Modul des Monats: PPI
Only perl can parse Perl
Dieses Zitat von Tom Christiansen gilt in Teilen immer noch. Perl (die Sprache) ist eigentlich alles das, was perl (der Interpreter) sauber ausführen kann. Dass das nicht nur der Code mit der Syntax ist, die man so hinlänglich sieht, kann man an etlichen Acme::-Modulen sehen. So kann man wirklich sauberen Code mit Acme::Bleach schreiben. Das Modul wandelt normalen
Perl-Code in Whitespaces um – und das Programm läuft immer noch. Ein weiteres Beispiel: Zu meinen Ausbildungszeiten in der Bioinformatik habe ich (nicht produktiven) Code mit Acme::DoubleHelix in eine Doppelhelix-Darstellung umgewandelt.
Um diese Darstellung von Code geht es aber nicht, wenn wir etwas mit PPI machen. Das Modul dient der statischen Analyse von Perl-Code. Zum Beispiel als Backend
für Perl::Critic und das von Gregor letztens vorgestellte Test::Perl::Critic::Progressive. Da PPI eine statische Analyse durchführt, wird der Code nicht ausgeführt. Deshalb können manche Konstrukte aber nicht tiefergehend betrachtet werden:
require $module;
Welches Modul hier geladen wird, kann PPI nicht feststellen. Für viele Anwendungsbereiche ist das aber auch irrelevant. Es ermöglicht aber viele Anwendungen, ohne dass man Perl-Code ausführen muss oder selbst mit mehr oder weniger guten regulären Ausdrücken im Code etwas suchen muss.
Aber nicht nur wegen Perl::Critic ist PPI unser Modul des Monats
. Es vereinfacht auch unsere Arbeit bei einigen Anwendungen.
Zum einen bei der Bereitstellung der Perl-API-Dokumentation der ((OTRS)) Community Edition unter https://otrs.perl-services.de aber auch bei der Anwendung zur Messung der Modul-Verbreitung unter https://usage.perl-academy.de .
Bei der OTRS-Dokumentation schauen wir im Code nach, ob es überhaupt POD in der Datei gibt und schmeißt den Rest quasi weg. Damit wird es einfacher, Teile der Dokumentation auseinanderzunehmen, ohne dass der restliche Code in die Quere kommt.
So sieht der entsprechende Code aus:
my @perl_files = $archive->membersMatching('\.(?:pm|pod)$');
FILE:
for my $file ( @perl_files ) {
my $path = $file->fileName;
next FILE if $path =~ m{cpan-lib};
next FILE if $path !~ m{Kernel};
my $code = $file->contents;
my $doc = PPI::Document->new( \$code );
my $pod = $doc->find( 'PPI::Token::Pod' );
next FILE if !$pod;
my $pod_string = join "\n\n", map{ $_->content }@{ $pod };
my $package = $doc->find_first('PPI::Statement::Package');
$pod_string =~ m{
^=head\d+ \s+ DESCRIPTION \s+
(?<description>.*?) \s+
^=(?:head|cut)
}xms;
my $description = $+{description} || '';
}
In $archive steckt ein Objekt von Archive::Zip und über das holen wir alle Perl-Module und POD-Dateien, die in der Zip-Datei stecken. Wir holen immer die Zip-Datei, damit wir nicht zig Git-Klone bei uns rumfliegen haben und wir die vielleicht gar nicht mehr brauchen.
Von jeder dieser Dateien holen wir mit ->contents den Inhalt der Datei. Mit PPI::Document->new( \\$code ) erzeugen wir dann das Objekt von PPI::Document und durch die Skalarreferenz weiß PPI, dass nicht eine Datei geparst werden soll, sondern der Inhalt der Skalarvariablen. Soll eine Datei geparst werden, nimmt man einfach PPI::Document->new( $path_to_file ) .
Anschließend suchen wir alle POD-Teile in der Datei (find), und wenn gar kein POD enthalten ist, brauchen wir gar nicht weiterzumachen. Der Methode find muss man den Paketnamen übergeben, nach dessen Objekten man sucht. Welche Klassen es gibt ist, wird in der PPI-Dokumentation gezeigt.
Da wir auch noch den Paketnamen brauchen, der im Perl-Code zu finden ist, suchen wir das erste Element der Klasse PPI::Statement::Package.
Somit haben wir dann alles, um das HTML aus POD zu generieren.
Die zweite Anwendung nutzt PPI, um cpanfiles zu parsen. Warum wir nicht das Modul Module::CPANfile nutzen? Wenn man sich das anschaut, lädt es den Perl-Code mit eval. Und da wir keine Kontrolle darüber haben, was die Besucher in die Dateien schreiben, die hochgeladen werden, nehmen wir lieber einen Parser zur statischen Analyse.
Schauen wir uns also mal an, was PPI aus einem cpanfile macht. Das cpanfile hat diesen Inhalt:
on 'test' => sub {
requires 'Perl::Critic::RENEEB' => '2.01';
requires "Proc::Background" => 0;
requires 'Test::BDD::Cucumber';
};
on 'runtime' => sub {
requires 'Class::Unload';
};
on 'develop' => sub {
requires 'CryptX' => '0.64';
requires 'DBIx::Class::DeploymentHandler';
requires q~Dist::Zilla~;
requires MySQL::Workbench::DBIC => '1.13';
};
Um uns anzuschauen, wie das Perl Document Object Tree dazu aussieht, nutzen wir das folgende Skript (Perl::Critichat ein etwas mächtigeres Skript im Repository, das aber leider nicht installiert wird):
#!/usr/bin/perl
use strict;
use warnings;
use PPI;
use PPI::Dumper;
use Mojo::File qw(curfile);
curfile->sibling('examples')->list->first( sub {
my $code = $_->slurp;
my $doc = PPI::Document->new( \$code );
PPI::Dumper->new( $doc )->print and return;
});
Das erzeugt dann folgende Ausgabe:
PPI::Document
PPI::Statement
PPI::Token::Word 'on'
PPI::Token::Whitespace ' '
PPI::Token::Quote::Single ''test''
PPI::Token::Whitespace ' '
PPI::Token::Operator '=>'
PPI::Token::Whitespace ' '
PPI::Token::Word 'sub'
PPI::Token::Whitespace ' '
PPI::Structure::Block { ... }
PPI::Token::Whitespace '\n'
PPI::Token::Whitespace ' '
PPI::Statement
PPI::Token::Word 'requires'
PPI::Token::Whitespace ' '
PPI::Token::Quote::Single ''Perl::Critic::RENEEB''
PPI::Token::Whitespace ' '
PPI::Token::Operator '=>'
PPI::Token::Whitespace ' '
PPI::Token::Quote::Single ''2.01''
PPI::Token::Structure ';'
PPI::Token::Whitespace '\n'
PPI::Token::Whitespace ' '
PPI::Statement
PPI::Token::Word 'requires'
PPI::Token::Whitespace ' '
PPI::Token::Quote::Double '"Proc::Background"'
PPI::Token::Whitespace ' '
PPI::Token::Operator '=>'
PPI::Token::Whitespace ' '
PPI::Token::Number '0'
PPI::Token::Structure ';'
PPI::Token::Whitespace '\n'
[...]
Wir wollen einfach die Modulnamen daraus haben, also der erste String nach dem Literal requires. An dem Dump kann man gut sehen, dass das Literal immer ein Objekt der Klasse PPI::Token::Word ist. Aber nicht jedes Objekt der Klasse enthält das Literal requires. Wir sehen zum Beispiel auch sub. Das müssen wir berücksichtigen. Nach dem Literal kommen beliebige Whitespaces, die uns aber nicht interessieren. PPI kennt da das Prinzip der significant siblings/children
. Da in dem Baum die Elemente von requires und der Modulname auf einer Ebene sind, interessieren wir uns für das nächste signifikate Geschwister.
