Wie erstellt man eine User Story Map?
Die Methode des User Story Mappings soll den am Prozess der Softwareerstellung beteiligten Personen helfen, für den Anwender hilfreiche Software zu erstellen und dabei den Überblick über das große Ganze zu behalten. Wie wird nun ein solches User Story Mapping durchgeführt?
Von der Theorie zur Praxis
Im ersten Teil dieser kleinen Artikelreihe habe ich beschrieben, wie die vorgestellte Methode dabei unterstützen möchte, nützliche Software zu erstellen. In diesem Artikel zeige ich, wie das Mapping praktisch durchgeführt wird. Dabei gehe ich auf die Erstellung der zweidimensionalen Landkarte ein und erläutere, wie Versionen damit geplant werden können.
Wie entsteht eine Landkarte von User Storys?
Beim User Story Mapping geht es darum, einander Geschichten aus Nutzersicht zu erzählen und diese in einem Erzählfluss auf Karten sinnvoll anzuordnen. Hierbei kommt es darauf an, wirklich von Angesicht zu Angesicht miteinander zu sprechen – schließlich geht es hier immer um eine »Story«. Das eigentliche Format einer Story ist hierbei zweitrangig. Es sollten jene Personen das User Story Mapping durchführen, die später auch an die Umsetzung beteiligt sind.
Damit die Beteiligten das große Ganze im Blick haben, konzentrieren sie sich bei der Erzählung zunächst darauf, die Geschichte in der Breite zu erzählen und erst später in die Tiefe der Details einzusteigen. Es geht im ersten Schritt darum, die ganze Geschichte zu erzählen und sich nicht in Details zu verlieren.
Im Laufe dieser ersten Erzählung ordnen die Teilnehmer die Karten ganz natürlich an: Die Erzählung beginnt links und sie schreitet nach rechts fort, bis sie abgeschlossen ist. Diese Darstellung erinnert an das wandelnde Skelett von Alistair Cockburn. Hier sehen die Teilnehmer nun das Rückgrat dieses Skeletts.
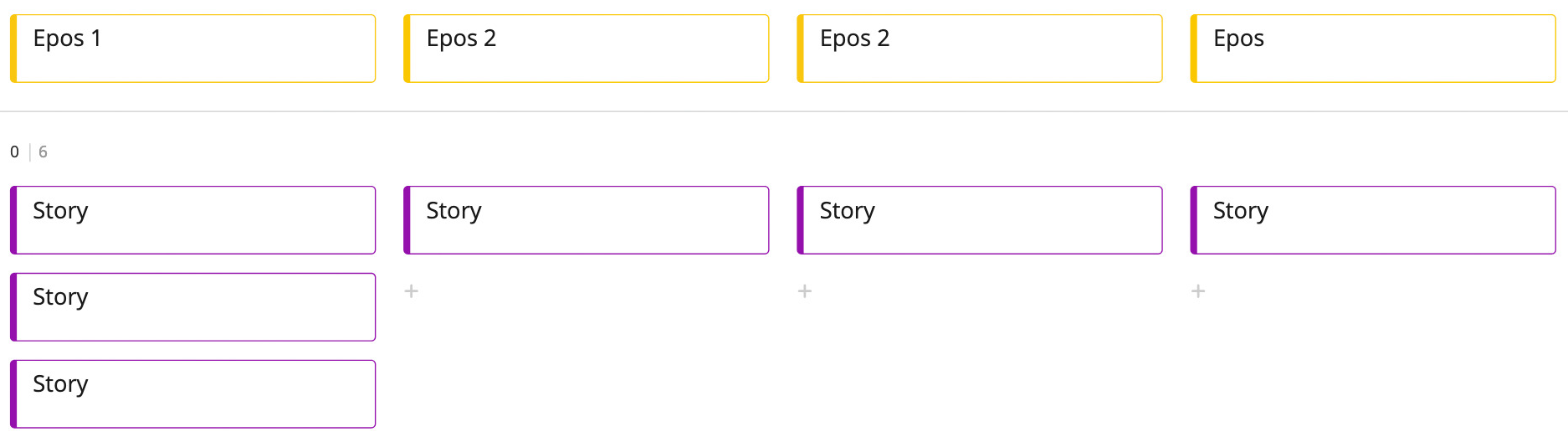
Alle Teilnehmer haben nun durch diesen ersten Schritt ein Verständnis davon, wie die Software von Anfang bis Ende benutzt wird und wie sie dem Anwender hilft. Jetzt wird die Erzählung mit detaillierteren User Storys ausgeschmückt, die unter das Rückgrat gehängt werden. Hier wird nun der Erzählfluss verlassen und die Teilnehmer ergänzen die Landkarte der User Storys an passender Stelle. So wächst die Landkarte der User Storys nach unten und alle Anwesenden können sehen, wie sehr sie in die Tiefe gehen.

Während der vielen Unterhaltungen, die nun stattfinden, fällt den Teilnehmern vielleicht auf, das bestimmte Storys in irgendeiner Form zusammengehören. Diese thematisch zusammengehörende Storys werden zu Aktivitäten zusammengefasst. Die Aktivitäten werden auf Karten über dem Rückgrat dargestellt. Sie gliedern die Erzählung in größere Abschnitte.
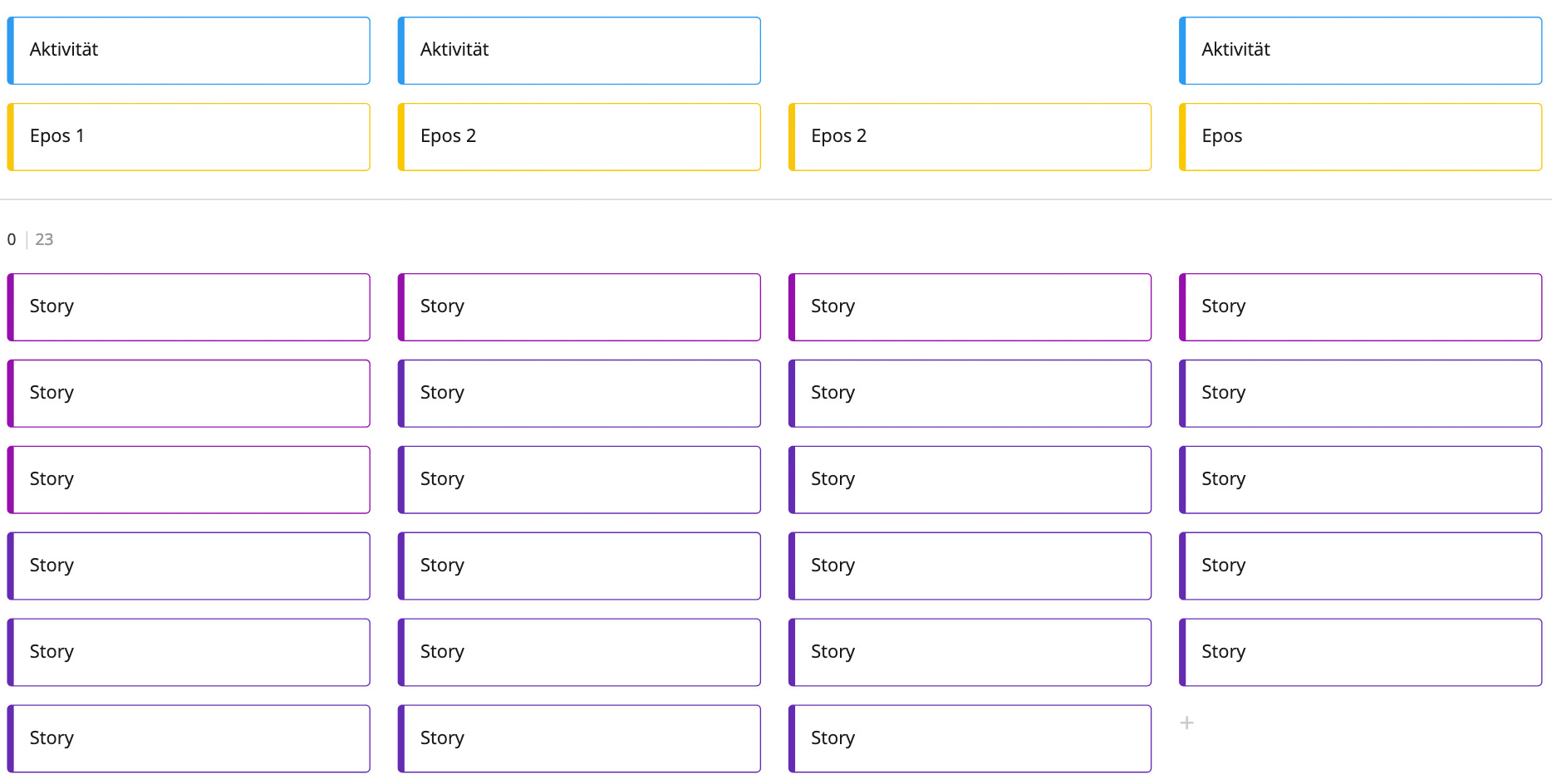
Die so entstandene Landkarte kann nun verwendet werden, um Versionen zu planen.
