Ein großer Klassenunterschied: class
Die (native) Objektorientierung in Perl hat viele Vorteile gegenüber anderen Programmiersprachen, aber auch viele Nachteile. Das ist mit ein Grund, warum Module wie Moose oder Moo so beliebt wurden. Schon seit längerer Zeit gab es Überlegungen, ein neues Objektmodell im Perl-Core umzusetzen – Stichwort: Cor(inna).
Mit Perl 5.38 ist es soweit, dass dieses neue Objektmodell umgesetzt wurde (vorerst im experimentellen Status)... Mit dem neuen Feature class gibt es die neuen Schlüsselwörter class, field und method. Hier eine kleine Beispielklasse:
use v5.38;
use experimental 'class';
class Schulung 0.01 {
field $date :param;
field $name :param(title);
field @persons;
method info {
say sprintf 'Die Schulung "%s" findet am %s statt', $name, $date;
}
method register ( $person ){
push @persons, $person;
say "Vielen Dank für die Anmeldung!";
$self->info;
}
method attendee_list {
say sprintf "Teilnehmer (%s):\n%s", $name, "-" x 45;
say join "\n", @persons;
}
}
Die ersten 3 Zeilen sind dafür da, dass wir die Features von Perl 5.38 und das neue Objektmodell nutzen können. Ab der 5. Zeile definieren wir die Klasse Schulung in der Version 0.01.
Mit field legen wir fest, welche Attribute die Objekte haben. Diese fields sind außerhalb der Klasse nicht sichtbar. Über das :param-Attribut wird festgelegt, welche Parameter dem Konstruktor (die Methode new gibt es automatisch) übergeben werden können bzw. müssen. Für diese Klasse wird ein neues Objekt so erzeugt:
my $schulung = Schulung->new(
date => '23.09.2023',
title => 'Neue Features in Perl 5.38',
);
Für das Objektattribut date müssen wir auch einen Wert zum Schlüssel date übergeben. Für das Attribt name wurde über :param(title) festgelegt, dass bei der Objekterzeugung der Schlüssel title genutzt werden muss.
Lässt man z.B. date weg, bekommt man eine passende Fehlermeldung:
Required parameter 'date' is missing for "Schulung" constructor at schulung.pl line 8.
Für optionale Objektattribute muss man einen Standardwert angeben, z.B.
field $date :param = localtime;
Für Methoden gibt es in dem neuen Objektmodell das Schlüsselwort method. Subroutinen können auch in den neuen Klassen verwendet werden. Der große Unterschied ist, dass in methoden die Variable $self (in der das Objekt steckt) automatisch vorhanden ist und dass methoden mit einem Objekt aufgerufen werden müssen. Wird das nicht gemacht, bekommt man die Fehlermeldung
Cannot invoke method "attendee_list" on a non-instance at Schulung.pm line 31.
Die Methodensignaturen funktionieren genauso wie die Subroutinensignaturen, die es schon länger im Perl-Core gibt und seit Perl 5.36 nicht mehr experimentell sind.
Ansonsten gibt es noch die Möglichkeit, einen ADJUST-Block zu nutzen, um die Parameter des Konstruktors anzupassen:
ADJUST {
$date = Time::Piece->strptime( $date, '%d.%m.%Y' )
if !( $date isa 'Time::Piece' );
}
Im ADJUST-Block gibt es auch automatisch die Instanzvariable $self. Wenn mehrere ADJUST-Blöcke definiert werden, werden diese in der Reihenfolge der Definition ausgeführt.
Das neue Objektmodell erlaubt nur Einfachvererbung, wobei die Klasse von der geerbt wird auch eine Klasse nach dem neuen Objektmodell sein muss und keine herkömmliche
Klasse sein darf. Für die Vererbung wird das Klassenattribut :isa verwendet:
class Schulung :isa( Event ) {
...
}
Käpt’n Hook und die Module
Einige Kernfunktionen in Perl können nur schwer überschrieben werden – jedenfalls für die meisten von uns. Eine dieser Funktionen ist require. Um das Verhalten solcher Funktionen zu verändern oder auf die Ausführung der Funktionen reagieren zu können, wurde in Perl 5.38 der Spezialhash %{^HOOK} eingeführt.
In diesem Hash werden Codereferenzen gespeichert. Der Schlüsselname wird zusammengesetzt aus dem Namen der Funktion, zwei Unterstrichen _ und der Phase wann diese Codereferenz ausgeführt wird (derzeit gibt es nur die zwei Phasen before und after).
Im Beispiel von require können also Codereferenzen zu den Schlüsseln require__before und require__after gespeichert werden.
Beide Hooks bekommen als einzigen Parameter den Dateinamen übergeben, dabei wird der Paketname in einen Pfad umgewandelt (MIME::Base64 wird dabei zu MIME/Base64.pm umgewandelt).
Bei der Verwendung ist es wichtig, dass die Hooks vor dem Einbinden weiterer Module gesetzt werden. Daher muss man die entsprechenden Hooks in einem BEGIN{}-Block definieren:
#!/usr/bin/perl
use v5.38;
use strict;
use warnings;
BEGIN {
%{^HOOK} = (
require__before => sub ($path) {
say "I try to require $path...";
},
require__after => sub ($path) {
if ( $INC{$path} ) {
# loading the module was successful
say "welcome to the app, $path!";
}
}
);
}
use Mojo::File;
say "done...";
require__before wird dabei aufgerufen, bevor %INC geprüft, @INC durchsucht, INC-Hooks aufgerufen werden. require__after wird unabhängig vom Erfolg aufgerufen, aus diesem Grund wird in dem Beispielcode auch der Eintrag in %INC geprüft. Der before-Hook wird in der Reihenfolge der require-Aufrufe ausgeführt, der after-Hook in umgekehrter Reihenfolge.