So sieht der Code dann in der Anwendung aus:
my $code = $file->slurp;
my $doc = PPI::Document->new( \$code );
my $requires = $doc->find(
sub { $_[1]->isa('PPI::Token::Word') and $_[1]->content eq 'requires' }
);
if ( !$requires ) {
$file->remove;
return;
}
REQUIRED:
for my $required ( @{ $requires || [] } ) {
my $value = $required->snext_sibling;
my $can_string = $value->can('string') ? 1 : 0;
my $prereq = $can_string ?
$value->string :
$value->content;
save_prereq( $prereq );
}
Der Anfang ist ähnlich zu oben. Wir lesen die Datei ein und erzeugen ein Objekt von PPI::Document. Während wir oben der Methode find nur die Klasse angegeben haben, deren Objekte wir alle haben wollen, möchten wir hier die Suche etwas einschränken. Nämlich alle PPI::Token::Word-Objekte, deren Inhalt required
ist. Übergibt man eine anonyme Subroutine an find, wird für jedes Element unterhalb des zu durchsuchenden Knoten diese Subroutine aufgerufen.
Als Parameter werden zwei Parameter übergeben. Zum einen das Element auf dem die Suche ausgeführt wird und zum anderen das Element, das geprüft wird.
Die Methode content liefert den Code 1:1.
Für alle gefundenen requires bekommen wir die Objekte der Klasse PPI::Token::Word. Für jedes dieser Objekte wollen wir das erste signifikante Geschwister. Mit next_sibling würde man die Whitespaces bekommen, die interessieren uns aber nicht. Aus diesem Grund müssen wir snext_sibling verwenden.
Schauen wir noch mal kurz auf die verschiedenen Varianten der Modulangaben:
requires 'Perl::Critic::RENEEB' => '2.01';
requires "Proc::Background" => 0;
requires q~Dist::Zilla~;
requires MySQL::Workbench::DBIC => '1.13';
... und die dazugehörigen PPI-Elemente:
PPI::Token::Quote::Single ''Perl::Critic::RENEEB''
PPI::Token::Quote::Double '"Proc::Background"'
PPI::Token::Quote::Literal 'q~Dist::Zilla~'
PPI::Token::Word 'MySQL::Workbench::DBIC'
Da die Whitespace-Knoten übergangen werden bekommen wir einen der hier gezeigten Knoten. Mit der Methode content bekommen wir den Wert wie er hier zu sehen ist, also inklusive der Anführungszeichen bzw. des q\~\~.
Wir müssen uns also auf die unterschiedlichen Methoden stützen, die die Objekte mitliefern. Bei den ganzen Quote::\*-Klassen kann die Methode string genutzt werden, bei PPI::Token::Word die Methode content.
Noch kurz zu den s...-Methoden: Als significant werden alle Teile bezeichnet, die für die Ausführung des Codes wichtig sind. Kommentare, POD-Dokumenation, __END__-Bereiche und Whitespaces gehören nicht dazu.
Die Skripte und Beispiele habe ich auch wieder ins Git-Repository gepackt.
Permalink: /2020-10-21-ppi
Optimierung von Docker-Images
Wenn man als Entwickler mit der Erstellung von Docker-Images anfängt, dann ist das Image zunächst auf Funktionalität optimiert. Mit fortschreitender Entwicklung wird eine schnelle Rückmeldung über das Build-Ergebnis an die Entwickler wichtiger. Zudem soll ein Build reproduzierbar sein, damit von der CI-Umgebung gemeldete Fehler nachvollzogen und Änderungen für den Betrieb einplant werden können. Dieser Artikel zeigt, worauf man bei achten sollte, damit das klappt.
Zuerst: Funktionalität
Wir nutzen Gitlab und haben uns zu Beginn der Nutzung dieses Dienstes darauf konzentriert, überhaupt einen Build nach einem Commit durchlaufen zu lassen. Das ist manchmal gar nicht so einfach, da diverse Abhängigkeiten benötigt werden, die vor Ausführung von Tests in einem laufenden Container installiert werden müssen.
Wir bei Perl-Services haben uns zu Beginn auf die CI-Stufe von Gitlab verlassen. Da es hier aber mitunter etwas dauern kann, bis ein Build nach einem Commit startet, haben wir schnell gemerkt, dass lokales Bauen von Images sinnvoller ist. Dafür haben wir dann ein Makefile erstellt:
#!/bin/make -f
#
# Makefile pointers...
# Self-documenting:
# https://marmelab.com/blog/2016/02/29/auto-documented-makefile.html
# Argument passing:
# https://stackoverflow.com/questions/2826029/passing-additional-variables-from-command-line-to-make
#
# To add a new option, follow the format below, e.g.:
# make command: ## Documentation of command
# ./the-command-to-run.sh
# Default to displaying the help
.DEFAULT_GOAL := help
.PHONY: help
REGISTRY=registry.gitlab.com
IMAGE_NAME=perlservices/groupname/projectname-docker
IMAGE_TAG=latest
FULL_IMAGE_NAME=${REGISTRY}/${IMAGE_NAME}:${IMAGE_TAG}
# Displays all the make options and their descriptions
help:
@grep -E '^[a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | sort | awk 'BEGIN {FS = ":.*?## "}; {printf "\033[36m%-30s\033[0m %s\n", $$1, $$2}'
build: ## Build Docker image
docker build -t ${FULL_IMAGE_NAME} .
shell: ## Start a container from the image built and run a shell in it
docker run --rm -it --entrypoint /bin/bash \
-v $$PWD/src:/src \
-p 8080:8080 \
${FULL_IMAGE_NAME}
Dieses Makefile erstellt beim Aufruf von make build ein Docker-Image anhand des im gleichen Verzeichnisses liegenden Dockerfiles. Der Aufruf von make shell startet einen Container mit diesem Image und öffnet eine Shell darin, wobei hier das lokale Verzeichnis src im Container unter /src zur Verfügung steht.
Mit Hilfe dieses Makefiles können wir recht einfach ein Docker-Image erstellen und dieses lokal weiterentwickeln.
Schnelle Rückmeldung durch kurze Durchlaufzeit
Damit eine Perl-Distribution im Rahmen eines Docker-Images erstellt werden kann, werden viele Bausteine benötigt.
Einerseits benötigen wir auf Systemebene einige Werkzeuge. Dazu gehört zum Beispiel curl, um andere Builds auf Gitlab anzustoßen. Diese installieren wir über den Paketmanager des Betriebssystems.
Anderseits brauchen wir auf Anwendungsebene Module, die wir installieren müssen. Wenn sie in der geeigneten Version als Paket des Betriebssystems vorliegen, installieren wir sie ebenfalls mit dem Paketmanager des Betriebssystems. Wenn dies nicht der Fall ist, installieren wir sie von CPAN.
Diese Installationen dauern entsprechend lange und greifen auf externe Quellen zu. Dadurch dauert der Build lange und kann schlimmstenfalls fehlschlagen.
Daher haben wir hier in zwei Schritten optimiert: Wir erstellen für eine zu entwickelnde Perl-Distribution (oder Anwendung) ein spezifisches Image, das alle benötigten Abhängigkeiten enthält.
Im Dockerfile installieren wir zunächst mit apt-get install die benötigten Pakete des Betriebssystems:
FROM registry.gitlab.com/perlservices/groupname/projectname-docker:latest
RUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y \
lsb-core \
wget
# Add PostgreSQL repo for the matching release of the OS
RUN wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | apt-key add -
RUN echo "deb http://apt.postgresql.org/pub/repos/apt/ `lsb_release -cs`-pgdg main" | tee /etc/apt/sources.list.d/pgdg.list
RUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y \
postgresql \
postgresql-client \
git \
apache2 \
curl \
phppgadmin \
php-pgsql \
cpanminus \
libdbd-pg-perl \
libnet-ssleay-perl \
libxml-parser-perl \
gosu \
...