Auf zur Versionsplanung!
Ähnlich einem eindimensionalen Backlog können sich die Teilnehmer nun darüber unterhalten, welche Storys aus ihrer Sicht wichtig sind, um dem Nutzer beim Lösen seiner Probleme zu helfen. Diese Karten werden dann unter den jeweiligen Aktivitäten höher gehängt – Wichtiges hängt oben, weniger Wichtiges unten. Und Unwichtiges wird hoffentlich entfernt und gar nicht erst für die Umsetzung vorgesehen.
Um nun Versionen zu planen, ziehen die Teilnehmer horizontale Linien durch die Landkarte und teilen sie so in Versionsbänder auf.
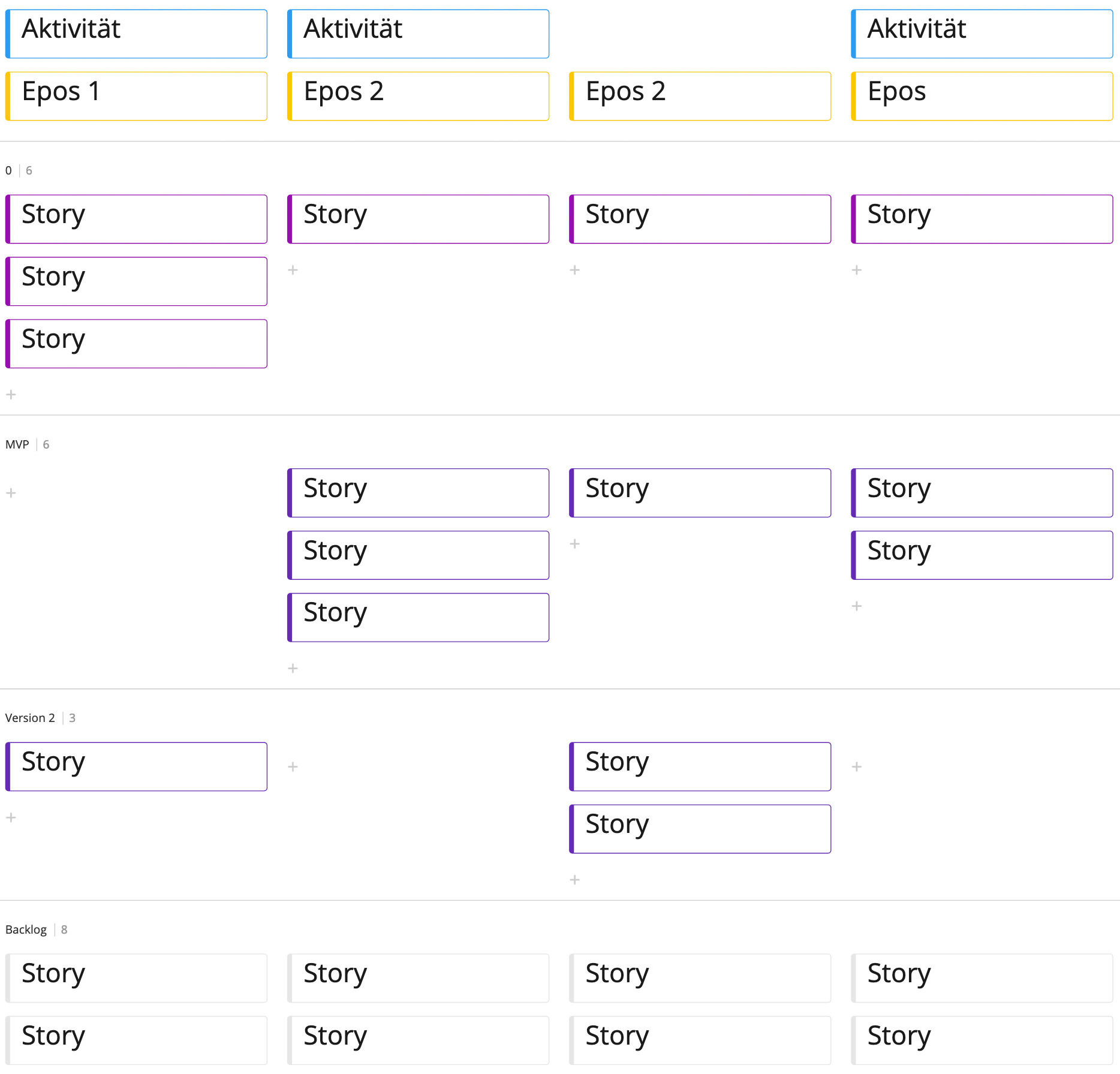
Damit dabei jeweils eine Version entsteht, die für den Anwender sinnvoll ist, ordnen die Teilnehmer die Karten in den Versionsbändern über den gesamten Erzählfluss sinnvoll an. Hierbei wird es mit Sicherheit angeregte Diskussionen darüber geben, welche Storys sinnvollerweise gemeinsam in einer Version umgesetzt werden, da sie einzeln nicht für den Anwender hilfreich sind.
Mit der Zeit entsteht so eine Landkarte von User Storys, die von Versionsbändern durchzogen ist, und sinnvoll geschnittene Versionen darstellt. Die Versionen ergeben aus Anwendersicht Sinn und die an der Umsetzung Beteiligten verstehen (zumindest jetzt) den Zusammenhang der einzelnen User Storys. Wenn diesen an der Umsetzung beteiligten Personen später etwas unklar ist, können sie stets auf diese Landkarte von User Storys zurückgreifen.
Zusammenfassung
Im ersten Teil der Artikelreihe haben wir die Methode »User Story Mapping« kennengelernt. Dieser Artikel erläutert, wie ein solches Mapping praktisch von beteiligten Personen durchgeführt wird. Dabei bin ich auch darauf eingegangen, wie mit dieser Methode sinnvoll Versionen geschnitten werden können. Im nächsten Teil dieser kleinen Serie werde ich »best practices« zum User Story Mapping beschreiben.
Spaß mit ICal-Dateien und Zeitzonen
Wir nutzen das Ticketsystem Znuny zur Kommunikation mit externen Personen wie zum Beispiel Interessenten und Kunden. Leider werden in Znuny ICal-Dateianhänge nicht als Termin erkannt und dementsprechend auch nicht angezeigt.
