, hat aber – wie alle clientseitigen Hooks – das Problem, dass sie bei einem git clone nicht mitgeklont werden. Die Hooks müssen also auf anderem Wege verteilt werden. Und es ist nicht sichergestellt, dass alle Hooks in den Arbeitskopien auch tatsächlich angewendet werden.
Sollen also gewisse Richtlinien erzwungen werden, ist es notwendig die Hooks auf dem Server einzurichten – mit einem passenden Event.
Server-Hooks
Soll der gleiche Hook wie auf dem Server nach einem push ausgeführt werden, muss das Skript direkt auf dem Server abgelegt werden. Testen können wir das, indem ein neues Git-Repository erstellt wird:
mkdir TestRepository
cd TestRepository
git init --bare
Da wir das init mit dem Parameter --bare aufgerufen haben, werden in dem Repository keine Dateien mit Code zu finden sein. Die Verzeichnisstruktur ist auch eine andere. Hier haben wir direkt die Struktur, wie sie in der Arbeitskopie im Verzeichnis .git/ zu finden ist.
Der Hook von oben muss in das Verzeichnis hooks/ kopiert werden, aber mit einem neuen Namen: post-receive. Das ist das Event, das nach einem push ausgelöst wird. Es verhindert also nicht, dass die Entwickler*innen Code auf den Server schieben, aber man kann beliebige Meldungen ausgeben. Soll ein push erfolglos sein, wenn ein Modul mit Sicherheitslücken im cpanfile gelistet ist, müssen wir den Hook von oben als pre-receive speichern.
Eine weitere Änderung ist notwendig, da – wie oben geschrieben – keine Dateien mit Code im Repository zu finden sind. Inhalte der Dateien lassen sich mit git show auslesen, daher sieht hier der entsprechende Teil des Hooks folgendermaßen aus:
my @args = <>;
chomp @args;
my $branch = (split /\s+/, $args[0])[-1];
my $required = qx{git show $branch:cpanfile};
my $db = CPAN::Audit::DB->db;
my $query = CPAN::Audit::Query->new( db => $db );
my $cpanfile = CPANfile::Parse::PPI->new( \$required );
Dieser Hook bekommt die Parameter alter Commithash
, neuer Commithash
und Branch über STDIN. Hier wird also immer das cpanfile des Branchs ausgelesen, der zum Server geschickt wird.
Wird jetzt ein push der Änderungen gemacht, meldet sich der Server mit
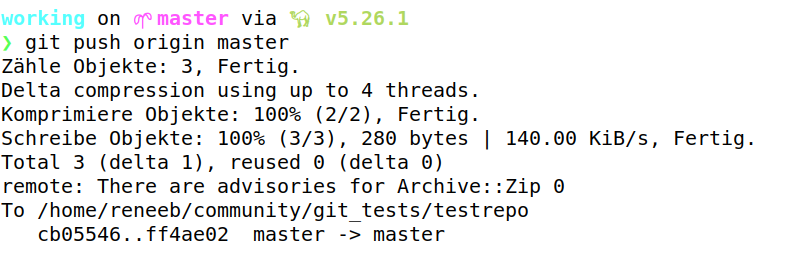
Das was bisher gezeigt wurde, gilt für git pur. Wir verwenden zur Verwaltung unserer Git-Repositories Gitlab. Neben den klassischen Git-Features nutzen wir hier vor allem die Continuous Integration Features.
Mit Gitlab sieht der Einsatz der serverseitigen Hooks etwas anders aus: Zuerst brauchen wir den Pfad zum (bereits existierenden) Repository. Dazu öffnen wir den Adminbereich und schauen uns das gewünschte Projekt/Repository an. Dort finden wir einen Eintrag Gitaly relative path: **@hashed/2c/69/2c69\[...\]bde.git**. Wir müssen auf dem Server in das Verzeichnis von Gitaly, z.B. /srv/gitlab/data/git-data/repositories/. Danach in das Verzeichnis wechseln, das im Adminbereich von Gitlab ausgelesen wurde.
Gitlab hat den oben gezeigten hooks-Ordner für etwas anderes benutzt. Aus diesem Grund dürfen die Hooks aber nicht in das Verzeichnis hooks/, sondern es muss ein Verzeichnis custom_hooks/ angelegt werden. Dort wird der Hook gespeichert. Der Rest bleibt wie gezeigt.
Quellen:
- https://www.digitalocean.com/community/tutorials/how-to-use-git-hooks-to-automate-development-and-deployment-tasks
- https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks
- https://medium.com/weekly-webtips/how-to-create-and-run-git-hooks-d395ec60d0d
- https://www.atlassian.com/git/tutorials/git-hooks
Permalink: /2021-01-06-git-hooks-mit-perl
Frohes Neues Jahr 2021
Das in vielerlei Hinsicht ungewöhnliche Jahr 2020 ist vorbei. Wir wünschen allen treuen und neuen Leser*innen unseres Blogs ein frohes neues Jahr. Wir hoffen, dass Sie gut durch das vergangene Jahr gekommen sind und dass 2021 besser wird.