Die Perl-Abhängigkeiten legen wir in einem cpanfile fest:
...
requires 'Mojolicious' => 8;
requires 'Mojolicious::Plugin::Bcrypt' => 0;
requires 'Mojolicious::Plugin::Status' => 0;
requires 'Moo' => 0;
requires 'MySQL::Workbench::DBIC', '>= 1.13';
requires 'MySQL::Workbench::Parser', '>= 1.06';
...
Das so erstellte Image verwenden wir dann in der .gitlab-ci.yaml unseres Projektes. So können dann sofort nach einem Commit in der CI-Stufe die konfigurierten Befehle ausgeführt werden, denn alle Abhängigkeiten sind bereits im Image vorhanden.
Reproduzierbare Builds durch genaue Versionsangaben
Gerade zu Beginn der Arbeit mit den oben beschriebenen projektspezifischen Docker-Images haben wir öfter Probleme mit der Nachvollziehbarkeit von Fehlern im Build auf Gitlab gehabt. Ursache dafür war, dass sich Abhängigkeiten in jedem Build geändert haben.
Beispiele für diese Änderungen:
- Eine Perl-Distribution wird auf CPAN zwischen zwei Builds aktualisiert.
- Lokal ist eine indirekte Abhängigkeit in einer anderen Version installiert.
Es wird dann unter Umständen auf Gitlab ein Fehler im Build angezeigt, der lokal beim Entwickler nicht mehr oder anders auftritt.
Durch das Erstellen von projektspezifischen Docker-Images werden schon viele Abhängigkeiten festgezurrt, so dass hier weitestgehend reproduzierbare Builds umgesetzt werden konnten.
Eine wesentliche Abhängigkeit ist jedoch noch nicht festgezurrt: Die des grundlegenden Images für alle Builds – Das verwendete Betriebssystem.
Vielfach wird in Beispielen für ein Dockerfile entweder kein Tag bei einem verwendeten Image angegeben oder eines mit dem Namen »latest«. Beide führen dazu, dass jeweils die letzte Fassung eines Images verwendet wird:
FROM debian:latest
Im schlimmsten Fall kann es dadurch dazu kommen, dass zwischen zwei Builds ein Versionssprung des Betriebssystems stattfindet und alle abhängigen Images neu gebaut werden. In der Regel läuft dies nicht ohne Probleme ab und zieht weitere Arbeiten nach sich.
Die dann auftretenden Probleme im Build können im günstigsten Fall eine kurze Verzögerung bedeuten, im schlimmsten Fall ungeplante Wartungsarbeiten nach sich ziehen.
Außerdem bedeuten gerade bei Betriebssystemen neue Versionen größere Änderungen im Betrieb, die sorgfältig vorbereitet und eingeplant werden müssen.
Diese Art von Überraschung kann umgangen werden, indem in Dockerfiles bei jedem verwendeten Image stets ein Tag mit angegeben wird, das eine feste Version spezifiziert.
Es sollte also auf Angaben wie »rolling« und »latest« verzichtet werden.
FROM ubuntu:20.04
Zusammenfassung
Während Entwickler zunächst auf Funktionalität bedacht sind, wenn sie in CI-Umgebungen mit dem Erstellen von Docker-Images beginnen, zeigt sich sehr schnell in der täglichen Arbeit, dass weitere Faktoren wichtig sind. Schnelle Rückmeldung durch kurze Durchlaufzeiten und stabiler Betrieb durch reproduzierbare Builds werden mit zunehmender Zeit wichtiger.
Dieser Artikel hat beschrieben, wie durch projektspezifische Images die Durchlaufzeit verringert werden kann. Außerdem wurde gezeigt, wie durch das ausdrückliche Konfigurieren von Softwareversionen planvolle Updates ohne große Überraschungen im Betrieb möglich werden.
Permalink: /2020-10-14-optimierung-von-docker-images
Wie wir unsere Apps betreiben...
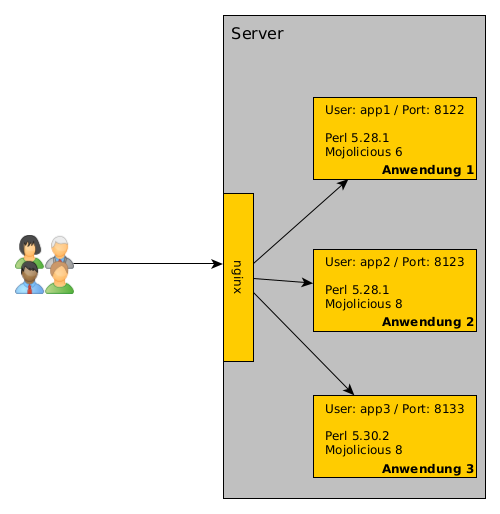
Wir haben bei uns etliche Mojolicious-Anwendungen laufen. Dieses Blog, Perl-Academy.de sind Anwendungen und bei OPMToolbox.de sind es mehrere Anwendungen.
Die liegen teilweise auf dem gleichen Server. Jetzt stellt sich vielleicht die Frage, wie wir das dann betreiben. Die Antwort ist einfach: In der Regel gibt es für jede Anwendung einen eigenen User auf dem Server. Der startet die Anwendung mit hypnotoad. Und es gibt einen nginx, der als Reverse Proxy dient.
Installation der Anwendung
Warum jeweils ein eigener User? Warum alles hinter dem nginx?
Es gibt immer einen eigenen User, weil wir nicht alles mit root oder einem anderen User laufen lassen möchten. Und es hat den Vorteil, dass wir bei jedem User eine eigene Perl-Umgebung aufbauen können. Das heißt, dass wir mit perlbrew mindestens die Perl-Version installieren, mit der die Anwendung entwickelt wurde und auch die Module installieren, die die Anwendung braucht.
Das sieht dann so aus
$ useradd -m -s /bin/bash academy-blog
$ su - academy-blog
$ wget -O - https://install.perlbrew.pl | bash
$ source perl5/perlbrew/etc/bashrc
$ perlbrew install 5.30.2
$ perlbrew use 5.30.2
$ wget -O - https://cpanmin.us | perl - App::cpanminus
$ git clone <academy-blog> blog
$ cd blog
$ cpanm --installdeps .
$ hypnotoad blog
So muss ich auch nicht aufpassen, ob eine neue Mojolicious-Version eine Funktion rausgeschmissen hat oder eine andere Inkompatibilität mit sich bringt. So lange es läuft und an der Anwendung nichts geändert wird, kann die Umgebung so bleiben wie sie ist.
Eine andere Anwendung beeinflusst diese nicht. Egal, ob die andere Anwendung mit einer neuere Mojolicious-Version entwickelt wurde oder es vielleicht auch Module gibt, die sich gegenseitig ausschließen.
Natürlich bringt das unter Umständen mehr Aufwand mit sich, wenn in Modulen Sicherheitslücken auftauchen und dann eben mehrere Installationen angepasst werden müssen. Aber das kommt zum Glück nicht häufig vor.
Damit der User immer gleich das richtige
Perl nutzt, nehmen wir noch eine kleine Änderung in der .bashrc vor: Wir laden dort perlbrew und die richtige Perl-Version:
source /home/academy-blog/perl5/perlbrew/etc/bashrc
perlbrew use 5.30.2
Wie wir sicherstellen, dass die Anwendung auch nach einem Serverneustart automatisch starten, zeige ich in einem späteren Blogpost.