Aus diesem Grund haben wir eine neue Erweiterung für das System geschrieben, die uns alle Termine eines Tickets in einem extra Bereich anzeigen soll:
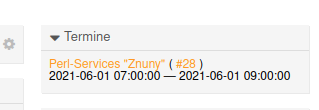
Um das zu erreichen, werden alle eingehenden Mails durch einen sogenannten Postmaster-Filter auf einen Dateianhang mit dem MIME-Type text/calendar geprüft. Ist ein solcher Anhang vorhanden, werden die folgenden Informationen aus dem Anhang gezogen:
- Datum
- Betreff
Dazu nehmen wir das Modul Data::ICal:
# alle Anhänge eines Tickets ermitteln
my $Attachments = $Param{GetParam}->{Attachment};
# ersten Anhang des Typs "text/calendar" ermitteln
my ($IcalAttachment) = grep {
$_->{MimeType} eq 'text/calendar';
} @{ $Attachments || [] };
return 1 if !$IcalAttachment;
# Objekt mit Daten aus Anhang instanziieren
my $Ical = Data::ICal->new(
data => $IcalAttachment->{Content},
);
# Daten aus letztem Event extrahieren
for my $Entry ( @{ $Ical->entries || [] } ) {
next if !$Entry->isa('Data::ICal::Entry::Event');
my $Description = $Entry->property('SUMMARY')->[0]->value;
my $Start = $Entry->property('DTSTART')->[0];
my $End = $Entry->property('DTEND')->[0];
}
Wenn wir uns das Datum näher anschauen und uns mit Data::Printer das Objekt ausgeben lassen, sehen wir eine Angabe zur Zeitzone. Je nachdem wie die Zeitzone angegeben ist, weiß ich nicht direkt den Zeitunterschied zu UTC, hier ein kleines Beispiel:
Data::ICal::Property {
Parents Class::Accessor
public methods (8) : as_string, decoded_value, encode, key, new, parameters, value, vcal10
private methods (5) : _fold, _parameters, _parameters_as_string, _quoted_parameter_values, _value_as_string
internals: {
_parameters {
TZID "W. Europe Standard Time"
},
key "dtstart",
value "20210601T080000",
vcal10 0
}
}
Das Datum möchte ich aber in UTC speichern, weil alle anderen Zeitangaben in der Datenbank ebenfalls in UTC gespeichert sind und damit das Datum je nach Zeitzone auch richtig angezeigt wird.
Ich muss also zunächst aus der Zeitzonenangabe den Zeitunterschied/Offset des Termins herausfinden. Anschließend muss ich das ICal-Datumsformat mit dem richtigen Offset parsen, um zum Schluss das richtige Datumsformat in UTC speichern zu können.
Es gibt eine Vielzahl von Perl-Modulen, die sich mit dem Thema Datum
befassen. Das einzige Perl-Modul jedoch, das ich für alle möglichen Varianten von Zeitzonen gefunden habe, ist Date::Manip beziehungsweise Date::Manip::TZ. Dieses nutze ich nun, um die Zeitzonenvariante Kontinent/Stadt (beispielsweise Europe/Berlin) zu bekommen.
# "richtiger" Name der Zeitzone
my $TimeZone;
{
# statt festem Wert dann $Start->parameters->{TZID}
local $ENV{TZ} = "W. Europe Standard Time";
$TimeZone = Date::Manip::TZ->new;
}
print $TimeZone->zone . "\n"; # Europe/Berlin
Mit dieser Variante können mehrere Module umgehen, unter anderem DateTime.
Zum Parsen des Datums nehme ich die das Modul Date::ICal:
my $Date = Date::ICal->new( ical => $Start->value );
Und für die Generierung des richtigen Formats nehme ich DateTime.
my $DateTime = DateTime->new(
year => $Date->year,
month => $Date->month,
day => $Date->day,
hour => $Date->hour,
minute => $Date->minute,
second => $Date->second,
time_zone => $TimeZone->zone,
);
# Das ist dann automatisch UTC
my $Formatted = $DateTime->ymd . ' ' . $DateTime->hms;
So bekomme ich aus einem beliebigen Datum in ICal-Dateien mit einer beliebigen Zeitzonenangabe ein Datum, das in der Zeitzone UTC angegeben ist – es ist damit in dem Format angegeben, das für den Datenbankeintrag notwendig ist.
cpanfile – Teil 1
Ein cpanfile ist eine Datei, die Abhängigkeiten von Anwendungen und Modulen beschreibt. Diese Dateien sind in der Perl-Welt nichts neues (sie gibt es seit über 8 Jahren) und sie sind eine sehr gute Möglichkeit, die Installation von Abhängigkeiten zu vereinfachen.
Die Nutzung einer solchen Datei eignet sich für folgende Szenarien:
- Ein Projekt soll direkt aus einem Repository heraus installiert werden.
- Neue Entwickler für das Projekt sollen schnell eine eigene Entwicklungsumgebung aufbauen können.
- Es soll immer eine reproduzierbare Umgebung aufgebaut werden können (es sollen immer die gleichen Versionen der Abhängigkeiten genutzt werden).
- und vermutlich noch viele weitere ...
Integration in Modulinstaller
cpanm kann die Abhängigkeiten aus einem cpanfile auslesen und diese installieren.
cpanm --installdeps .
liest die Datei namens cpanfile im aktuellen Verzeichnis aus.
Die nachfolgenden Abschnitten beschreiben die grundsätzlichen Möglichkeiten innerhalb des cpanfiles. Der nächste Artikel über cpanfiles wird noch weitergehen.
Standardabhängigkeiten werden einfach mit requires angegeben:
requires 'Mojolicious';
In diesem Fall wird einfach nur erwartet, dass irgendeine Version von Mojolicious installiert ist. Viele Module ändern ihr API, so dass man eine Mindestversion angeben sollte. Bei Mojolicious wurde z.B. mit Version 8.0 die Methode chmod in Mojo::File eingeführt. Benötigt die Anwendung diese Methode, muss sich das im cpanfile widerspiegeln:
requires 'Mojolicious' => 8;
Sollte eine Methode in 9.0 wieder abgeschafft werden und sie wird weiter verwendet, dann kann man auch einen Bereich angeben:
requires 'Mojolicious' => '>=8,<9';
Enthält eine Version der Abhängigkeit einen Bug, kann man diese Version explizit ausschließen:
requires 'Mojolicious' => '>8, != 8.12';
Diese Bedingungen sind mit und verknüpft.
In vielen Fällen werden für die Entwicklung der Anwendung oder des Moduls extra Abhängigkeiten benötigt. Wird die Anwendung ausgerollt oder das Modul installiert, sollen diese Abhängigkeiten nicht installiert werden.
Deshalb können sogenannte Phasen genutzt werden. Die oben gezeigten Beispiele gelten für die Phase runtime. Das ist die Standardphase und muss nicht extra angegeben werden. Gelten Abhängigkeiten nur für die Entwicklung, ist die Phase develop zu wählen. Abhängigkeiten, die für die Tests nötig sind, müssen für die Phase test installiert werden.
on 'develop' => sub {
requires 'Dist::Zilla' => 0.1;
};
on 'test' => sub {
requires 'Test::BDD::Cucumber' => 2;
};
Hier wird mit on bestimmt, dass die Phase sich ändert und in einer Subroutinen-Referenz werden dann die requires aufgelistet. Module::CPANfile kennt als Phasen runtime, develop, test und configure.
Die Installation mit cpanm über cpanm --installdeps . installiert nur die Module für die runtime und test. Sollen die Abhängigkeiten anderer Phasen installiert werden, muss das mit --with-<phase>, also z.B.
cpanm --with-develop --installdeps .
Soweit die Basisinformationen zu cpanfiles. Sie sind ein empfehlenswertes Werkzeug und mit den hier gezeigten Möglichkeiten kommt man in den allermeisten Fällen aus.
Permalink: /2022-06-29-cpanfile-a-teil-1
Einführung in Dist::Zilla
Eine Perl-Distribution besteht neben dem eigentlichen Code auch aus Dateien und Code, um die Distribution über CPAN zur Verfügung zu stellen. Das manuelle Erstellen dieser Dateien hält vom Entwickeln ab und wird schnell lästig. Dist::Zilla automatisiert diese Vorgänge. In diesem Artikel gebe ich einen Überblick über den Zweck von Dist::Zilla und zeige einen Einstieg in dessen Verwendung.