Trotz der vielen Einschränkungen waren wir nicht untätig. Erstmal ein paar Daten:
- Wir haben 33 Releases von unseren CPAN-Modulen gemacht, darunter auch neue Module wie CPANfile::Parse::PPI und Markdown::Table
- Wir haben 40 Blogposts geschrieben
- 29 hier bei perl-academy.de
- 11 bei feature-addons.de
- Einen Artikel für die iX haben wir beigesteuert
- Wir haben sechs Schulungen (vier längerfristige Schulungen, zwei Sonderschulungen für den Deutschen Perl-/Raku-Workshop) konzipiert
- Wir waren beim Deutschen Perl-/Raku-Workshop 2020 in Erlangen
- Die ersten Addons wurden von der ((OTRS)) Community Edition auf OTOBO portiert
- Für einige freie Addons für die ((OTRS)) Community Edition gab es neue Versionen
- etliche Perl-Projekte wurden erfolgreich abgearbeitet
- und vieles mehr.
Wir möchten uns bei all unseren Kunden und Freunden bedanken. Nur mit Ihnen/Euch konnte das Jahr so erfolgreich abgeschlossen werden. Wir haben viele Ideen bekommen, die wir größtenteils umsetzen konnten.
Wir hoffen, dass der Deutsche Perl-/Raku-Workshop 2021 in Leipzig auch offline stattfinden kann. Dann werden auch wir unsere Schulungen wie geplant abhalten können. Auf dem Workshop werden wir wahrscheinlich ein paar Vorträge halten. Sobald die Organisatoren das Programm veröffentlichen werden wir uns auf diesem Kanal melden.
Auch für die geplanten anderen Schulungen planen wir zweigleisig – sowohl als Präsenzveranstaltung als auch in einer Online-Variante.
Wir wünschen Ihnen ein erfolgreiches Jahr 2021 und freuen uns auf ein spannendes Jahr.
Permalink: /2021-01-01-frohes-neues-jahr
CPAN-Updates November/Dezember 2020
Auch in den letzten beiden Monaten dieses Jahres waren wir nicht ganz untätig – teilweise mit Hilfe anderer Perl-Programmierer*innen.
In den folgenden Abschnitten stelle ich unsere neuen bzw. aktualisierten CPAN-Pakete vor:
CPANfile::Parse::PPI
Ein neues Modul, das ein statisches Parsen von *cpanfile*s ermöglicht. Ich habe schon in einem Blogpost erwähnt, warum wir nicht Module::CPANfile nutzen. Da ich noch mehre dieser Anwendungsfälle habe, habe ich ein Modul daraus gebaut: CPANfile::Parse::PPI.
use v5.24;
use CPANfile::Parse::PPI;
my $path = '/path/to/cpanfile';
my $cpanfile = CPANfile::Parse::PPI->new( $path );
# or
# my $cpanfile = CPANfile::Parse::PPI->new( \$content );
for my $module ( $cpanfile->modules->@* ) {
my $stage = "";
$stage = "on $module->{stage}" if $module->{stage};
say sprintf "%s is %s", $module->{name}, $module->{type};
}
Perl::Critic::RENEEB
In dieser Distribution habe ich zwei neue Regeln hinzugefügt:
Zum einen eine Regel, mit der die Nutzung von *List::Util*s first gefordert wird, wenn im Code ein grep genutzt aber nur das erste Element weiterverwendet wird, wie in diesem Beispiel:
my ($first_even) = grep{
$_ % 2 == 0
} @array;
Die zweite Regel fordert die Nutzung des postderef-Features. Das heißt, dass dieser Code
my @array = @{ $arrayref };
umgeschrieben werden soll als
my @array = $arrayref->@*;
Außerdem gab es kleine Änderungen an den Metadaten. Danke an Gabor Szabo für den Pull Request.
Mojolicious::Command::Author::generate::localplugin
Hier haben wir keine Arbeit aufwenden müssen, sondern durften auf die Fähigkeiten in der Perl-Community zurückgreifen. Andrew Fresh hat einen Pull Request eingereicht, der die Tests die dieses Modul für das generierte Plugin erstellt, lauffähig macht. Vielen Dank dafür!
Mojolicious::Plugin::FormFieldsFromJSON
Auch hier haben wir Pull Requests aus der Perl-Community erhalten:
- Interne POD-Links wurden korrigiert (Danke an Håkon Hægland)
- Ein paar Perl::Critic-Warnungen wurden korrigiert (Danke an Lubos Kolouch)
- Der Grund von FAIL-Reports der CPANTester wurde gefixt (Danke an Mohammad S Anwar)
OTRS::OPM::Maker::Command::sopm
Vor kurzem kam die erste Anforderung, eines unserer Module für OTOBO zu portieren. Da wir die Spezifikationsdateien unserer Erweiterungen generieren lassen, musste das Kommando entsprechend angepasst werden.
In der Metadaten-Datei (z.B. die für DashboardMyTickets) muss nur noch als Produkt OTOBO
angegeben werden, dann wird die .sopm-Datei richtig generiert.
OTRS::OPM::Parser
Das ist das zweite Modul, das für die Nutzung mit OTOBO ertüchtigt wurde. Mit der neuesten Version können Addons für OTOBO geparst werden. Das wurde notwendig, um einen OPAR-Klon für OTOBO aufsetzen zu können.
Zusätzlich wurde die Synopsis durch Håkon Hægland verbessert. Danke für den entsprechenden Pull Request.
Permalink: /2020-12-29-cpan-update-november-dezember