Warum keine Container wie z.B. Docker? Weil wir (noch) nicht dazu gekommen sind, alles in Docker-Container zu packen. Das wird langfristig unser Ziel sein. Sobald wir soweit sind, berichten wir hier auch darüber.
Wenn alles installiert ist und die Anwendung läuft, ist sie von außen noch nicht erreichbar, weil wir die Anwendung immer nur auf 127.0.0.1:#port
lauschen lassen. Es wäre ja auch blöd, wenn die Besucher*innen bei jeder Anwendung auch den Port kennen müssen.
Aus diesem Grund nutzen wir den nginx als Reverse Proxy. Außerdem ist die Nutzung von SSL damit ziemlich einfach.
nginx
Als erstes installieren wir den nginx
$ apt install nginx
Nach der Installation von nginx, packen wir für jede Anwendung eine eigene Konfigurationsdatei in den Ordner /etc/nginx/conf.d.\ Hier ein Beispiel:
upstream academy-blog {
server 127.0.0.1:8080;
}
server {
listen 80;
server_name blog.perl-academy.de;
location /.well-known/acme-challenge {
root /home/academy-blog/letsencrypt/challenge/;
}
location / {
return 301 https://blog.perl-academy.de$request_uri;
}
}
server {
listen 443 ssl;
server_name perl-academy.de www.perl-academy.de;
ssl_certificate /home/academy-blog/letsencrypt/live/blog.perl-academy.de/fullchain.pem
ssl_certificate_key /home/academy-blog/letsencrypt/live/blog.perl-academy.de/privkey.pem;
root /home/academy-blog/web/public/;
try_files $uri @academy_app;
location @academy_app {
proxy_read_timeout 300;
proxy_pass http://academy-blog;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-HTTPS 0;
}
}
Der upstream-Block bestimmt einen anderen Server, an den Anfragen weitergeleitet werden können. Hier nutzen wir einen sprechenden Namen. Es ist zu sehen, dass hypnotoad hier auf Port 8080 lauscht.
Anschließend kommt ein server-Block, der Anfragen auf Port 80 (http) behandelt. Wir legen den Servernamen fest. Es werden also Anfragen auf Port 80 für blog.perl-academy.de behandelt. Innerhalb dieses Blocks gibt es zwei location-Blöcke. Der erste ist wichtig, um später bequem LetsEncrypt-Zertifikate installieren zu können. Der zweit leitet HTTP-Anfragen auf HTTPS um.
Der zweite server-Block sorgt dafür, dass nginx auf Port 443 lauscht und SSL aktiviert ist. So lange die LetsEncrypt-Zertifikate nicht da sind, sollte dieser server-Block deaktiviert/auskommentiert werden.
Wir setzen den root der Dateien auf den public-Ordner der Anwendung. Im Zusammenspiel mit dem try_files sorgen wir dafür, dass statische Dateien nicht über die Mojolicious-Anwendung ausgeliefert werden, sondern direkt vom nginx. try_files prüft, ob eine Datei (die dann in $uri steht) existiert und liefert sie dann aus. Existiert sie nicht, greift der benamte Fallback (hier: @academy_app). Diesen benamten Fallback kann man sich wie eine Subroutine vorstellen. Der Fallback ist dann darauf definiert mit dem location-Block
Das Entscheidende ist die Zeile mit proxy_pass. Die bedeutet, das die Anfragen weitergeleitet werden. Hier taucht auch wieder der Name auf, den wir weiter oben bei upstream definiert haben.
SSL mit LetsEncrypt
Nachdem der nginx läuft, gehen wir den nächsten Schritt an: SSL-Verschlüsselung. Am einfachsten ist es, LetsEncrypt-Zertifikate zu nutzen. Dazu müssen wir certbot installieren:
$ apt install certbot
Anschließend können wir als User die SSL-Zertifikate generieren lassen:
$ su - academy-blog
$ mkdir -p letsencrypt/challenge
$ certbot certonly --config-dir /home/academy-blog/letsencrypt \
--work-dir /home/academy-blog/letsencrypt \
--logs-dir /home/academy-blog/letsencrypt \
-d blog.perl-academy.de
Das Programm führt dann durch die Konfiguration. Da wir in der nginx-Konfiguration schon angegeben haben, wo an welcher Stelle LetsEncrypt auf Dateien zugreifen kann. An diese Stelle soll certbot Dateien packen:
How would you like to authenticate with the ACME CA?
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1: Spin up a temporary webserver (standalone)
2: Place files in webroot directory (webroot)
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Select the appropriate number [1-2] then [enter] (press 'c' to cancel): 2
Plugins selected: Authenticator webroot, Installer None
Enter email address (used for urgent renewal and security notices) (Enter 'c' to
cancel): xxxx@perl-services.de
Man muss noch den Terms of Service
zustimmen und anschließend noch das Verzeichnis, das über nginx erreichbar ist, angeben und dann sollte das Zertifikat erzeugt werden.
Läuft alles durch, kann der server-Block für das SSL in der nginx-Konfiguration wieder aktiviert werden.
Da die LetsEncrypt-Zertifikate nur jeweils 3 Monate gültig sind, müssen diese regelmäßig erneuert werden. Hier empfiehlt es sich, einen Cronjob einzurichten:
$ crontab -e
Und dort
0 5 15,30 * * certbot renew --config-dir ... --work-dir ... --logs-dir ...
eintragen.
Zusammenfassung
Für jede Anwendung nutzen wir einen eigenen User, damit wir komplett eigenständige Umgebungen haben. Die Anwendungen sind hinter\
einem nginx als Reverse Proxy. Für die SSL-Verschlüsselung nutzen wir certbot. In einem Bild zusammengefasst, sieht\
das dann so aus:
Sollten Sie noch Fragen oder Anregungen haben, melden Sie sich einfach.
Permalink: /2020-10-05-wie-wir-apps-betreiben
CPAN-Updates September 2020
Ja, ich weiß dass der September schon vorbei ist. Aber der Inhalt bezieht sich auf das was im September so passiert ist ;-) In den letzten Wochen haben wir wieder ein paar unserer Module auf CPAN aktualisiert. Dieser Artikel gibt einen kurzen Überblick, was sich so getan hat.
Markdown::Table
Markdown::Table ist ein neues Modul, das wir zum Generieren von Tabellen in Markdown nutzen können. Der für uns aktuell wichtigere Teil ist aber das Parsen von Tabellen in Markdown-Dokumenten.
Wir nutzen - wie vielleicht schon bekannt - Nuclino zur Ablage von Informationen. Unter anderem auch für den Redaktionsplan
für dieses Blog. Dort steht in einer Tabelle, wann welcher Artikel geplant ist.
Mit den Daten dieser Tabelle soll ein interner Kalender gepflegt werden, so dass Erinnerungen etc. generiert werden.
Aus der SYNOPSIS:
use Markdown::Table;
my $markdown = q~
This table shows all employees and their role.
| Id | Name | Role |
|---|---|---|
| 1 | John Smith | Testrole |
| 2 | Jane Smith | Admin |
~;
my @tables = Markdown::Table->parse(
$markdown,
);
print $tables[0]->get_table;
OTRS::OPM::Maker::Command::sopm
Wir machen auch ziemlich viel mit der ((OTRS)) Community Edition: Schulungen, Anpassungen und vieles mehr. Für Erweiterungen gibt es im ((OTRS)) einen Paketmanager, der die Pakete in einem bestimmten XML-Format erwartet (sog. OPM-Dateien). Die Spezifikation
für die Pakete wird selbst auch in XML festgehalten. Mir ist das zu aufwendig und schreibe die Meta-Daten in eine JSON-Datei. Die wird dann mit dem sopm-Kommando des Tools opmbuild ausgewertet und die Spezifikationsdatei (.sopm) wird geschrieben.