Das Problem: Langsam durch Handarbeit
CPAN ist der Ort, an dem Perl-Distributionen liegen. Damit Distributionen über CPAN bereitgestellt und von dort installiert werden können, muss ihr Inhalt und ihre Form einigen Anforderungen genügen. Diese Anforderungen können Autoren durch Handarbeit erfüllen.
Diese Handarbeit ist allerdings lästig und hält von der Hauptaufgabe ab: Code schreiben! Dist::Zilla ist eine Distribution, die das Werkzeug dzil bereitstellt, mit dem diese Handarbeit automatisiert werden kann. Dadurch werden Autoren schneller und als angenehme Nebenwirkung vereinheitlichen sie ihre Distributionen.
Die Notwendigkeit von Infrastruktur-Code
Perl-Distributionen sind im Kern ein Archiv von Dateien mit bestimmten Aufbau. Nur ein Teil dieses Archivs ist der eigentliche Code. Viele andere Dateien davon bilden nur die Infrastruktur, damit die Distribution auf CPAN bereitgestellt und von dort geladen werden kann; daher sind diese Dateien grundsätzlich notwendig. Leider ist es jedoch so, dass sie nicht nur einmal erstellt, sondern teilweise vor jedem erneuten Release geändert werden müssen.
Automatisierung hilft
Dist::Zilla nimmt dem Autor einer Distribution die Erstellung und Pflege dieser Dateien durch Automatisierung ab. Im Ergebnis muss dann (fast) nur noch der eigentliche Code geschrieben werden. Die Einschränkung betrifft die Konfiguration von dzil, die in der Datei dist.ini getroffen wird.
In dieser Konfiguration werden Metadaten und weitere Informationen untergebracht. Die Funktionsweise von Dist::Zilla kann der Autor über Plugins erweitern; die Plugins werden ebenfalls in dieser Datei konfiguriert.
Das Tool dzil
Das Werkzeug dzil bietet viele Kommandos, die durch den Aufruf von dzil angezeigt werden:
$ dzil
dzil <command> [-?hIVv] [long options...]
-v --verbose log additional output
-V STR... --verbose-plugin STR... log additional output from some
plugins only
-I STR... --lib-inc STR... additional @INC dirs
-? -h --help show help
Available commands:
commands: list the application's commands
help: display a command's help screen
add: add modules to an existing dist
authordeps: list your distribution's author dependencies
build: build your dist
clean: clean up after build, test, or install
cover: code coverage metrics for your distribution
install: install your dist
listdeps: print your distribution's prerequisites
new: mint a new dist
nop: do nothing: initialize dzil, then exit
perltidy: perltidy your dist
regenerate: write release staging contents into source tree
release: release your dist
run: run stuff in a dir where your dist is built
setup: set up a basic global config file
smoke: smoke your dist
test: test your dist
xtest: run xt tests for your dist
Für den Einstieg sind folgende drei Kommandos wichtig: build, test und release.
- Durch den Aufruf von
dzil builderstellt der Autor die Distribution anhand der Konfigurationdist.ini. - Mit
dzil testerstellt der Autor die Distribution und lässt darin die Tests ablaufen. - Schließlich kann der Autor die Distribution mit
dzil releaseauf CPAN veröffentlichen.
Zusammenfassung
In diesem Artikel habe ich einen kurzen Überblick über Dist::Zilla gegeben und die Möglichkeiten aufgezeigt. In den nächsten Teilen dieser Artikelserie werde ich auf die einzelnen Aspekte näher eingehen. Wenn du neugierig geworden bist und schon selbst ein bisschen durch das vorhandene Material stöbern möchtest, empfehle ich dir folgende Seiten:
- Die Homepage von
Dist::Zilla - Dist::Zilla auf MetaCPAN
- Ein Walk-Through durch eine echte
dist.ini
Permalink: /2022-06-08-einfa14hrung-in-distzilla
Auf dem Weg zu Perl 5.36 – gesammelte Werke
Zum Abschluss der kleinen Blogpost-Serie ein Artikel der noch ein paar Änderungen aufsammelt, die nicht in die anderen Artikel gepasst haben.
Oktalzahlen
Fangen wir mit einer Kleinigkeit an: Es gibt eine neue (zusätzliche) Syntax um Oktalzahlen in Perl-Code zu schreiben:
my $file_permissions = 0o755;
chmod $file_permissions, '/tmp/test.pl';
say sprintf "%d", $file_permissions; # 493
Für die Verwendung von Oktalzahlen gibt es mehrere Gründe. Bisher konnte man Oktalzahlen einfach mit 0
beginnen, also
my $file_permissions = 0755;
chmod $file_permissions, '/tmp/test.pl';
say sprintf "%d", $file_permissions; # 493
Das hat aber einen großen Nachteil: Gerade für Perl-Einsteiger ist nicht gleich erkennbar dass das eine Oktalzahl ist. Nicht nur einmal habe ich solchen Code gesehen:
my %hash = (
001 => 'eins',
010 => 'zehn',
100 => 'hundert',
);
Hier sollten in der Regel die führenden Nullen einfach zur Formatierung der Schlüssel verwendet werden. Aber was liefert ein
say "$_ => $hash{$_}" for sort keys %hash;
Etwas anderes als manche vielleicht vermuten würden:
1 => eins
100 => hundert
8 => zehn
Ups.
Die 0o... Schreibweise fügt sich auch besser in die bestehende Syntax für Hexadezimal- und Binärzahlen ein:
my $hex = 0xdeadaffe;
my $bin = 0b100;
Mehrere Laufvariablen in einer for-Schleife
Das nächste Thema ist ein ganz Kleines, aber eines auf das ich mich richtig freue: Es wird möglich sein, bei einer Iteration in einer for-Schleife mehr als nur ein Element aus einer Liste zu holen. Eine Standard-*for*-Schleife:
my @numbers = ( 1 .. 16 );
for my $nr ( @numbers ) {
say "$nr";
}
Die Aufgabe ist jetzt, diese Liste in vier Reihen zu je vier Zahlen auszugeben. Also nimmt man eine Laufvariable und bricht die Zeile nach jeweils 4 Elementen selbst um:
my @numbers = ( 1 .. 16 );
my $cnt = 1;
for my $nr ( @numbers ) {
print "$nr ";
print "\n" if $cnt++ % 4 == 0;
}
Einfacher geht das jetzt in Perl 5.36:
my @numbers = ( 1 .. 16 );
for my ($first, $second, $third, $fourth) ( @numbers ) {
say "$first $second $third $fourth";
}
Das Feature ist aber noch als experimentell markiert. Hier jetzt aber mal die Aufforderung: Nutzt auch experimentelle Features - auch in produktivem Code. Experimentell heißt nicht, dass man es nicht nutzen soll, sondern dass sich an der Implementierung ein paar Sachen ändern können. In vielen Fällen verlässt das Feature aber unverändert oder nur mit minimal Änderungen den experimentellen Status. Eine schöne Übersicht über die Experimente gibt es übrigens in der perlexperiment-Dokumentation.
Code-Ausführung bis zum Ende des Scopes verzögern
Das abschließende Thema sind defer-Blöcke. Diese Blöcke kann man an jeder Stelle im Programmcode definieren; sie werden aber nicht gleich ausgeführt, sondern erst beim Verlassen des Gültigkeitsbereichs.
