DBIx::Class::DeploymentHandler und lange Indexnamen
Wir nutzen in verschiedenen Projekte DBIx::Class als Abstraktionsschicht für die Datenbank. Das Schema der Datenbank entwickeln wir mit dem Tool MySQL-Workbench und die daraus resultierende Datei nutzen wir zur Code-Generierung wie in einem früheren Blogpost beschrieben.
Mit diesem generierten Code liefern wir auch die Änderung an der Datenbank aus. Dazu nutzen wir das Modul DBIx::Class::DeploymentHandler. Das funktioniert echt einfach:
use DBIx::Class::DeploymentHandler;
use Projekt::Schema; # DBIx::Class Schema
my $db = Projekt::Schema->connect(
'DBI:Pg:dbname=projekt_db;host=unser.projekt.host',
'db_user',
'db_password',
);
my $deployer = DBIx::Class::DeploymentHandler->new({
schema => $db,
script_directory => '/path/to/db_upgrades',
databases => ['Pg'],
force_overwrite => 1,
sql_translator_args => {
quote_identifiers => 1,
},
});
$deployer->prepare_install;
$deployer->install;
Wir instanziieren erst das Schema der Datenbank. Anschließend erzeugen wir ein Objekt um die Änderungen an der Datenbank auszurollen. Das Objekt benötigt noch den Pfad zu einem Verzeichnis in dem die Änderungsanweisungen gespeichert werden.
Bei prepare_install werden die YAML-Dateien in *db_upgrades *erstellt. In diesem YAML-Dateien ist eine Beschreibung der Datenbank: Welche Tabellen mit welchen Spalten gibt es. Weiterhin werden SQL-Dateien erstellt, die für die Datenbank passend die SQL-Befehle enthält.
Mit install werden dann die Änderungen in der Datenbank ausgerollt.
Und dabei sind wir auf ein Problem gestoßen, denn bei der Installation der Datenbank haben wir jede Menge Warnungen bekommen:
NOTICE: identifier "common_internal_workphase_activity_idx_common_internal_workphase_id" will be truncated to "common_internal_workphase_activity_idx_common_internal_workphas"
NOTICE: identifier "common_project_workphase_activity_idx_common_project_workphase_id" will be truncated to "common_project_workphase_activity_idx_common_project_workphase_"
NOTICE: identifier "contract_remuneration_engineering_idx_contract_remuneration_engineering_facilitygroup_id" will be truncated to "contract_remuneration_engineering_idx_contract_remuneration_eng"
NOTICE: identifier "contract_remuneration_facilitygroup_costgroup_idx_contract_remuneration_engineering_facilitygroup_id" will be truncated to "contract_remuneration_facilitygroup_costgroup_idx_contract_remu"
NOTICE: identifier "contract_remuneration_engineering_costgroup_idx_contract_remuneration_engineering_id" will be truncated to "contract_remuneration_engineering_costgroup_idx_contract_remune"
Ursache ist, dass in PostgreSQL die Identifier nicht länger als 63 Zeichen sein. Sind sie es doch, werden sie gekürzt. Jetzt haben uns zwei Fragen beschäftigt:
- Können wir längere Identifier erlauben?
- Wo kommen die langen Namen eigentlich her?
Die erste Frage war relativ schnell beantwortet: Ja, geht. Aber dazu muss man PostgreSQL selbst kompilieren, da die maximale Länge im Quellcode hinterlegt ist (Immerhin, mit Closed Source hätte man nicht mal die Chance die Änderungen vorzunehmen und die Software neu zu bauen 😉 ). Mehr dazu gibt es in der Postgres-Doku.
Die zweite Frage war etwas schwieriger zu beantworten. Wir haben diese Identifier nirgends definiert. Also mussten wir nachvollziehen, wie DBIx::Class::DeploymentHandler arbeitet.
Da der fehlerhafte Befehl in der SQL-Datei erstmals auftaucht, musste es beim Erstellen der SQL-Befehle passieren. Das SQL kommt von dem Modul SQL::Translator, und der Index wird in der Methode add_index aus SQL::Translator::Schema::Table erstellt.
Letztendlich war die Lösung relativ einfach: Wir überschreiben einfach genau diese Methode:
use SQL::Translator::Schema::Table;
use Digest::MD5 qw(md5_hex);
{
no warnings 'redefine';
my %indexes;
sub SQL::Translator::Schema::Table::add_index {
my $self = shift;
my $index_class = 'SQL::Translator::Schema::Index';
my $index;
if ( UNIVERSAL::isa( $_[0], $index_class ) ) {
$index = shift;
$index->table( $self );
}
else {
my %args = @_;
$args{'table'} = $self;
my $md5 = md5_hex( $args{$name} );
$args{name} = 'idx__' . $args{table} . '__' . $md5;
$index = $index_class->new( \%args ) or return
$self->error( $index_class->error );
}
foreach my $ex_index ($self->get_indices) {
return if ($ex_index->equals($index));
}
push @{ $self->_indices }, $index;
return $index;
}
}
Das ist das Schöne an Perl: Man kann Lösungen finden und anwenden ohne dass man den ursprünglichen Code anfasst. Hier nutzen wir die Möglichkeit, Subroutinen von jeder beliebigen Stelle aus für alle möglichen Namensräume zu definieren. Dazu muss nur der Vollqualifizierte
Name der Subroutine angegeben werden.