Neu ist die Unterstützung vom Löschen von Spalten in Tabellen mittels ColumnDrop.
Mojolicious::Plugin::Data::Validate::WithYAML
Vor einigen Tagen habe ich ja Data::Validate::WithYAML vorgestellt. Das aktualisierte Modul ist das passende Mojolicious-Plugin dazu. Damit wird die Validierung der Benutzereingaben zum Kinderspiel.
In der neuen Version nutzen wir die Module, die Mojolicious mitliefert anstelle von File::Spec und File::Basename. Mojo::File ist ein tolles Modul wenn man mit Dateien arbeitet.
Weiterhin gibt es in dem Plugin jetzt eine Unterstützung für steps
in den YAML-Dateien. Damit kann man die gleichen Dateien nutzen, die man bei reiner Data::Validate::WithYAML-Nutzung verwendet.
Permalink: /2020-10-02-cpan-news-september-2020
Akzeptanztests mit Test::BDD::Cucumber
Akzeptanztests sind Tests, die als natürlichsprachliche Szenarien aus Anwendersicht formuliert werden. Sie dienen als lebendige Dokumentation eines Systems und können das gemeinsame Verständnis im Team herstellen. Test::BDD::Cucumber ist eine Distribution, mit der Fehler in Perl-Anwendungen durch die Ausführung von Akzeptanztests gefunden werden können.
Klassische Perl-Tests: von innen nach außen
In Perl sind Unit-Tests weit verbreitet. Oftmals sind diese als einzige Testart nach außen sichtbar, weil sie in CPAN-Distributionen ausgeliefert werden. Mit der CPAN Testers Matrix gibt es eine transparente Möglichkeit, die Ergebnisse der Unit-Tests einzusehen.
Integrations- oder Systemtests sind bei weitem nicht so bekannt in der Perl-Welt, weil es hierfür weder ein einheitliches Framework noch eine ähnlich transparente Plattform gibt.
Unit-Tests arbeiten »von innen nach außen« (»inside-out«): Die Units bilden die untersten Bausteine, aus denen Anwendungen erstellt werden. Unit-Tests sind gut geeignet für die testgetriebende Entwicklung von Units und üblicherweise schnell in der Ausführung. Deswegen ist es praktisch möglich und ratsam, eine hohe Testabdeckung durch eine Vielzahl von Testfällen zu erreichen.
Akzeptanztests: von außen nach innen
In der Softwaretechnik gibt es die Disziplin des »behaviour driven development« (BDD), in der Akzeptanztests ein Bestandteil sind.
Diese Art von Systemtests heißt so, weil mit ihnen die Bedingungen geprüft werden, unter denen ein Anwender die Umsetzung der Software akzeptiert. Sie sind natürlichsprachlich aus Sicht des Anwenders formuliert.
Da Anwender in Funktionalitäten denken, werden Akzeptanztests pro Feature geschrieben. Sie bestehen aus Szenarien, die exemplarisch die Verwendung der Software im Rahmen eines Features beschreiben.
Es wird das vollständig integrierte System »von außen nach innen« (»outside-in«) getestet.
Da das vollintegrierte System getestet wird, sind diese Test langsam. Es werden daher nur einzelne bespielhafte Fälle – die Szenarien – getestet.
Akzeptanztests passen gut zu testgetriebener Entwicklung einer Anwendung. In dieser Vorgehensweise spezifiziert man erst das Verhalten der Software aus Sicht des Anwenders in Szenarien und implementiert anschließend das Feature. Die Szenarien helfen beim Konzentrieren auf das Wesentliche eines Features.
Beispiel
Wie sieht nun ein solcher Akzeptanztest aus? Das folgende Beispiel zeigt ein Szenario eines erfolgreichen Logins.
Feature: Login
Scenario: User logs in providing correct credentials
Given I am an existing user
When I log in providing the correct password
Then the login succeeds
And I am at the dashboard page
Szenarien werden nach dem Schema »Arrange, Act, Assert« (AAA) mit der Given-When-Then-Schablone geschrieben. Das Szenario beschreibt aus der Sicht der Benutzers die wesentliche Funktionalität: Nach einem erfolgreichen Login wird der Benutzer auf sein Dashboard geleitet.
Der »Given«-Schritt entspricht »Arrange«, in dem die Voraussetzungen für den Test geschaffen werden. In diesem Fall wird das getestete System so verändert, dass ein Benutzer existiert.
Der »When«-Schritt entspricht »Act«. Hier wird die zu testende Funktionalität ausgeführt.
Im abschließenden »Then«-Schritt (»Assert«) werden die erwarteten Ergebnisse geprüft.
Technische Umsetzung mit Test::BDD::Cucumber
Die Ausführung solcher Szenarien kann in Perl mit einer Reihe von Distributionen erfolgen. Die ausgereifteste ist Test::BDD::Cucumber. Die Akzeptanztests werden standardmäßig im Verzeichnis t/features abgelegt. Szenarien eines Features werden in einer Datei beschrieben, die auf .feature endet.
Die einzelnen Schritte werden als Zeichenketten mit regulären Ausdrücken geprüft. Welche dies sind, legen die Entwickler über Subroutinenaufrufe fest. Diese werden in allen Dateien im Verzeichnis t/features/step_definitions erwartet.
Für unser oben gezeigtes Szenario könnte die Deklaration der einzelnen Schritte wie folgt aussehen:
Given qr{there is an existing user} => sub {
my $context = shift;
# Benutzer anlegen
...
};
When qr{I log in providing the correct password} => sub {
my $context = shift;
# Anmeldung mit korrektem Passwort durchführen
...
};
Then qr{the login succeeds} => sub {
my $context = shift;
# prüfen, ob Login erfolgreich war
...
};
Then qr{I am at the dashboard page} => sub {
my $context = shift;
# prüfen, ob Dashboard angezeigt wird
...
};
Jeder Schritt wird durch diese regulären Ausdrücke geprüft. Bei einer Übereinstimmung wird der entsprechende Code ausgeführt.
Wie im Beispiel zu sehen ist, wird an die Subroutine der Kontext übergeben, in dem der Code ausgeführt wird. Über diesen Kontext können Informationen zwischen den Schritten ausgetauscht werden, ohne auf globale Zustände zugreifen zu müssen. In unserem Beispiel würde hier zum Beispiel der angelegte Benutzer übergeben werden, so dass Name und Passwort nicht fest im Code verdrahtet werden müssen.
Der jeweilige Then-Schritt prüft den erwarteten Zustand mit den aus Test::More bekannten Werkzeugen.
Die Akzeptanztests werden mit dem Werkzeug pherkin in der Shell aufgerufen. Bei der Ausführung eines Test werden alle Schritte ausgegeben. Fehler werden laut und deutlich in der Konsole gemeldet:
$ pherkin -Ilib t/features/login.feature
Feature: Login
Scenario: User logs in providing correct credentials
Given I am an existing user
When I log in providing the correct password
Then the login succeeds
step defined at t/features/login.feature line N.
ok - Starting to execute step: the login succeeds
not ok 1
# Failed test at ...
In den »Then«-Schritten können alle Test::Builder-basierten Testwerkzeuge verwendet werden, die die Entwickler auch sonst in ihren Unit-Tests einsetzen.
Die obigen Beispiele können nur skizzenhaft das Vorgehen zeigen. Die Test::BDD::Cucumber-Distribution enthält einige lauffähige Beispiele, die konkret die Funktionalität der Distribution zeigen.
Vorteile von Akzeptanztests
Durch das Verwenden von Akzeptanztests ist das Team gezwungen, sich aus der Sicht der Benutzer der Implementierung zu nähern. Dadurch wird häufig deutlich, dass das Wesentliche der Umsetzung einer Software in der Regel nicht in den grafischen Details liegt, sondern vielmehr in der Funktionalität, die der Benutzer erwartet.