Ein kleines Beispiel:
use feature 'defer';
{
say "This happens first";
defer { say "This happens last"; }
say "And this happens inbetween";
}
Auch wenn der defer-Block in Zeile 5 vor dem say in Zeile 7 definiert wurde, wird dieser Gültigkeitsbereich in Zeile 8 verlassen wird. Die Ausgabe ist also
This happens first
And this happens inbetween
This happens last
Solche defer-Blöcke eignen sich sehr gut, um möglichst früh festzulegen, was später mal passieren soll. Ein Beispiel: Nach dem Aufbau einer Datenbankverbindung möchte man schon direkt sagen, dass bei Verlassen des Blocks die Verbindung abgebaut werden soll (und vielleicht noch weitere Dinge gemacht werden sollen) .
use feature 'defer';
{
my $dbh = DBI->connect( ... ) or die "Cannot connect";
defer { $dbh->disconnect; }
my $sth = $dbh->prepare( ... ) or die "Cannot prepare";
defer { $sth->finish; }
#...
}
Hier muss man nicht erst zig Seiten an Code runterscrollen, um zu erkennen, dass auch an das disconnect gedacht wurde. Es steht direkt bei dem Verbindungsaufbau.
Die defer-Blöcke werden in umgekehrter Reihenfolge ihrer Definition ausgeführt.
Perl 5.36 wird noch einiges mehr bringen als das, was in den vergangenen Blogartikeln gezeigt wurde. Wir freuen uns schon auf das neue Release und all die Änderungen, die damit einhergehen.
Permalink: /2022-05-25-auf-dem-weg-zu-perl-536-a-gesammelte-werke
Auf dem Weg zu Perl 5.36 - builtin
Mit Perl 5.36 gibt es ein neues Pragma: builtin. Damit lassen sich neue Hilfsfunktionen in das Skript/Modul importieren. Derzeit bietet das Pragma folgende Hilfsfunktionen:
- true, false, isbool
- weaken, unweaken, isweak
- blessed
- refaddr, reftype
- ceil, floor
- trim
Booleans
use v5.35;
use builtin qw(true false is_bool);
no warnings 'experimental::builtin';
my $true = true;
my $false = false;
say is_bool( $true );
say is_bool( $false );
Aktuell ist das Pragma als experimentell eingestuft. Beim Einbinden des Pragmas muss angegeben werden, welche Funktionen importiert werden sollen (alternativ kann man bei den Aufrufen einfach den vollqualifizierten Namen angeben, z.B. builtin::true().
true und false erstellt jeweils Werte, die im boolschen Kontext wahr bzw. unwahr liefern. In Strings und/oder Berechnungen werden aber die Standardwerte
für wahr/*unwahr* genommen: 1 bzw. "" (Leerstring).
Es gibt einen Unterschied zu den Werten, die man bisher typischerweise für die boolschen Werte verwendet hat: In den Interna der Variablen wird nun zur Laufzeit gespeichert, dass es sich um boolsche Werte handelt:
use Devel::Peek;
my $true = builtin::true;
my $false = builtin::false;
Dump( $true ); Dump( $false );
Liefert
SV = PVNV(0x5653938f9380) at 0x56539391f968
[...]
PV = 0x565392196bc4 "1" [BOOL PL_Yes]
[...]
SV = PVNV(0x5653938f93a0) at 0x56539391f938
[...]
PV = 0x565392196bc3 "" [BOOL PL_No]
[...]
Man sieht hier den Zusatz [BOOL PL_{Yes|No}]. Diese Zusatzinformation wird auch von builtin::is_bool ausgewertet. Damit kann man unterscheiden, ob die 1
ein boolscher Wert ist oder einfach die Zahl 1
:
my $zahl = 1;
my $wahr = builtin::true;
print sprintf '$zahl ist bool: %s, $wahr ist bool: %s',
builtin::is_bool( $zahl ),
builtin::is_bool( $wahr );
mit der Ausgabe
$zahl ist bool: , $wahr ist bool: 1
Referenzen
Auf Referenzen arbeiten einige Hilfsfunktionen:
- weaken, unweaken, isweak
- blessed
- refaddr, reftype
Diese Funktionen sind auch in Scalar::Util verfügbar, deshalb zeige ich hier nur die – in meinen Augen – wichtigsten Funktionen weaken, blessed und reftype.
Mit blessed kann man herausfinden, ob eine Variable eine ge*blessed*e Referenz (sprich ein Objekt) ist. Ist das der Fall, wird der entsprechende Paketname zurückgeliefert:
use builtin qw(blessed);
no warnings 'experimental::builtin';
use Math::BigInt;
my $int = Math::BigInt->new(2022);
if ( blessed $int ) {
say '$int is blessed';
say "package: ", blessed $int;
}
liefert
$ perl blessed.pl
$int is blessed
package: Math::BigInt
Mit reftype bekommt man den Namen der Datenstruktur, auf die die Referenz verweist. Die meisten werden die Funktion ref kennen:
my $array_ref = [];
say ref( $array_ref ); # liefert ARRAY
Soweit so gut. Sobald es aber ein Objekt ist, wird nicht der Name der Datenstruktur ausgegeben, sondern der Name des Pakets:
my $array_object = bless [], 'Array';
say ref( $array_object ); # liefert Array, also den Paketnamen
reftype liefert in jedem Fall den Namen der Datenstruktur:
my $array_object = bless [], 'Array';
say reftype( $array_object ); # liefert ARRAY
Werden komplexe Datenstrukturen aufgebaut, kann es schnell passieren, dass man zirkuläre Referenzen aufbaut:
my %hash_eins;
my %hash_zwei = ( eins => \%hash_eins );
$hash_eins{zwei} = \%hash_zwei;
Damit hat man ein Speicherleck erzeugt. Perl nutzt einen Referenzzähler, um Speicher freizugeben. Und der kann hier nie auf 0 gehen, da in einer zirkulären Referenz immer A auf B verweist und B auf A.
In so einem Fall kann man weaken nutzen. Damit wird der Referenzzähler der Variable nicht hochgezählt:
my %hash_eins;
my %hash_zwei = ( eins => \%hash_eins );
$hash_eins{zwei} = \%hash_zwei;
builtin::weaken( $hash_eins{zwei} );
Zu diesem Problem werden wir noch einen weiteren Blogartikel schreiben.
Endlich trimmen
Eine kleine Funktionalität, die aber auch bei den Entwicklern von Perl viel Diskussionen hervorgerufen hat. Es gibt auf CPAN etliche Implementierungen davon. Leerzeichen am Anfang und am Ende eines Strings entfernen.
Warum gab es diese Diskussionen? Es ging hauptsächlich darum, was das trimmen genau machen soll. Einfach nur Leerzeichen oder noch andere Whitespaces? Soll der Nutzer die Möglichkeit haben, die zu entfernenden Zeichen selbst festzulegen? Soll das ganze Inplace (wie s///) passieren oder soll der veränderte Wert zurückgegeben werden?
Mit trim werden die Whitespaces am Anfang und am Ende eines Strings entfernt und der veränderte Wert wird zurückgegeben:
use builtin qw(blessed);
no warnings 'experimental::builtin';
my $t = "\t \ntest \n ";
say ">>",$t,"<<";
my $trimmed = builtin::trim($t); s
ay ">>$trimmed<<"
liefert die Ausgabe
>>
test
<<
>>test<<
Im Laufe der Zeit werden sicher noch etliche nützliche Hilfsfunktionen im builtin::-Namensraum landen. Schon in Perl 5.36 sind viele Helferlein enthalten, die schon so oft vermisst wurden. Die Vorfreude auf das neue Release wächst.
Permalink: /2022-05-20-auf-dem-weg-zu-perl-536-builtin
Auf dem Weg zu Perl 5.36 - try/catch/finally
Es ist nicht schön, wenn man eine Anwendung hat, die vielleicht mittendrin einfach aufhört zu laufen. Vielleicht ist die Anwendung in einen Fehler gelaufen und vielleicht gibt es keine ordentliche Fehlermeldung. Woran hat es gelegen? An welcher Stelle ist der Fehler aufgetreten?