Diese Hooks können gut zum Debugging genutzt werden, wenn man wissen möchte, welche Module eingebunden werden und wer diese Module einbindet:
use v5.38;
my %modules;
use Data::Dumper;
BEGIN {
%{^HOOK} = (
require__before => sub ($path) {
my @info = caller(0);
$modules{$path}->{$info[0]}++;
},
);
}
use OPM::Validate;
use Mojo::File;
print Dumper \%modules;
say "done...";
Permalink: /2023-07-28-kaptan-hook-und-die-module
Arrays und Hashes in Scheibchen
Dieser Post gehört nicht zur Perl5.38-Serie
Die sozialen Medien haben mir den Blogpost von Packy Anderson über die Weekly Challenge #226 in die Zeitleiste gespült. Die Aufgabe 1 lautet
You are given a string and an array of indices of same length as string.
Write a script to return the string after re-arranging the indices in the correct order.
Example 1
Input: $string = 'lacelengh', @indices = (3,2,0,5,4,8,6,7,1) Output: 'challenge'Example 2
Input: $string = 'rulepark', @indices = (4,7,3,1,0,5,2,6) Output: 'perlraku'
Die Zahlen in dem Array @indices geben also an, wo die Buchstaben stehen sollen (beginnend mit der Position 0): das c ist der dritte Buchstabe in dem String. Schauen wir uns das dritte Element des Arrays an, so steht dort die 0. Also muss das c an der Position 0 im Ergebnis stehen usw.
Das hat in mir direkt Gedanken zu einem Thema ausgelöst, das vermutlich völlig unterschätzt ist: Slices.
Damit kann man aus Hashes und Arrays Teilstücke – eben Scheibchen – herausbekommen, ohne Schleifen oder ähnliches nutzen zu müssen. Bevor wir uns die Slices genauer anschauen, ein kurzer Ausflug in die sogenannten Sigils ($, @ und %):
Mit dem Sigil $ sagt man aus, dass ein einzelner Wert genutzt wird. Bei den Variablen trifft man das $ bei den Skalarvariablen an. In diesen wird genau ein Wert gespeichert: Eine Zahl, ein String, eine Referenz. Das Sigil @ bedeutet, dass es um mehrere Werte geht und das % zeigt an, dass es um eine Schlüssel-Wert-Zuordnung geht.
In der Aufgabe kann man diese Sigils auch gut erkennen:
$string = 'lacelengh';
@indices = (3,2,0,5,4,8,6,7,1)
In der Skalarvariablen wird ein String gespeichert und in dem Array mehrere Zahlen.
Möchten wir das 3. Element aus dem Array bekommen, möchten wir ja genau 1 Sache bekommen, also ändert sich das Sigil von @ zu $.
$drittes_element = $indices[2];
Da die Zählung des Index' bei 0 beginnt, ist der Index des dritten Elements die 2. Auch wenn wir 1em Element etwas zuweisen wollen, ändert sich das Sigil:
$indices[2] = 10;
Bei Hashes sieht es ähnlich aus:
%essen = (
morgens => 'Brot',
mittags => 'Falafel',
abends => 'Chips',
);
$abendessen = $essen{abends};
$essen{morgens} = 'Ei';
Das bedeutet, immer wenn man das $ sieht, geht es um genau 1 Sache. Die Datenscheibe ist also sehr dünn.
Soll die Datenscheibe etwas dicker sein, man also mehrere Werte haben möchte, dann kann man mit den anderen Sigils arbeiten. Sollen das 3. und das 5. Element aus dem Array ausgegeben werden, dann kann man das so machen:
say "@indices[2,4]";
Die Ausgabe das mit ist 0 4.
Genauso kann man diese Slices auch bei der Zuweisung verwenden:
@indices = (1,2,3,4);
@indices[1,3] = (5,10); # @indices = (1,5,3,10)
Dieses Verhalten kann man jetzt wunderbar für die Lösung der oben genannten Aufgabe aus der Weekly Challenge nutzen:
#!/usr/bin/perl
use v5.10;
my $string = 'rple';
my @indices = (2,0,3,1);
my @sorted_chars;
@sorted_chars[@indices] = split //, $string;
say @sorted_chars;
Da wir über use v5.10 automatisch auch strict aktivieren, müssen wir das Array @sorted_chars deklarieren.
Mit dem split in der nachfolgenden Zeile teilen wir den Ausgangsstring in die einzelnen Buchstaben auf. Und jetzt schauen wir mal kurz was die Zuweisung eingentlich aussagt:
@sorted_chars[2,0,3,1] = ('r','p','l','e');
Wenn wir die Indizes und die Buchstaben nach den Indizes sortiert hinschreiben würden, wäre das
@sorted_chars[0,1,2,3] = ('p','e','r','l');
Schön, oder?
Bei Hashes kann man auch mit Slices arbeiten: Wenn man die Werte zu mehreren Schlüsseln haben möchte. Was muss man dann machen?
Richtig, das Sigil ändert sich zu @, weil wir ja mehrere Werte haben wollen. Also bei dem Hash von oben:
@morgens_abends = @essen{'morgens','abends'};
# @morgens_abends = ('Brot','Chips');
@essen{'morgens','abends'} = ('Spiegelei','Brot');
# %essen = (
# morgens => 'Spiegelei',
# mittags => 'Falafel',
# abends => 'Brot',
# );
Und wenn man aus Arrays oder Hashes als Datenscheibe ein Schlüssel-Wert-Zuordnung haben möchte, dann muss man das Sigil % nutzen:
my @indices = (3,1,0,2);
my %map = %indices[1,3];
# %map = (
# 1 => 1,
# 3 => 2,
# );
my %essen = (
morgens => 'Brot',
mittags => 'Falafel',
abends => 'Chips',
);
my %morgens_abends = %essen{'morgens','abends'};
# {
# abends => "Chips",
# morgens => "Brot",
# }
Man sieht, dass man mit Slices eleganten Code schreiben kann und über die Sigils erhält man auch immer Informationen darüber, was als Ergebnis gewünscht ist.