Das Team formuliert die Szenarien in einer allgemeinen Sprache (»ubiquitäre Sprache«) der Anwendungsdomäne. Da dieses bereits bekannte Vokabular verwendet wird, kann das gemeinsame Verständnis über die Funktionsweise der Software erhöht werden. Da die Tests zudem ausführbar sind, erhält das Team so eine ausführbare, lebendige Dokumentation des tatsächliche funktionierenden Systems.
Akzeptanztests testen die lauffähige Software mit all ihren Komponenten und nicht nur einzelne Teile. Sie sind daher sehr gut dazu geeignet, um nach Abschluss von Unit- und Integrationstests Fehler in der Zusammenarbeit aller Softwarebausteine einer Anwendung zu finden.
Abschließend führe ich noch einige bewährte Vorgehensweisen auf, um diese Vorteile tatsächlich nutzen zu können.
Best Practices
- Szenarien sollen allgemein formuliert werden und keine Details erwähnen, da die Tests sonst sehr brüchig sind.
- Szenarien sollen nur exemplarisch formuliert werden, da Akzeptanztests langsam sind. Es sollen nicht alle Testfälle abgedeckt werden; hierfür sind Unit-Tests besser geeignet.
- Die Szenarien sollen in dem im Team verwendeten Vokabular formuliert werden, um darüber das gemeinsame Verständnis zu erhöhen.
- Das Team sollte möglichst früh mit Akzeptanztests beginnen, da darüber schnell ein Prototyp der Anwendung erstellt werden kann und so testbarer Code entsteht.
- Szenarien sollen aus Benutzersicht geschrieben werden. Darin wird die Software wie durch einen Benutzer bedient:
- Wenn die getestete Software ein REST-Server, wird ein REST-Client verwendet.
- Wenn die getestete Software eine Webanwendung, wird ein Browser ferngesteuert.
- Wenn die getestete Software ein Kommandozeilenwerkzeug, dann wird dieses wirklich aufgerufen und STDOUT und STDERR ausgewertet.
- Es sollen keine Komponente gemockt werden, sondern die Anwendung soll in einer Testumgebung laufen.
Zusammenfassung
Das Testen mit Akzeptanztests erfordert im Team einiges Umdenken im Vergleich zum Testen mit Unit-Tests. Es wird aber damit belohnt, dass im Ergebnis eine lebendige und ausführbare Dokumentation des Systems vorliegt. Diese Dokumentation wurde mit einem gemeinsamen Vokabular verfasst, das das gemeinsame Verständnis ermöglicht.
Test::BDD::Cucumber ist eine Distribution, mit der Akzeptanztests in Perl geschrieben werden können. Die Distribution kann verwendet werden, um nach der erfolgreichen Ausführung von Unit-Tests Fehler im voll integrierten System zu finden.
Weiterlesen
- Test::BDD::Cucumber – Die Distribution auf CPAN
- Tutorial zur Distribution
- pherkin – Anleitung des Kommandozeilenwerkzeugs
- Artikel zum »behavior driven design« (Wikipedia)
- die Ubiquitäre Sprache im »domain driven design« (Wikipedia)
- Integrations- und Systemtests im V-Modell (Wikipedia)
- Arrange-Act-Assert (C2-Wiki)
- deutsche Übersetzung einer Einführung in BDD von seinem Erfinder Dan North
Nuclino-Backup mit Mojolicious - Teil 2
Im ersten Teil habe ich gezeigt, wie wir mit Mojolicious das Login umsetzen und die sogenannten Brains von Nuclino als zip-Archiv holen. Jetzt geht es zum einen darum, die Inhalte als einzelne Markdown-Dateien abzulegen und in unserem Gitlab zu speichern und zum anderen die Abarbeitung zu beschleunigen.
Fangen wir mit dem Entpacken an... Hier nutzen wir Archive::Zip
# siehe Blogpost vom 15.08.2020
my ($info,@brains) = _get_brains( $ua );
my @zips = _download_backups( $ua, \@brains );
# ab hier ist es neuer Code
_extract_backups( \@zips );
_commit_and_push( $home_dir );
sub _extract_backups {
my $zips = shift;
say 'Extract backups ...';
my $obj = Archive::Zip->new;
for my $zip ( @{ $zips || [] } ) {
$obj->read( $zip->to_string );
$obj->extractTree('', $zip->dirname->to_string );
}
$_->remove for @{ $zips || [] };
}
Jedes einzelne zip-Datei wird eingelesen und der Inhalt wird in den backups-Ordner entpackt. Wir verzichten auf das Kommandozeilentool unzip, weil wir die Perl-Abhängigkeiten in einem cpanfile beschreiben können und nicht daran denken müssen das Tool zu installieren.
sub _commit_and_push {
my $home_dir = shift;
my $git = Git::Repository->new(
work_tree => $home_dir->to_string,
);
say "commit the changes";
$git->run(qw/add --all backups/);
my $date = Mojo::Date->new->to_datetime;
$git->run("commit", "-m", "nuclino backup $date") ;
$git->run(qw/push origin master/);
}
Zur Interaktion mit git nehmen wir Git::Repository, damit wir uns nicht um das Wechseln in Verzeichnisse etc. kümmern müssen. Die einzelnen run-Befehle enthält die gleichen Parameter wie git-Kommandos im Terminal.
Damit hätten wir ein Backup unserer Nuclino-Dokumente in einem git-Repository. Jetzt kümmern wir uns um Kleinigkeiten
.
Die Laufzeit spielt in diesem Skript nicht wirklich eine Rolle, da der aktuelle Stand nur einige Male am Tag geholt wird, ist es dann egal ob das Skript 10 oder 20 Sekunden läuft. Wir wollen aber die Möglichkeiten von Mojolicious nutzen.
Um die Zeit optimal zu nutzen, sollen mehrere Brains parallel abgeholt werden. Mit dem Committen der Änderungen muss allerdings gewartet werden, bis die zip-Dateien aller Brains abgeholt und entpackt wurden.
Zum Parallelisieren und wieder zusammenführen, nutzen wir Promises. Der Mojo::UserAgent hat schon entsprechende Methoden parat, mit denen Promises erzeugt werden können. Auf Promises werde ich auch in einem späteren Blogpost noch näher eingehen.
Bildlich dargestellt, soll das Ergebnis sich folgendermaßen verhalten:
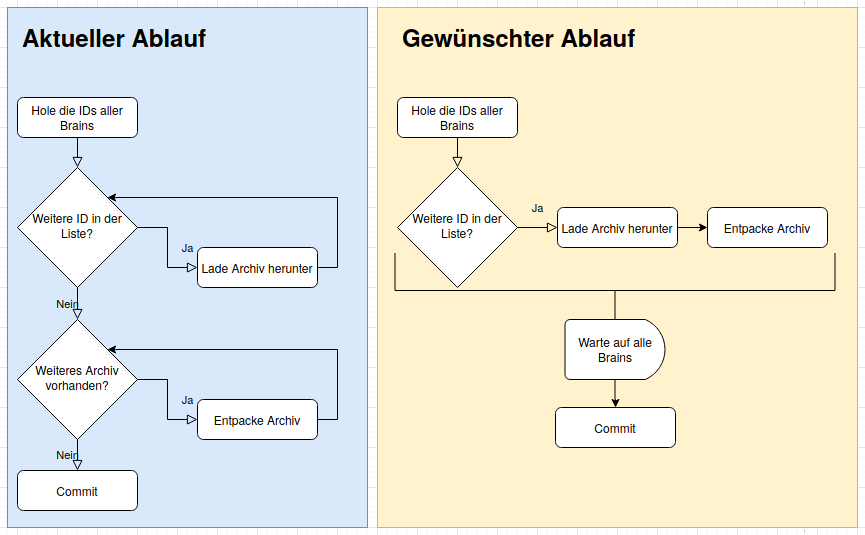
Durch die Promises stößt man das Herunterladen des Archivs an und ohne auf das Ergebnis zu warten, geht man zum nächsten Brain weiter. Damit das Programm aber nicht weitermacht bis alle Archive heruntergeladen und entpackt sind, benötigt man einen Mechanismus, der auf die ganzen Promises wartet.