In Perl nutzt man häufig eval {} , um Fehler abzufangen und eine ordentliche Fehlerbehandlung zu machen. Das hat aber auch Schwächen, so steckt der Fehler in der Spezialvariablen $@ und je nach Situation könnte diese Variable vor der Fehlerbehandlung wieder geleert werden.
Auf CPAN gibt es mehrere Module, die das try/catch-Konstrukt aus anderen Programmiersprachen als Perl-Modul umsetzen. Seit Perl 5.34 gibt es dieses Werkzeug direkt mit dem Perl-Kern und mit Perl 5.36 noch ein weitere Verbesserung. Das ist allerdings noch als experimentell gekennzeichnet.
Schauen wir uns den Standard-Fall mal an:
eval {
die "Help!";
};
if ( $@ ) {
warn "An error occured: $@";
}
In Zeile 2 wird ein die ausgeführt, was zu einem Programmabbruch führen würde. Dank des Block-eval wird dieser Abbruch aber abgefangen und es kann eine ordentliche Fehlerbehandlung durchgeführt werden.
In das try/catch überführt, sieht das so aus:
use feature 'try';
no warnings 'experimental::try';
try {
die 'This died';
}
catch ( $error ) {
warn "The code inside 'try' died with error: '$error'";
}
Der try-Block sieht genauso aus wie beim eval. Allerdings schließt sich hier direkt ein catch-Block an, dem der Fehler aus dem try-Block übergeben wird. Dieser Fehler landet in $error.
Wird bei dem die ein Fehlerobjekt übergeben, landet genau dieses Objekt auch in $error:
use feature 'try';
no warnings 'experimental::try';
package ErrorObject { use Moo; has message => ( is => 'ro' ) }
try {
die ErrorObject->new( message => 'An error occured' );
}
catch ( $error ) {
warn sprintf "The code inside 'try' died with error: '%s'",
$error->message;
}
In Perl 5.36 kommt die Möglichkeit hinzu, einen finally-Block zu definieren. Dieser wird auf jeden Fall ausgeführt – egal, ob ein Fehler aufgetreten ist oder nicht. Außerdem ist es egal, ob in dem catch-Block ein exit aufgerufen wird oder nicht.
Dieser Block kann daher gut für abschließende Schritte verwendet werden, die auf jeden Fall ausgeführt werden sollen:
use feature 'try';
no warnings 'experimental::try';
package ErrorObject { use Moo; has message => ( is => 'ro' ) }
try {
die ErrorObject->new( message => 'An error occured' );
}
catch ( $error ) {
warn sprintf "The code inside 'try' died with error: '%s'",
$error->message;
exit;
}
finally {
print "clean up...";
}
Permalink: /2022-05-12-auf-dem-weg-zu-perl-536-trycatchfinally
Auf dem Weg zu Perl 5.36 – Änderungen mit "use v5.36"
Mittels use v5.<version> können Features und Standardeinstellungen für die angegebene Perl-Version geladen werden. Und es ist die minimal notwendige Perl-Version. Ein use v5.10 verlangt, dass das Programm mindestens mit Perl 5.10 ausgeführt wird. Darüber hinaus wird zum Beispiel das Feature say aktiviert.
Mit use v5.36 ändern sich einige Dinge, die in den folgenden Absätzen beschrieben werden.
warnings wird aktiviert
Es ist seit vielen Jahren bewährte Praxis, dass zu den ersten Zeilen eines jeden Programms oder Moduls die Zeilen use strict; und use warnings; gehören sollen. Mit use v5.36 ist das nicht mehr notwendig, denn damit wird beides automatisch aktiviert (strict wird schon seit längerem auf diese Weise aktiviert).
use v5.35;
my $s = 'test';
$s += 1;
Gibt diese Warnung aus:
Argument "test" isn't numeric in addition (+)
Einige Konstrukte
werden zu echten Fehlern
Es gibt Dinge, die in Perl möglich sind aber schon seit vielen Jahren nicht mehr empfohlen werden. Drei dieser Dinge werden jetzt zu echten Fehlern. Ohne das use v5.36 laufen die noch, aber von der Verwendung rate ich ab.
Wer auch mit use v5.36 diese Konstrukte verwenden möchte, muss das explizit über use feature "feature_name" tun.
Multidimensional Hashes
Ich muss gestehen, dass ich diese Konstrukt noch nie in produktivem Code gesehen geschweige denn verwendet habe.
my %x;
$x{1,'talk'} = 'Perl Features';
print $x{1,'talk'};
Wie man sieht, ist hier der Hash kein einzelner Wert sondern eine Liste an Werten. Mit use v5.36 ist das nicht mehr erlaubt und die Fehlermeldung
Multidimensional hash lookup is disabled
erscheint.
Für diejenigen, die es interessiert: Bei diesen multidimensionalen Hashes werden die Werte der Liste zu einem Schlüssel zusammengefügt, so dass es ein normaler
Hash ist. Die Werte werden dabei mit \x1C (File Separator) konkateniert, so dass man theoretisch auf den oben gezeigten Hasheintrag auch über
print $x{"1\x1Ctalk"};
zugreifen kann.
Indirekte Methodenaufrufe
Diese Schreibweise dürfte Programmierern mit Erfahrung in anderen Programmiersprachen bekannt vorkommen:
my $object = new Klasse;
Eigentlich sollte
my $object = Klasse->new;
verwendet werden.
Die erste Schreibweise nennt man indirekte Methodenaufrufe. Der Code kann so funktionieren wie es gewünscht ist, muss aber nicht. Das Problem wird vielleicht mit etwas Code deutlicher:
use v5.10;
package Klasse {
sub new { return bless {}, shift }
sub test { return "test" }
};
sub hallo { return "hallo" };
my $object = new Klasse;
say $object;
say hallo $object;
my $test = test $object;
say $test;
say test $object;
Was passiert hier ab der Zeile 11?
In den Zeilen davor wird nur etwas Vorbereitung betrieben. Zeile 1 wird benötigt, damit das say zur Verfügung steht. Und in den Zeilen 3 bis 6 wird ein package definiert, das die zwei Subs new und test bereitstellt. Hier ist das package eine Klasse. In Zeile 8 wird noch eine Subroutine hallo definiert, die zum Hauptprogramm
gehört.
Schon Gedanken dazu gemacht, was in den restlichen Zeilen des Codes passiert? Die Ausgabe sieht so aus:
Klasse=HASH(0x55e4b7c81340)
hallo
test
say() on unopened filehandle test at ...
In Zeile 10 wird die Funktion new des Pakets Klasse aufgerufen. Diese gibt ein Objekt zurück. Die Zeile 1 der Ausgabe bestätigt das. Funktioniert.
In Zeile 13 wird die Funktion hallo des Hauptprogramms ausgeführt und diese bekommt das Objekt als ersten Parameter übergeben (das sieht man jetzt nicht an der Ausgabe, kann aber durch eine kleine Änderung am Code selbst überprüft werden). Funktioniert.
In Zeile 15 wird die Methode test des Objekts aufgerufen, das Ergebnis (test
) landet in der Variable $test und diese wird in Zeile 16 ausgegeben. Funktioniert.
Zeile 18 provoziert einen Fehler. Offensichtlich denkt perl, dass test ein Dateihandle ist (siehe auch nächstes Konstrukt
), und nicht die Methode test des Objekts. Das heißt, ich muss bei dieser Schreibweise aufpassen, in welchem Umfeld ich die Methode aufrufen will.
Und was passiert wenn in Zeile 9 noch eine Subroutine test (sub test { "test2"} ) eingefügt wird? In diesem Fall wird perl diese Funktion in den Zeilen 15 und 18 genau diese Funktion ausführen und die Ausgabe wäre
Klasse=HASH(0x55e4b7c81340)
hallo
test2
test2
Es gibt noch mehr Fallen. Aus diesem Grund sind diese indirekten Methodenaufrufe mit use v5.36 nicht mehr erlaubt. Allerdings kann perl nur die indirekten Methodenaufrufe wie in Zeile 10 erkennen und es kommt zu der Fehlermeldung
Bareword "Klasse" not allowed while "strict subs" in use
Die Probleme oben verdeutlichen aber, warum grundsätzlich die Schreibweise mit -> verwendet werden soll. Denn damit weiß der Interpreter immer, welche Funktion/Methode ausgeführt werden muss.