Am Ende noch: Herzlichen Glückwunsch an Mohammad Sajid Anwar, Initiator der Weekly Challenge zur Auszeichnung mit dem White Camel Award. Du hast es verdient!
Permalink: /2023-07-28-arrays-und-hashes-in-scheibchen
Exportweltmeister: Perl
Viele Module stellen einfach Funktionen zur Verfügung, wie z.B. List::Util die Funktionen first, all, any und noch weitere. Diese kann man in seinen eigenen Code importieren (oder aus Sicht von List::Util dementsprechend exportieren).
Auch in eigenen Modulen kann man so einen Exportmechanismus sehr einfach bereitstellen. Dafür gibt es z.B. die Module Exporter und Exporter::Tiny. Wer es lieber selbst in die Hand nimmt, fügt in seinem Modul eine Funktion import ein.
In der Regel werden Module mit use Modulname; eingebunden. Diese Zeile Code ist im Prinzip das gleiche wie
BEGIN {
require Modulname;
Modulename->import();
}
Im Modul, das die Funktionen zur Verfügung stellt, könnte es so aussehen:
package ExportHello;
use v5.38;
use base 'Exporter';
our @EXPORT = qw(hello);
sub hello { say 'Hello World!' };
Damit wird bei einem use ExportHello die Funktion hello importiert. Das hat einen großen Nachteil: Der Namensraum wird zugemüllt
mit Funktionen, die evtl. gar nicht von anderem Code aufgerufen werden soll.
package ImportHello;
use ExportHello;
hello();
Das führt hello bereits beim Einbinden des ImportHello-Moduls aus. Wenn man das Modul jetzt verwendet:
$ perl -I. -MImportHello -e 1
Hello World!
Die Funktion hello kann aber auch über den Namensraum ImportHello aufgerufen werden:
$ perl -I. -MImportHello -e 'ImportHello->hello()'
Hello World!
Hello World!
Es sieht also so aus, als ob ImportHello die Funktion hello bereitstellt. Was aber gar nicht Sinn des use ExportHello war.
Mit Perl 5.38 ist es jetzt möglich, solche Exporte lexikalisch zu machen, so dass ImportHello zwar die Funktion hello nutzen kann, aber von außen
sieht man diese Funktion nicht.
Über das pragma builtin werden einige Funktionalitäten bereitgestellt wie z.B. in Bezug auf Booleans – und jetzt auch die Funktion export_lexically.
package ExportHello;
use v5.38;
use experimental 'builtin';
use builtin 'export_lexically';
export_lexically hello => sub { say 'Hello World!' };
Damit ist die Funktion hello nur noch in ImportHello nutzbar, aber nicht mehr von außen
:
$ perl -I. -MImportHello -e 'ImportHello->hello()'
Hello World!
Can't locate object method "hello" via package "ImportHello" at -e line 1
Nicht nur Funktionen sind exportierbar
Aber nicht nur Funktionen können so lexikalisch exportiert werden, sondern auch beliebige Variablen:
package ExportAll;
use v5.38;
use experimental 'builtin';
use builtin 'export_lexically';
my ($scalar, @array, %hash);
export_lexically
'$year' => \$scalar,
'@talks' => \@array,
'%info' => \%hash,
check => sub {
say "Year: $scalar, Talks: @array"
}
;
Die Variablen $scalar, @array und %hash werden unter anderem Namen exportiert. Der Code, der dieses Modul nutzt, hat dann die Variablen $year, @talks und %info sowie die Funktion check zur Verfügung. Wichtig bei der Definition ist die Verwendung der einfachen Anführungszeichen.
Wird das Modul ExportAll jetzt verwendet, können die Variablen und die Funktion verwendet werden:
use ExportAll;
$year = 2023;
@talks = qw(Perl_5.38 Playwright);
check();
In dem Skript werden die Variablennamen $year und @talks verwendet, obwohl die an keiner Stelle erstellt wurden. Im Modul ExportAll wird auf die Moduleigenen Variablen $scalar und @array zugegriffen.
Auch bei den Variablen gilt, dass diese lexikalisch sind und von außen
nicht darauf zugegriffen werden kann.
Permalink: /2023-07-24-exportweltmeister-perl
Der Smartmatch wird "bald" entfernt
... wobei bald
relativ ist. In Perl ist es die Regel, dass als deprecated markierte Dinge in zwei stabilen Versionen eine Warnung ausgeben und danach verschwinden. Da Smartmatch in Perl 5.38 als deprecated markiert wurde, wird es in 5.38 und 5.40 eine Warnung ausgeben und mit 5.42 verschwinden.
Das Smartmatch (und damit auch die Schlüsselwörter given und when) gelten als fehlgeschlagenes Experiment. Es wurde in der Version 5.10.0 mit guten Absichten eingeführt. Damit wurden so Aufgaben wie Ist das Element 'Academy' in dem Array enthalten?
etc. einfach lösbar. An sich ein toller Operator und für die einfachen Fälle hätte ich ihn gerne genutzt.
Der Smartmatch wurde aber als eierlegende Wollmilchsau geplant und wurde so zu einem Albtraum für die Sprachentwickler. Es gibt so viele Grenzfälle und so viele Begebenheiten, die nicht richtig definiert wurden und dadurch auch immer wieder Überraschungen für die Nutzer bereithalten. Wer etwas tiefer in das Thema einsteigen möchte, darf sich gerne mal die Mail-Threads fixing smartmatch just hard enough (and when, too) -...
und Deprecation of smartmatch
anschauen.
Es gibt durchaus Überlegungen, ein kleines Subset an Features mit einem neuen Operator in Perl einzubauen – wenn es soweit ist, wird es natürlich hier im Blog zu lesen sein ;-) .