Um parallel zwei URLs abzurufen und die Titel der Seiten auszugeben, kann man dieses einfache Programm nehmen.
#!/usr/bin/perl
use Mojo::Base -strict;
use Mojo::UserAgent;
my $ua = Mojo::UserAgent->new;
for my $url ( qw/perl-academy.de perl-services.de/ ) {
$ua->get_p( "https://www." . $url )->then( sub {
my ($tx) = @_;
say $tx->res->dom->find('title')->first->text;
})->wait;
}
An die bekannten Methoden wie get, post usw. wird einfach das _p angehängt und man bekommt ein Objekt vom Typ Mojo::Promise zurück. Wird kein Fehler geworfen, wird die Subroutine ausgeführt, die man der Methode then übergibt. Möchte man einen Fehler abfangen, muss man die Methode catch verwenden.
Um die Mojo-eigene Eventloop zu starten (und zu stoppen wenn der Promise erfüllt wurde) wird anschließend noch wait aufgerufen.
In dem Callback, den ich hier der Methode then übergebe wird einfach aus der Antwort ($tx->res) das DOM geholt, dort nach dem title-Tag gesucht und den Text des ersten Treffers ausgegeben.
Übertragen auf unser Nuclino-Backup rufen wir das Archiv des Brains nicht mehr mit get ab, sondern mit get_p. Wir warten nicht, bis alle Archive geholten wurden, bis diese entpackt werden. Das machen wir für das jeweilige Archiv wenn der Promise erfolgreich aufgelöst wurde (then).
Allerdings wollen wir den commit erst machen, wenn alle Archive geholt wurden.
Unser obiges Beispiel sieht entsprechend angepasst so aus:
#!/usr/bin/perl
use Mojo::Base -strict;
use Mojo::UserAgent;
use Mojo::Promise;
my $counter = 0;
my $ua = Mojo::UserAgent->new;
my @promises;
for my $url ( qw/perl-academy.de perl-services.de/ ) {
my $promise = $ua->get_p( "https://www." . $url )->then( sub {
my ($tx) = @_;
say $tx->res->dom->find('title')->first->text;
$counter++;
});
push @promises, $promise;
}
Mojo::Promise->all( @promises )->then( sub {
say "Found $counter titles";
})->wait;
Um zu zeigen, dass wirklich auf beide Abfragen gewartet wird, habe ich einen Zähler eingebaut. Wir nutzen auch kein wait beim get_p-Aufruf. Um auf eine Reihe von Promises zu warten nutzen wir all von Mojo::Promise. Das selbst wieder ein Promise zurückliefert. Wenn dieses all-Promise erfolgreich ist, wird der Callback ausgeführt, der bei then übergeben wird.
Der angepasste Code in unserem Programm sieht dann so aus:
# siehe Blogpost vom 15.08.20
my ($info,@brains) = _get_brains( $ua );
my @promises = _download_backups( $ua, \@brains );
Mojo::Promise->all( @promises )->then( sub {
_commit_and_push( $home_dir );
})->wait;
sub _download_backups {
my $ua = shift;
my $brains = shift;
say 'Download backups...';
my @promises;
my $backup_path = path(__FILE__)->dirname->child('..', 'backups')->realpath;
$backup_path->remove_tree({ keep_root => 1 });
for my $brain ( @{ $brains || [] } ) {
say '... for brain ' . $brain;
my $url = sprintf 'https://files.nuclino.com/export/brains/%s.zip?format=md', $brain;
my $promise = $ua->get_p(
$url
)->then( sub {
my ($tx_backup) = @_;
my $dir = $backup_path->child( $brain );
$dir->make_path;
my $zip_file = $dir->child( $brain . '.zip' );
$tx_backup->res->save_to( $zip_file->to_string );
_extract_backups( $zip_file->to_abs );
});
push @promises, $promise;
}
return @promises;
}
Es wird noch einen dritten Teil der Reihe geben, weil wir mittlerweile das Backup als Datenquelle für andere Anwendungen nutzen und dafür weitere Arbeiten nötig waren.
Permalink: /2020-09-22-nuclino-backup-II
Modul des Monats: Data::Validate::WithYAML
Schon relativ früh in der Webentwicklung merkt man: Benutzereingaben sind böse! Man sollte ihnen einfach nicht vertrauen. Es muss ja nicht immer gleich eine Sicherheitslücke entstehen, es reicht schon, wenn Nutzer:innen einfach falsche Daten eingeben, die eine Weiterverarbeitung unmöglich machen.
Aus diesem Grund nehmen wir mal ein eigenes Modul als Modul des Monats
: Data::Validate::WithYAML
Dieses Modul ist nicht mehr ganz so jung (erster Commit in Github ist von 2008 – und das war ein Import vom CVS-Repository), aber es ist bei uns immer noch in etlichen Anwendungen im Einsatz. Auf unseren Webseiten gibt es verschiedene Formulare, wie das typische Kontaktformular oder das Bestellen von Demoinstanzen unserer Erweiterungen für die ((OTRS)) Community Edition.
Ich habe keines der damals existierenden Module genommen, weil ich bei Änderungen am Formular und/oder Erkenntnissen was valide
ist ohne Code-Änderungen in der Überprüfung der Formularinhalte übernehmen wollte.
Nehmen wir mal ein Formular zur Anmeldung Hundesteuer:
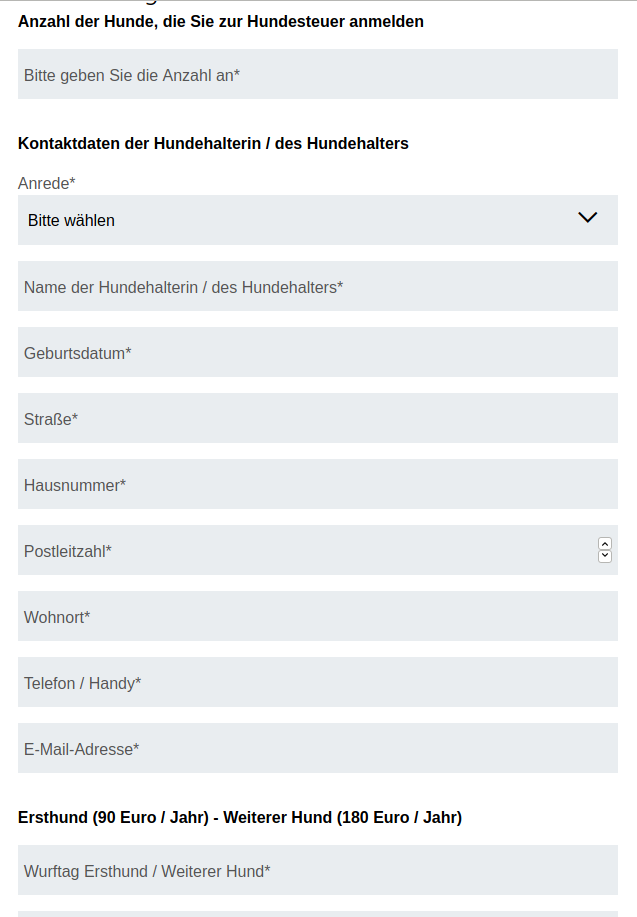
Das ist ein bunter Mischmasch an erlaubten Werten in den Feldern... Das muss alles geprüft werden. Im ersten Feld (Anzahl der Hunde) wird es eine natürliche Zahl sein. Bei der Anrede gibt es eine Auswahl an Werten, der Name ist ziemlich frei, bei der Adresse könnte man prüfen, ob diese tatsächlich existiert und für die E-Mail-Adressen gibt es auch Regeln.