Bareword Dateihandles
In vielen Perl-Tutorials, die so im Internet zu finden sind, wird das Schreiben einer Datei mit folgendem Code (oder so ähnlich) gezeigt:
open FH, ">/tmp/datei.txt" or die $!;
print FH "Eine Zeile\n";
close FH;
Dieses FH ist ein sogenanntes Bareword Filehandle. Der Name kann frei gewählt werden. Für einen Einstieg in Perl oder in Einzeilern ist die Verwendung dieser Bareword Filehandles auch ganz gut. Aber wer etwas Erfahrung mit Perl gesammelt hat, sollte darauf verzichten und zu lexikalischen Dateihandles übergehen:
open my $fh, ">", "/tmp/datei.txt" or die $!;
print $fh "Eine Zeile\n";
close $fh;
Ein Vorteil dieser lexikalischen Dateihandles haben wir beim vorherigen Konstrukt gezeigt. Was wenn es zufällig eine Subroutine mit dem Namen des *Bareword*s gibt? Es gibt aber noch weitere Vorteile: Die lexikalischen Dateihandles werden automatisch geschlossen, wenn sie den Gültigkeitsbereich verlassen (auch wenn man schon allein wegen der Fehlerbehandlung selbst das close machen sollte). Und sie sind eben lexikalisch, also nicht global.
Die Bareword Filehandles sind global und können so zu Seiteneffekten führen. Ein Beispiel:
use warnings;
read_data();
sub read_data {
open FH, '</tmp/data.txt' or die $!;
while ( my $line = <FH> ) {
print $line;
add_to_log( $line ) if $line =~ m{error};
}
close FH;
}
sub add_to_log {
open FH, '>/tmp/log.txt' or die $!;
print FH $_[0];
close FH;
}
Wenn /tmp/data.txt eine Zeile mit error
enthält, sieht die Ausgabe so aus:
ein
error
readline() on closed filehandle FH at ...
Das globale Filehandle wurde also in einer Subroutine geschlossen, bevor alle Zeilen der Datei in der Ursprungssubroutine gelesen werden konnten.
Benutzt man die Bareword Filehandles mit use v5.36, gibt es eine entsprechende Fehlermeldung:
Bareword filehandle "FH" not allowed under 'no feature "bareword_filehandles"' at ...
Einige Standard-*Bareword Filehandles* wie STDIN, STDOUT, STDERR und DATA werden auch mit use v5.36 funktionieren.
Permalink: /2022-05-06-auf-dem-weg-zu-perl-536-a-anderungen-mit-use-v536
Auf dem Weg zu Perl 5.36 – Signaturen
Nicht einmal 1 Monat, dann wird es die nächste Version von Perl 5 geben: Perl 5.36. Um die Wartezeit etwas zu verkürzen, werden wir hier ein paar Neuerungen vorstellen. Der erste Teil hat dann aber etwas zum Thema, das gar nicht mehr so neu ist: (Methoden-)Signaturen. Schon seit Perl 5.20 (also rund acht Jahre) gibt es die Signaturen. Aber jetzt endlich sind sie nicht mehr als experimentell
gekennzeichnet.
Mit den Signaturen kann der Code übersichtlicher gestaltet werden und man automatisch eine Überprüfung der Anzahl der übergebenen Parameter dabei.
Der einfachste Fall sind verpflichtende Parameter:
use v5.35; # aktiviert auch strict und warnings
crawl( 'https://perl-academy.de' );
sub crawl ($url) {
say "URL: $url";
# hole die Seite und extrahiere die Links
# siehe Beispielcode im Git-Repository
}
Hier hat die Subroutine crawl genau einen Pflichtparameter – $url. Die Variable muss nicht extra deklariert werden und diese ist nur in der Subroutine gültig. In der Subroutine selbst kann ganz normal mit der Variablen gearbeitet werden.
In diesem Beispiel ersetzt das
sub crawl ($url) {
}
mehr oder weniger nur ein
sub crawl {
my ($url) = @_;
}
Sieht erst einmal nach nicht viel aus. Mit der Verwendung der Signaturen gibt es aber eine Prüfung der Anzahl an übergebenen Parameter. Der Aufruf crawl() erzeugt dann die Fehlermeldung
Too few arguments for subroutine 'main::crawl' (got 0; expected 1)
und der Aufruf crawl('https://perl-academy.de', 1) erzeugt die Fehlermeldung
Too many arguments for subroutine 'main::crawl' (got 2; expected 1)
Möchte man etwas flexibler in den Aufrufen sein, muss also etwas an den Signaturen geändert werden. Eine Möglichkeit ist, slurpy Parameter zu nutzen. Soll crawl beliebig viele Parameter akzeptieren, kann man
sub crawl ($url, @more_parameters) {
}
nutzen. Damit landet der erste übergebene Parameter in $url und alle weiteren Parameter in @more_parameters. Es kann auch ein Hash benutzt werden:
sub crawl ($url, %opts) {
}
Damit landet bei einem Aufruf mit crawl('https://perl-academy.de', max_redirects => 2) die URL in $url und im Hash %opts gibt es den Schlüssel max_redirects mit dem Wert 2.
Aber diese beiden Möglichkeiten sind nicht immer die beste Wahl, weil dann unterschiedliche Parameter in einem Array landen. Deshalb gibt es auch die Möglichkeit, mittels default-Werten die Parameter optional zu machen und sie mit einem vorgegebenen Wert zu belegen:
sub crawl ($url, $max_redirects = 2) {
}
Bei einem Aufruf mit crawl('https://perl-academy.de', 5) ist der Wert von $max_redirects natürlich 5, bei einem Aufruf mit crawl('https://perl-academy.de' ) ist der Wert der Variablen 2.
Der default-Wert muss nicht nur eine Zahl oder ein String sein, sondern kann ein Subroutinen-Aufruf sein, vorherige Parameter können verwendet werden und auch ein do{}-Block ist möglich:
sub crawl ($url, $max_redirects = get_config('max_redirects') ) {
}
sub crawl ($url, $api_url = $url . '/api/v1' ) {
}
sub crawl ( $url, $max_redirects = do { warn "Using default value"; 2; } ) {
}
Es gibt noch die Möglichkeit, unbenannte Variablen zu nutzen, wenn man an der Verwendung von Werten nicht interessiert ist. Die Verwendung dieser unbenannten Variablen ist unter https://metacpan.org/release/SHAY/perl-5.35.11/view/pod/perlsub.pod#Signatures nachzulesen. Das würde diesen Blogartikel zu sehr ausdehnen und diese Variablen spielten bisher bei in meinem Code keine Rolle.
Was Signaturen nicht bietet, sind Prüfungen von Datentypen. Es wird also nicht geprüft, ob der übergebene Skalar eine Arrayreferenz, Hashreferenz oder einfach ein String ist. Das muss weiterhin selbst gemacht werden. Auch benannte Parameter (beispielsweise crawl( url => 'https://perl-academy.de') ) sind derzeit nicht möglich.
Aber schon die gezeigten Möglichkeiten können das Programmieren stark vereinfachen.
Der Beispielcode ist im Git-Repository unter https://os.perl-services.de/perl-academy/blog-codesamples/-/tree/main/2022/04/5_36_signaturen zu finden.
Bericht Deutscher Perl/Raku-Workshop 2022
Ende März fand in der 24. Deutsche Perl/Raku-Workshop statt. Nachdem im letzten Jahr die Veranstaltung auf Grund der Corona-Pandemie nur online stattfand, war in diesem Jahr ein Teil der Teilnehmer in Leipzig anwesend. Weitere Teilnehmer lauschten den Vorträgen im Live-Stream. Corona bzw. die Covid-19-Zertifikate waren Thema bei domm
, der gezeigt hat, wie er mit einer Perl-Anwendung die QR-Codes der Zertifikate validiert und geprüft hat.