Das einzige was wir beachten müssen ist, dass wir das Modul SQL::Translator::Schema::Table laden bevor wir die Subroutine definieren, denn sonst würde die Methode aus dem Modul unsere Subroutine wieder überschreiben.
Solche Änderungen sollten aber immer das letzte Mittel sein, da das Überschreiben von Subroutinen an ganz anderen Stellen als sie eigentlich definiert wurden, zu längeren Debugging-Sitzungen führen kann wenn mal Fehler auftreten.
Permalink: /2020-09-07-dbix-class-deployment-handler
CPAN Updates - Juli 2020
Gregor und ich haben einige CPAN-Module. Wir wollen hier an dieser Stelle auch immer wieder auf wichtige Neuerungen in unseren Modulen aufmerksam machen.
In den letzten Wochen habe ich vermehrt an MySQL::Workbench::Parser
und MySQL::Workbench::DBIC gearbeitet um die Abbildung von
Views zu unterstützen.
In der Workbench können ganz einfach Views hinzugefügt werden. In der Konfiguration muss nur das SQL-Statement angegeben werden, wie der View aufgebaut werden soll:
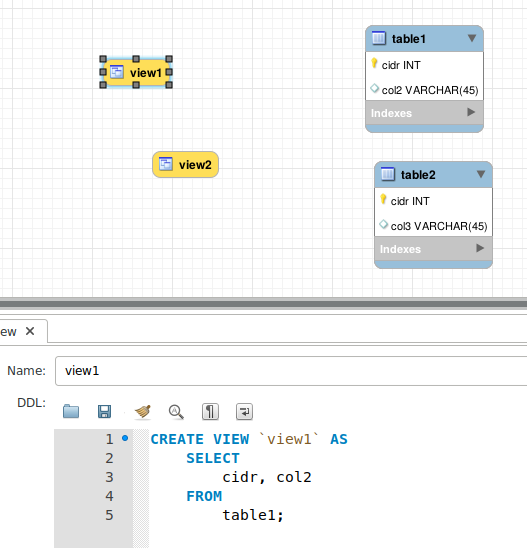
Der Vorteil der Workbench liegt darin, dass man mit Kunden und auch untereinander einfach die Workbench-Datei austauschen kann und man etwas grafisches vor Augen hat wenn man das Datenbankschema bespricht.
Wir nutzen die Workbench und die beiden Module in verschiedenen Projekten um
DBIx::Class-Klassen für den Zugriff auf die Datenbank zu erzeugen.
Mit einem kleinen Skript lässt sich der Perl-Code ganz einfach generieren:
use Mojo::File qw(curfile);
use MySQL::Workbench::DBIC;
my $foo = MySQL::Workbench::DBIC->new(
file => curfile->sibling('view.mwb')->to_string,
output_path => curfile->sibling('lib')->to_string,
namespace => 'Project::DB',
schema_name => 'Schema',
column_details => 1, # default 1
);
$foo->create_schema;
print sprintf "Version %s of DB created\n", $foo->version;
Damit werden dann folgende Dateien erstellt:
$ tree lib
lib
└── Project
└── DB
├── Schema
│ └── Result
│ ├── table1.pm
│ └── table2.pm
└── Schema.pm
table1.pm und table2.pm repräsentieren die entsprechenden Tabellen (siehe Abbildung weiter oben) und
mit den neuen Versionen von MySQL::Workbench::Parser und MySQL::Workbench::DBIC werden die Klassen
view1.pm und view2.pm erzeugt.
Die Klassen sehen wie folgt aus:
package Project::DB::Schema::Result::view1;
# ABSTRACT: Result class for view1
use strict;
use warnings;
use base qw(DBIx::Class);
our $VERSION = 0.05;
__PACKAGE__->load_components( qw/PK::Auto Core/ );
__PACKAGE__->table_class('DBIx::Class::ResultSource::View');
__PACKAGE__->table( 'view1' );
__PACKAGE__->result_source_instance->view_definition(
"CREATE VIEW `view1` AS
SELECT
cidr, col2
FROM
table1;"
);
__PACKAGE__->result_source_instance->deploy_depends_on(
["Project::DB::Schema::Result::table1"]
);
__PACKAGE__->add_columns(
cidr => {
data_type => 'INT',
is_numeric => 1,
},
col2 => {
data_type => 'VARCHAR',
is_nullable => 1,
size => 45,
},
);
Die entscheidenden Zeilen sind
__PACKAGE__->table_class('DBIx::Class::ResultSource::View');
__PACKAGE__->result_source_instance->view_definition(
"CREATE VIEW `view1` AS
SELECT
cidr, col2
FROM
table1;"
);
Als Klasse, wird hier DBIx::Class::ResultSource::View verwendet, das extra für Views
existiert. Anschließend erfolgt die SQL-Definition, wie sie in der Workbench eingetragen
wurde.
Hier wird absichtlich kein
__PACKAGE__->result_source_instance->is_virtual(1);
verwendet, weil die Views tatsächlich in der Datenbank angelegt werden sollen. Mit is_virtual(1)
wird der View rein virtuell behandelt.
Über diese Module habe ich übrigens im letzten Jahr auf dem Deutschen Perl-Workshop einen Vortrag gehalten:
Die Code-Beispiele liegen wieder im Gitlab-Repository.
Permalink: /2020-07-17-cpan-updates