Ansonsten kann ich nur das Modul Smart::Match empfehlen.
Eine kleine Änderung beim Pattern-Matching
In jedem stabilen Release gibt es auch eher unscheinbare Änderungen, die auf den ersten Blick vielleicht nicht erwähnenswert erscheinen. Auf den zweiten Blick sind sie aber meist wirklich nützlich. Eine solche kleine Änderung gibt es im Bereich der regulären Ausdrücke. Die Variable ${^LAST_SUCCESSFUL_PATTERN} wurde eingeführt.
Wer kennt leere reguläre Ausdrücke und weiß, was sie tun? Kurzes Quiz: Was ist die Ausgabe von:
use feature 'say';
my $string = 'Hello';
$string =~ m{.ll};
$string =~ m{abc};
for my $check ( qw/all abc/ ) {
say "$check: yes" if $check =~ m{};
}
Die Auflösung kommt gleich, also nicht gleich spicken, sondern überlegen. Folgende Antwortmöglichkeiten gebe ich zur Auswahl:
- Es gibt gar keine Ausgabe
all: yes abc: yes3.all: yes4.abc: yes
Der leere reguläre Ausdruck ist ein Spezialfall (außer bei split //, $string). Wird der leere reguläre Ausdruck verwendet, wird der letzte erfolgreiche Match betrachtet und das Muster von dem Match genutzt.
Gehen wir das der Reihe nach durch.
- Die Variable
$stringbekommt den String Hello zugewiesen - Der reguläre Ausdruck
.llmatcht (das ell) - Der reguläre Ausdruck
abcmatcht nicht.
Der letzte erfolgreiche Match ist also die Prüfung auf .ll. Damit wird bei dem leeren regulären Ausdruck genau dieses Muster genutzt. Und von den beiden Strings, die in der Schleife geprüft werden, matcht das Muster nur bei all. Also ist die Ausgabe:
all: yes
Man kann sich vorstellen, dass es nicht allzu viel Spaß macht, so einen Code zu debuggen. Man muss den Code durchgehen, prüfen welche regulären Ausdrücke so verwendet werden und wie die Eingabedaten aussehen, um dann irgendwie nachzuvollziehen, welcher Match tatsächlich erfolgreich war.
Mit der neuen Variablen ${^LAST_SUCCESSFUL_PATTERN} wird das Debugging einfacher. Wenn die Schleife so aussieht:
for my $check ( qw/all abc/ ) {
say "$check: yes (${^LAST_SUCCESSFUL_PATTERN})"
if $check =~ m{};
}
dann sieht die Ausgabe wie folgt aus:
all: yes ((?^:.ll))
Damit lässt sich viel schneller der Match finden, der zuletzt erfolgreich war.
Eine weitere Variation der Schleife:
for my $check ( qw/all abc/ ) {
my $new = $check =~ s//Perl-Academy/r;
say $new;
}
Hier wird der leere reguläre Ausdruck in einer Ersetzung genutzt. Wer weiß, wie der leere reguläre Ausdruck funktioniert, wird auch wissen, was die Ausgabe ist. Richtig, die Ausgabe ist:
Perl-Academy
abc
Auch hier hilft die Verwendung der neuen Variable dabei, besser wartbaren Code zu schreiben. Hier wird ganz ausdrücklich gesagt, dass das Muster des letzten erfolgreichen Matches genutzt wird (die Suche nach diesem Match kann weiterhin viel Spaß bedeuten).
for my $check ( qw/ all abc/ ) {
my $new = $check =~ s/${^LAST_SUCCESSFUL_PATTERN}/Perl-Academy/r;
say $new;
}
Permalink: /2023-07-12-eine-kleine-anderung-beim-pattern-matching
Änderungen bei Subroutinen-Signaturen
Mit Version 5.36 haben die Subroutinen-Signaturen ihren Status als Experiment verloren und gelten als stabil. Mit 5.38 kommt eine kleine Änderung. Ein Beispiel für Subroutinen-Signaturen:
use v5.38;
test();
test( 'GPW' );
test( undef );
sub test ( $name = 'World' ) {
say "Hello $name!";
}
In diesem Fall gibt es in der Signatur einen optionalen Parameter und wenn dieser leer ist, wird er mit dem Wert World gefüllt.
Führt man dieses kleine Skript aus, bekommt man diese Ausgabe:
Hello World!
Hello GPW!
Use of uninitialized value $name in concatenation (.) or string at signatures.pl line 11.
Hello !
Es macht also einen Unterschied, ob man keinen Parameter übergibt oder ein undef. In vielen Fällen stehen die Werte für die Parameter aber nicht fest in der Anwendung sondern kommen z.B. aus einer Datenbank.
use v5.38;
my $name = _get_name_from_db();
test( $name );
sub test ( $name = 'World' ) {
say "Hello $name!";
}
Was passiert jetzt wenn in der Datenbank kein Name steht. Was möchte man jetzt sehen? Die Warnung und ein einfaches Hello ! oder nicht doch ein Hello World!? Vermutlich letzteres. Bisher hätte man jetzt zwei Funktionsaufrufe implementieren müssen – einmal wenn $name einen Wert hat und einmal wenn kein Wert in der Variablen steht.
Mit den kleinen Änderungen an den Subroutinen-Signaturen ist das jetzt aber nicht mehr notwendig. Bei Defaultwerten können jetzt //= und ||= genutzt werden, also z.B.
use v5.38;
my $name = _get_name_from_db();
test( $name );
sub test ( $name //= 'World' ) {
say "Hello $name!";
}
Damit würde auch dann Hello World! erscheinen wenn kein Name in der Datenbank gespeichert ist.