Generell waren einige Talks eher auf die Zukunft ausgerichtet: So berichtete Curtis Ovid
Poe über den aktuellen Stand von Corinna, einer neuen Objektorientierung, die hoffentlich bald in den Perl-Core einfließt. Paul Evans, der an Corinna mitentwickelt und mit Object::Pad ein Testfeld für die Features hat, berichtete von seinen Plänen in On the Road to 2025
. Nicht ganz soweit – nur bis zum Release von Perl 5.36 im Mai/Juni diesen Jahres – habe ich vorausgeschaut mit einem Überblick über die neuen Features.
Während der Lightning Talks hat Geizhals angekündigt, dass sie Paul Evans und damit die Corinna-Entwicklung mit einem nicht ganz kleinen Geldbetrag unterstützen werden.

Bild: Die Teilnehmer vor Ort, Quelle: Max Maischein
Auch weniger technische Vorträge gab es. Sören Sörries ging in seinem verschiedenen Vorträgen auf verschiedene Lernangebote und -techniken ein.
Raku-Vorträge gab es (zu) wenige: Geizhals' Anwesenheitsmonitor Werda
wurde mit Raku und Cro umgesetzt. Maroš Kollár hat gezeigt, wie die Anwendung umgesetzt wurde.
Ansonsten waren die Vorträge bunt gemischt: Von der Chart-Erstellung mit Perl, über Neuigkeiten zu YAML bis zu den Kollegen von denen man gar nicht weiß, dass man sie hat (gemeint sind z.B. die Autoren der Perl-Module die man einsetzt).
Die Videos der einzelnen Vorträge werden in wenigen Tagen online sein. Wir werden darüber auch twittern.
Und im nächsten Jahr geht es dann nach Frankfurt. Ein genaues Datum steht noch nicht fest, aber die Webseite ist schon online und Vorträge können bereits eingereicht werden. Wer bisher noch keine Erfahrungen mit dem Halten von Vorträge gesammelt hat, kann auch erst einmal einen Lightning Talk einreichen. Max Maischein hat es so schön gesagt: Es sind nur 5 Minuten. Und wenn etwas schiefgeht – man weiß es sind nur 5 Minuten
. Und auch ich habe 2004 mit einem Lightning Talk angefangen...
Ich möchte mich bei den lokalen Orgas von Leipzig/Halle.pm und bei Max bedanken. Ihr habt einen tollen Workshop auf die Beine gestellt!
Update 14.06.2022: Ein Großteil der Videos ist jetzt unter https://media.ccc.de/c/gpw2022 erreichbar.
Permalink: /2022-04-06-bericht-deutscher-perlraku-workshop-2022
perlbrew
Das System-Perl zu verwenden hat viele Nachteile. Diese können behoben werden, wenn man ein eigenes Perl in seinem Benutzerverzeichnis installiert. Mit dem Werkzeug perlbrew kannst du mehrere Perl-Installationen nebeneinander auf einem System konfliktfrei betreiben.
Die Probleme mit dem System-Perl
Die Anwendungsentwicklung mit dem System-Perl zu koppeln bringt viele Nachteile mit sich. Hier einige Beispiele:
- Perl kann nicht unabhängig vom System aktualisiert werden, wenn du Probleme beheben möchtest, neue Sprach-Features nutzen willst – oder vielleicht sogar ganz bewusst ein Perl nutzen möchtest, das älter als das System-Perl ist.
- In Organisationen sind Entwickler häufig von den Systemadministratoren abhängig, die die Stabilität des gesamten Systems und nicht nur einer Anwendung beachten müssen, und deswegen nicht »einfach so« Perl aktualisieren können.
- Die Installation von CPAN-Modulen ist wegen fehlender Berechtigungen nicht möglich.
- Der Test von Anwendung unter neueren Perl-Versionen auf einem System ist nicht einfach möglich.
Eine Lösung ist perlbrew, das die Installation mehrerer Perl-Versionen im Benutzerverzeichnis ermöglicht, so dass keine Administratorrechte benötigt werden. Das Werkezeug isoliert diese Installationen voneinander und ermöglicht einen einfachen Wechsel zwischen ihnen.
Admin-freie Installation von Perl-Versionen
Die Installation von perlbrew ist auf zwei Wegen möglich. Die einfachste geht über cpanm:
$ cpanm App::perlbrew
$ perlbrew init
Solltest du keine Module von CPAN installieren können (siehe meine Anmerkung oben zu fehlenden Adminstratorrechten), kannst du dir ein Installationsskript herunterladen und es von der Shell ausführen lassen. Aus Sicherheitsgründen verweise ich dich dafür auf die Homepage.
perlbrew kann alle offiziell verfügbaren Perl-Versionen bauen und installieren. Welche das sind, kannst du dir auflisten lassen:
$ perlbrew available
perl-5.33.7
perl-5.32.1
perl-5.30.3
perl-5.28.3
perl-5.26.3.tar.bz2
...
perl-5.8.9.tar.bz2
perl-5.6.2
perl5.005_03
perl5.004_05
cperl-5.29.2
cperl-5.30.0
cperl-5.30.0-RC1
Aus diesen Versionen wählst du dir eine aus. Diese wird dann in das Verzeichnis perl5/perlbrew im Benutzerverzeichnis installiert:
perlbrew install perl-5.33.7
$ perlbrew install perl-5.33.7
Fetching perl 5.33.7 as $HOME/perl5/perlbrew/dists/perl-5.33.7.tar.gz
Download http://www.cpan.org/src/5.0/perl-5.33.7.tar.gz to $HOME/perl5/perlbrew/dists/perl-5.33.7.tar.gz
Installing /Users/glauschwuffel/perl5/perlbrew/build/perl-5.33.7/perl-5.33.7 into ~/perl5/perlbrew/perls/perl-5.33.7
This could take a while. You can run the following command on another shell to track the status:
tail -f ~/perl5/perlbrew/build.perl-5.33.7.log
Wenn du den in der letzten Zeile angegeben Befehl in einer zweiten Shell ausführt, kannst du dem Installationprozess »zusehen«.
Welches Perl die Shell ausführt, wird durch den Ausführungspfad bestimmt. Durch die Änderung dieses Ausführungspfads wird zwischen den installierten Perl-Versionen umgeschaltet. Dafür gibt es den perlbrew-Befehl use:
$ perlbrew use perl-5.33.7
Durch mehrfache Verwendung von perlbrew use kannst du in einer Arbeitssitzung in der Shell zwischen den Versionen wechseln. Beim Öffnen einer weiteren Shell wird aber weiterhin das System-Perl verwendet. Wenn du dauerhaft eine Perl-Version verwenden möchtest, kann du mit dem Befehl switch die gewünschte Version in der Shell-Konfiguration ablegen:
perlbrew switch perl-5.33.7
Gelegentlich kommt es bei der Arbeit mit perlbrew vor, dass kurzfristig das System-Perl benutzt werden soll:
perlbrew switch-off
Mit den hier gezeigten Befehlen hast du nun die grundlegenden Werkzeuge zusammen, um dir die Perl-Versionen zu installieren, die du benötigst. Da sich alles in deinem Benutzerverzeichnis abspielt, hast du die volle Kontrolle.
Zusammenfassung
In diesem Artikel habe ich einen kurzen Überblick über die Möglichkeiten gegeben, die perlbrew bietet. Dabei konnte ich vieles nur anreißen. Wenn du jetzt neugierig geworden bist und tiefer einsteigen möchtest, empfehle ich dir die Homepage des Projekts, um mehr über weitere Befehle zu erfahren.
Permalink: /2021-07-14-perlbrew