Permalink: /2023-07-07-anderungen-bei-subroutinen-signaturen
Rückgabewert von Modulen
In den meisten Modulen findet man als letzte Code-Zeile:
1;
Es gibt aber auch andere Werte wie
"What???"42"200 OK"
domm hat CPAN nach diesen interessanten
Rückgabewerten durchsucht und eine Seite daraus gebaut: https://returnvalues.plix.at/
Warum gibt es diese Zeile(n) eigentlich? Wahrscheinlich haben die meisten schon eine Fehlermeldung wie
$ perl -I. -MPerl536 -E 1
Perl536.pm did not return a true value.
BEGIN failed--compilation aborted.
gesehen. Ursache ist, dass das Modul keinen wahren Wert zurückliefert. Wenn ein Programm mittels use oder require ein Modul einbindet, lädt Perl die Datei mit einer Variante des eval-Mechanismus. Liefert das keinen wahren Wert, denkt Perl, dass ein Fehler passiert ist.
Mit Perl 5.38 wird sich das ein wenig ändern:
Mit
package Perl538;
use v5.38;
# ... code ...
oder
package Perl538;
use feature "module_true";
# ... code ...
muss das Modul keinen wahren Wert mehr zurückliefern.
Permalink: /2023-07-05-rueckgabewert-von-modulen
Auf dem Weg zu Perl 5.38 - eine kleine Blogserie
An dieser Stelle spielt in den nächsten Tagen und Wochen die neue stabile Perl-Version 5.38 in einer Mini-Serie von kurzen Blogeinträgen eine wichtige Rolle. Die neue Version von Perl wird voraussichtlich in Kürze veröffentlicht, derzeit ist bereits der Release-Kandidat 2 auf CPAN zu finden. Um diese Themen wird es gehen:
- Namespace-Trenner
'nicht mehr erlaubt - Rückgabewerte von Modulen
- Änderungen bei Subroutinen-Signaturen
- Variablen und Subs lexikalisch exportieren
- Die neue Objektorientierung
Ein ganz leichter Einstieg ist das erste Thema ... Wer hat schonmal das ' als Trenner von Namensräumen genutzt? Ein ganz nettes Beispiel ist:
package Don't;
sub do_it { print "Don't do it\n" };
1;
So etwas sieht man wahrscheinlich eher selten in Code. Und viele Syntaxhighlighter können damit auch nicht ordentlich umgehen. Es eignet sich aber für sprachliche Schönheiten:
use Don't;
Don't->do_it;
Dieser Trenner ist ab 5.38 jedoch als deprecated markiert und wird in einer der nächsten Versionen komplett verschwinden. Dann muss der Code von oben wie folgt aussehen:
package Don::t;
sub do_it { ... }
1;
Über das Entfernen dieses Trennzeichens wurde seit mindestens 2009 diskutiert.
Permalink: /2023-07-01-auf-dem-weg-zu-perl-538-eine-kleine-blogserie
Distribution auf Dist::Zilla umstellen
In diesem Artikel zeige ich dir, wie du eine bestehende Distribution mit möglichst wenig Aufwand auf Dist::Zilla umstellen kannst.
Hauptteil
In einem vorherigen Artikel habe ich Dist::Zilla vorgestellt und beschrieben, dass diese Distribution dir beim Entwickeln einer CPAN-fähigen Distribution lästige Handarbeit abnimmt. Dadurch kannst du dich auf’s Wesentliche konzentrieren: Code schreiben.
Damit das in Dist::Zilla enthaltene Programm dzil die ehemals manuellen Schritte automatisieren kann, muss es minimal konfiguriert werden. Dafür muss eine Datei namens dist.ini in der bestehenden Distribution angelegt werden. Ein Beispiel zeige ich dir weiter unten.
Damit man die Vorteile von dzil aufwandsarm nutzen kann, muss die Distro den „Standard-Perl-Aufbau“ haben: Die Testprogramme liegen im Verzeichnis t, die Module im Verzeichnis lib, und ausführbare Programme in bin.
Dieser Aufbau wird empfohlen, da dzil plugin-basiert arbeitet; bei Abweichungen muss dann jeweils für die Plugins die Abweichung konfiguriert werden. Diesen Aufwand kann man sich sparen, wenn man dem Standard folgt.
Manchmal erwartet aber auch ein Plugin einfach einen fest verdrahteten Aufbau, an den man sich dann wohl oder übel halten muss (wenn man nicht den Code des Plugins ändern möchte).
Loslegen!
Um eine Distribution zu „dzilisieren“ ist gar nicht soviel notwendig.
Im ersten Schritt legst du eine einfache dist.ini an:
name = Deine-Distro
author = Dein Name <email@example.com>
license = Perl_5
copyright_holder = Dein Name <email@example.com>
copyright_year = 2022
version = 0.001
[@Basic]
Wenn deine bestehende Distro vom Perl-Standard abweichen sollte, dann empfehle ich dir, sie nun auf den Standard-Aufbau umzubauen.
Wichtigste Befehle ausprobieren
Dann kannst du auch schon die wichtigsten Befehle von dzil ausführen. Das sind meiner Meinung nach build (Paketieren der Distro), test (Ausführen der Testprogramme innerhalb dieser paketierten Distro) und zum Abschluss release (Distro auf CPAN veröffentlichen).
Wenn bei einem dieser Befehle etwas nicht funktioniert oder nicht deinen Erwartungen entspricht, dann gibt es grundsätzlich zwei mögliche Ursachen: Die Konfiguration passt noch nicht ganz (gerade zu Beginn ist das sehr wahrscheinlich) oder deine Distro entspricht nicht den Erwartungen der Plugins. Da hilft dann nur langsames Herantasten und vermutlich ein Anpassen der Konfiguration dist.ini.
Ein Beispiel: Beim Befehl build wird vermutlich zu Beginn die Versionsnummer noch nicht passen. Die Lösung ist einfach: Ändere den Eintrag in der Konfiguration.
Du kannst übrigens auch nach dem Umstieg auf Dist::Zilla mit prove weiter arbeiten, während du entwickelst. Den Befehl test sollte aber gelegentlich trotzdem schon ausführen, damit du feststellen kannst, ob die Tests nach dem Paketieren der Distro noch durchlaufen.
Noch ein Hinweis zu release: Bevor dieser Befehl erfolgreich ausgeführt werden kann, müssen die Zugangsdaten für PAUSE konfiguriert sein (wobei du das Passwort am besten nie in der Datei speicherst, sondern immer von Hand angibst). Du kannst also nicht versehentlich eine Distro auf CPAN veröffentlichen.
Konfiguration nach und nach ergänzen
Herzlichen Glückwunsch! Eigentlich hast du jetzt schon die Distro dzilisiert. Jetzt solltest du erst einmal den Umgang mit dzil üben und zur Gewohnheit werden lassen.
Dann kannst du nach und nach Plugins ergänzen und die Konfiguration dafür ergänzen.
Über das Plugin-System ist dzil sehr mächtig im Funktionsumfang. Um Anregungen zu bekommen, welche bisher manuellen Arbeitsschritte dir das Programm abnehmen kann, solltest du im Netz nach Konfigurationen anderer Autoren suchen.
Wenn du dann deine Konfiguration ergänzt, solltest du Vorsicht bei Reihenfolge walten lassen. Die Plugin-Reihenfolge ist wichtig, da die Plugins teilweise aufeinander aufbauen. Die Phasen im Ablauf von dzil sind wichtig; Plugins solltest du daher pro Phase gruppieren.
Ein guter Einstieg in die Ergänzung der Funktionalität sind sogenannte bundles, die mehrere Plugins bündeln. Ein sehr mächtiges bundle ist jenes namens „Starter“, das vom Autor in einer eigenen kleinen Blog-Serie vorgestellt wird.
Zusammenfassung
Das Programm dzil nimmt lästige Handarbeit ab bei der Entwicklung von CPAN-fähigen Perl-Distributionen. Um es aufwandsarm verwenden zu können, sollte die Distro den Perl-Standard-Aufbau haben.
Wenn du deine Distro auf die Arbeit mit dzil umstellst, dann solltest du mit einer einfachen Konfiguration anfangen und dabei falls nötig deine Distro standardisieren.
Anschließend kannst du dich dann durch Übung an den Umgang mit dzil gewöhnen und die Konfiguration nach und nach erweitern. Mit der Zeit automatisierst du dann ehemals lästige Handarbeit.
Wie erstellt man eine User Story Map?
Die Methode des User Story Mappings soll den am Prozess der Softwareerstellung beteiligten Personen helfen, für den Anwender hilfreiche Software zu erstellen und dabei den Überblick über das große Ganze zu behalten. Wie wird nun ein solches User Story Mapping durchgeführt?
Von der Theorie zur Praxis
Im ersten Teil dieser kleinen Artikelreihe habe ich beschrieben, wie die vorgestellte Methode dabei unterstützen möchte, nützliche Software zu erstellen. In diesem Artikel zeige ich, wie das Mapping praktisch durchgeführt wird. Dabei gehe ich auf die Erstellung der zweidimensionalen Landkarte ein und erläutere, wie Versionen damit geplant werden können.
Wie entsteht eine Landkarte von User Storys?
Beim User Story Mapping geht es darum, einander Geschichten aus Nutzersicht zu erzählen und diese in einem Erzählfluss auf Karten sinnvoll anzuordnen. Hierbei kommt es darauf an, wirklich von Angesicht zu Angesicht miteinander zu sprechen – schließlich geht es hier immer um eine »Story«. Das eigentliche Format einer Story ist hierbei zweitrangig. Es sollten jene Personen das User Story Mapping durchführen, die später auch an die Umsetzung beteiligt sind.
Damit die Beteiligten das große Ganze im Blick haben, konzentrieren sie sich bei der Erzählung zunächst darauf, die Geschichte in der Breite zu erzählen und erst später in die Tiefe der Details einzusteigen. Es geht im ersten Schritt darum, die ganze Geschichte zu erzählen und sich nicht in Details zu verlieren.
Im Laufe dieser ersten Erzählung ordnen die Teilnehmer die Karten ganz natürlich an: Die Erzählung beginnt links und sie schreitet nach rechts fort, bis sie abgeschlossen ist. Diese Darstellung erinnert an das wandelnde Skelett von Alistair Cockburn. Hier sehen die Teilnehmer nun das Rückgrat dieses Skeletts.
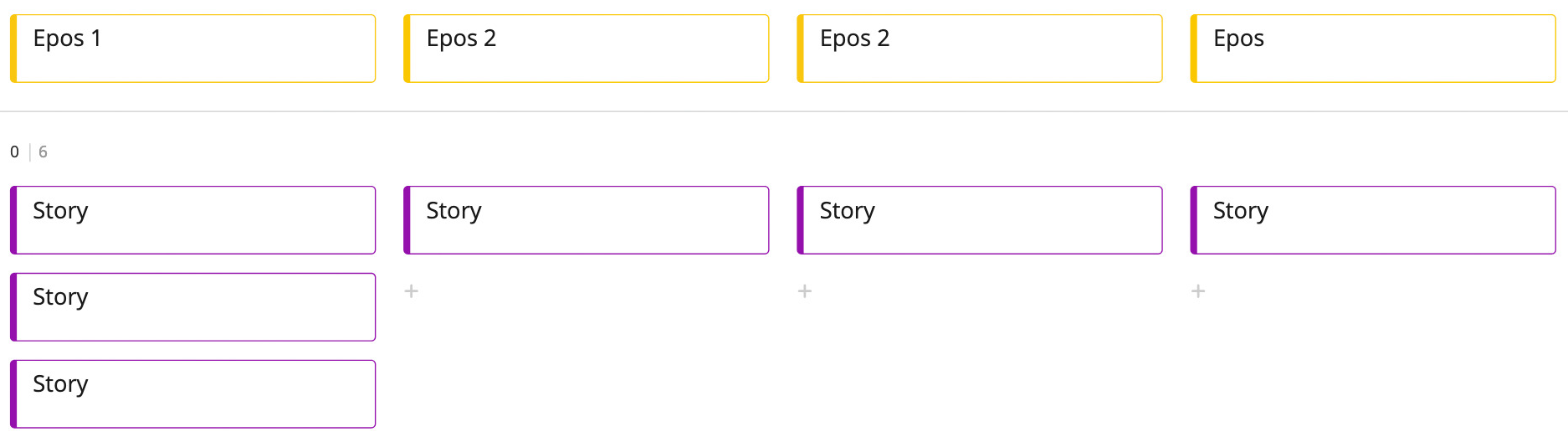
Alle Teilnehmer haben nun durch diesen ersten Schritt ein Verständnis davon, wie die Software von Anfang bis Ende benutzt wird und wie sie dem Anwender hilft. Jetzt wird die Erzählung mit detaillierteren User Storys ausgeschmückt, die unter das Rückgrat gehängt werden. Hier wird nun der Erzählfluss verlassen und die Teilnehmer ergänzen die Landkarte der User Storys an passender Stelle. So wächst die Landkarte der User Storys nach unten und alle Anwesenden können sehen, wie sehr sie in die Tiefe gehen.

Während der vielen Unterhaltungen, die nun stattfinden, fällt den Teilnehmern vielleicht auf, das bestimmte Storys in irgendeiner Form zusammengehören. Diese thematisch zusammengehörende Storys werden zu Aktivitäten zusammengefasst. Die Aktivitäten werden auf Karten über dem Rückgrat dargestellt. Sie gliedern die Erzählung in größere Abschnitte.
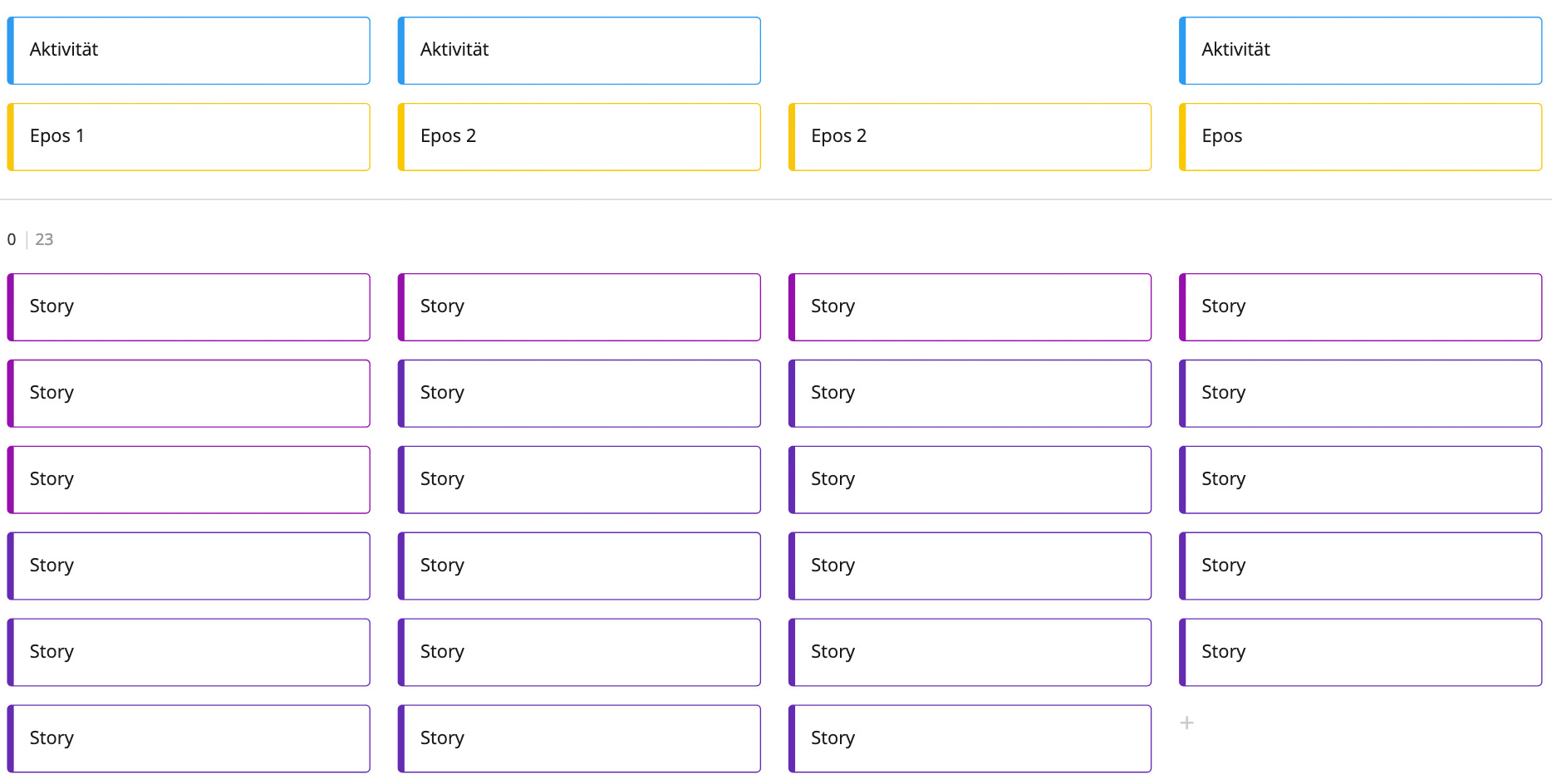
Die so entstandene Landkarte kann nun verwendet werden, um Versionen zu planen.
Auf zur Versionsplanung!
Ähnlich einem eindimensionalen Backlog können sich die Teilnehmer nun darüber unterhalten, welche Storys aus ihrer Sicht wichtig sind, um dem Nutzer beim Lösen seiner Probleme zu helfen. Diese Karten werden dann unter den jeweiligen Aktivitäten höher gehängt – Wichtiges hängt oben, weniger Wichtiges unten. Und Unwichtiges wird hoffentlich entfernt und gar nicht erst für die Umsetzung vorgesehen.
Um nun Versionen zu planen, ziehen die Teilnehmer horizontale Linien durch die Landkarte und teilen sie so in Versionsbänder auf.
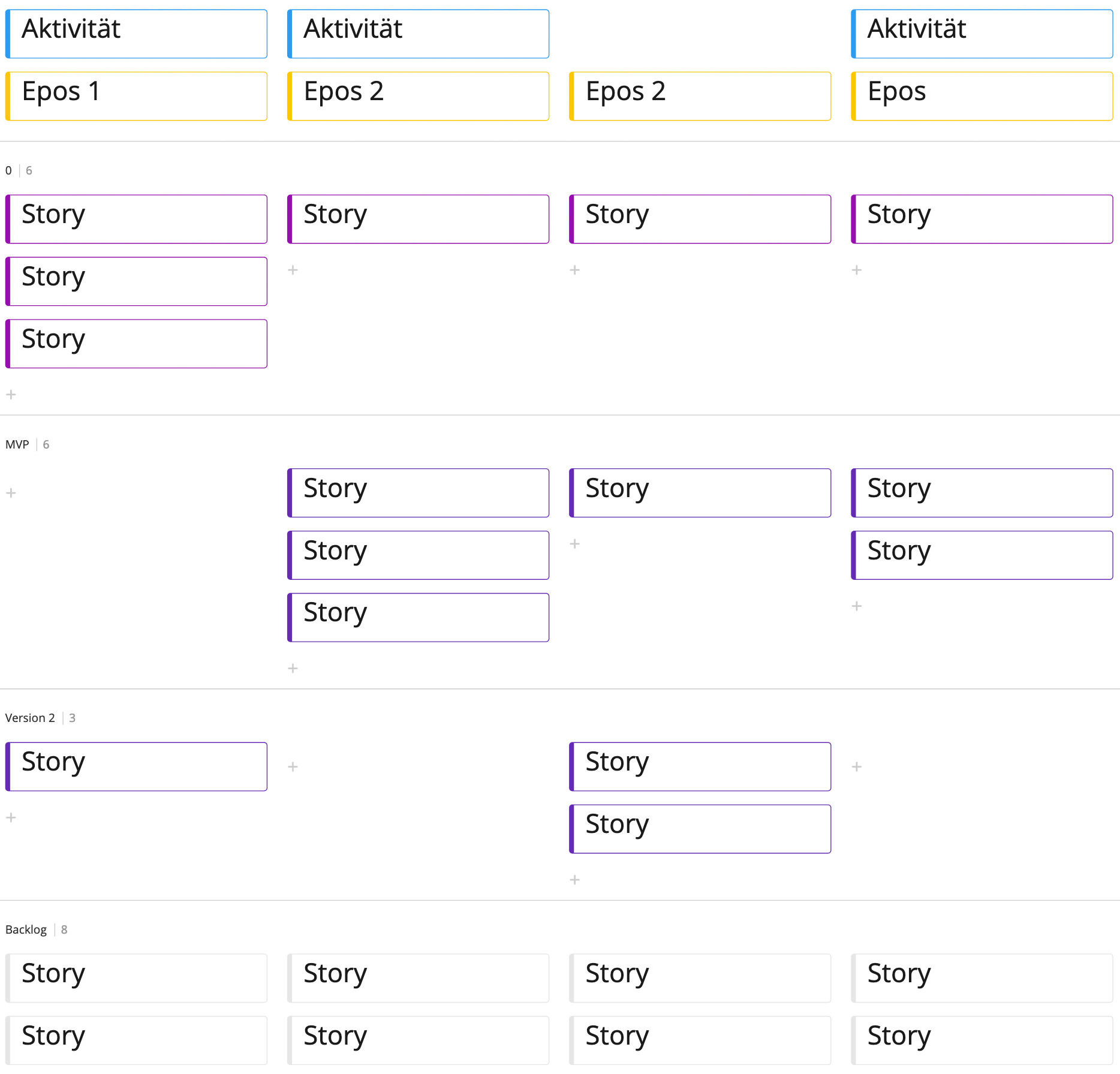
Damit dabei jeweils eine Version entsteht, die für den Anwender sinnvoll ist, ordnen die Teilnehmer die Karten in den Versionsbändern über den gesamten Erzählfluss sinnvoll an. Hierbei wird es mit Sicherheit angeregte Diskussionen darüber geben, welche Storys sinnvollerweise gemeinsam in einer Version umgesetzt werden, da sie einzeln nicht für den Anwender hilfreich sind.
Mit der Zeit entsteht so eine Landkarte von User Storys, die von Versionsbändern durchzogen ist, und sinnvoll geschnittene Versionen darstellt. Die Versionen ergeben aus Anwendersicht Sinn und die an der Umsetzung Beteiligten verstehen (zumindest jetzt) den Zusammenhang der einzelnen User Storys. Wenn diesen an der Umsetzung beteiligten Personen später etwas unklar ist, können sie stets auf diese Landkarte von User Storys zurückgreifen.
Zusammenfassung
Im ersten Teil der Artikelreihe haben wir die Methode »User Story Mapping« kennengelernt. Dieser Artikel erläutert, wie ein solches Mapping praktisch von beteiligten Personen durchgeführt wird. Dabei bin ich auch darauf eingegangen, wie mit dieser Methode sinnvoll Versionen geschnitten werden können. Im nächsten Teil dieser kleinen Serie werde ich »best practices« zum User Story Mapping beschreiben.