YAML ist ein tolles Format für Konfigurationsdateien. Aus diesem Grund beschreiben wir die Regeln für die Felder in einer YAML-Datei. In dem Dokument muss das Formular angegeben werden und dort die einzelnen Felder.
---
name_des_formulars:
feld1:
...
feld2:
...
Bei der Definition gibt man dann an, ob es ein Pflichtfeld ist oder nicht
---
name_des_formulars:
feld1:
type: required
...
feld2:
type: optional
...
Alle weiteren Angaben bei den Feldern beschreiben die Regeln für dieses Feld. In dem Modul sind schon einige Regeln definiert:
regex
Der eingegebene Wert muss dem regulären Ausdruck entsprechen.
not_regex
Der eingegebene Wert darf nicht dem regulären Ausdruck entsprechen. Wir nutzen das z.B., um Spam zu finden.
min
Der eingegebene Wert muss größer sein als der bei min angegebene Wert.
max
Der eingegebene Wert muss kleiner sein als der bei max angegebene Wert.
enum
Eine Liste von gültigen Werten.
length
Die Länge des eingegebenen Wertes muss dem Längenbereich entsprechen...
length: 1,... der Wert muss mindestens 1 Zeichen lang sein.
length: 3,5... der Wert muss zwischen 3 und 5 Zeichen (Grenzen eingeschlossen) lang sein.
length: ,5... der Wert darf maximal 3 Zeichen lang sein.
length: 3... der Wert muss exakt 3 Zeichen lang sein.
datatype
Für einige Datentypen gibt es auch schon vorgefertigte Prüfungen:
- num
- int
- positive_int
Mit diesen grundlegenden Regeln kommt man bei dem obigen Formular schon ein Stück weiter:
---
hundesteuer:
anzahl_hunde:
type: required
min: 1
datatype: positive_int
anrede:
type: required
enum:
- Herr
- Frau
- ''
name:
type: required
length: 3,
geburtsdatum:
type: required
regex: ^[0-9]+\.[0-9]+\.[0-9]+$
wohnort:
type: required
length: 2,
email:
type: required
regex: \@[\w\.]+
Das ist mit Sicherheit noch nicht optimal, denn ergibt es Sinn, dass jemand 1.000 Hunde anmeldet? Es wäre ein Geburtsdatum 9999.13913.1 möglich oder dass eine Adresse angegeben wird, die gar nicht existiert. E-Mailadressen mit einem so einfachen regulären Ausdruck zu prüfen ist nicht die beste Idee.
Aus diesem Grund gibt es noch weitergehende Möglichkeiten, eine der wichtigsten ist die Benutzung von Plugins. Für E-Mail-Adressen gibt es beispielsweise schon fertige Plugins wie Data::Validate::WithYAML::Plugin::EmailMX.
email:
type: required
plugin: EmailMX
Weiterhin ist es möglich, mehrere Regeln zu kombinieren. So könnte man bei der Mail z.B. den regulären Ausdruck, eine Mindestlänge und das Plugin verwenden:
email:
type: required
regex: \@[\w\.]+
length: 6,300
plugin: EmailMX
Zu jedem Feld kann man auch noch eine message angeben, die im Fehlerfalle von validate zurückgegeben wird.
Sind die Regeln für das Formular in der YAML-Datei hinterlegt, kann man das Formular validieren:
use Data::Validate::WithYAML;
use Data::Printer;
my $validator = Data::Validate::WithYAML->new(
$path_to_yaml_config,
);
# Simulation der Benutzereingaben
my %input_hash = (
anrede => 'Herr',
anzahl_hunde => 1,
name => 'Franziska Meier',
);
my %errors = $validator->validate( step1 => %input_hash );
p %errors;
Für die Verwendung von Data::Validate::WithYAML in Mojolicious gibt es auch ein entsprechendes Plugin. Damit wird die Verwendung weiter vereinfacht. Die YAML-Datei bleibt die gleiche. In der Mojolicious-Anwendung wird das Plugin geladen:
#!/usr/bin/env perl
use Mojolicious::Lite;
plugin 'Data::Validate::WithYAML' => {
conf_path => app->home . '/conf'
};
get '/' => 'hundesteuer_form';
post '/' => sub {
my ($c) = shift;
my %errors = $c->validate( 'form' => 'step1' );
if ( %errors ) {
$c->stash( errormsgs => \%errors );
return $c->render('hundesteuer_form');
}
$c->render( data => $c->dumper( $c->req->params ) );
};
app->start;
__DATA__
@@ hundesteuer_form.html.ep
... Code siehe Gitlab-Repository ...
Das Mojolicious-Plugin stellt die Methode validate zur Verfügung. Dort gibt man nur noch den Dateinamen (ohne .json) an. Wenn alles ok ist, liefert die Methode nichts zurück, ansonsten gibt es einen Hash mit den Fehlern.
Dieser Code ist auch im Repository vorhanden.
Permalink: /2020-09-15-data-validate-withyaml
DBIx::Class::DeploymentHandler und lange Indexnamen
Wir nutzen in verschiedenen Projekte DBIx::Class als Abstraktionsschicht für die Datenbank. Das Schema der Datenbank entwickeln wir mit dem Tool MySQL-Workbench und die daraus resultierende Datei nutzen wir zur Code-Generierung wie in einem früheren Blogpost beschrieben.
Mit diesem generierten Code liefern wir auch die Änderung an der Datenbank aus. Dazu nutzen wir das Modul DBIx::Class::DeploymentHandler. Das funktioniert echt einfach:
use DBIx::Class::DeploymentHandler;
use Projekt::Schema; # DBIx::Class Schema
my $db = Projekt::Schema->connect(
'DBI:Pg:dbname=projekt_db;host=unser.projekt.host',
'db_user',
'db_password',
);
my $deployer = DBIx::Class::DeploymentHandler->new({
schema => $db,
script_directory => '/path/to/db_upgrades',
databases => ['Pg'],
force_overwrite => 1,
sql_translator_args => {
quote_identifiers => 1,
},
});
$deployer->prepare_install;
$deployer->install;
Wir instanziieren erst das Schema der Datenbank. Anschließend erzeugen wir ein Objekt um die Änderungen an der Datenbank auszurollen. Das Objekt benötigt noch den Pfad zu einem Verzeichnis in dem die Änderungsanweisungen gespeichert werden.
Bei prepare_install werden die YAML-Dateien in *db_upgrades *erstellt. In diesem YAML-Dateien ist eine Beschreibung der Datenbank: Welche Tabellen mit welchen Spalten gibt es. Weiterhin werden SQL-Dateien erstellt, die für die Datenbank passend die SQL-Befehle enthält.
Mit install werden dann die Änderungen in der Datenbank ausgerollt.
Und dabei sind wir auf ein Problem gestoßen, denn bei der Installation der Datenbank haben wir jede Menge Warnungen bekommen:
NOTICE: identifier "common_internal_workphase_activity_idx_common_internal_workphase_id" will be truncated to "common_internal_workphase_activity_idx_common_internal_workphas"
NOTICE: identifier "common_project_workphase_activity_idx_common_project_workphase_id" will be truncated to "common_project_workphase_activity_idx_common_project_workphase_"
NOTICE: identifier "contract_remuneration_engineering_idx_contract_remuneration_engineering_facilitygroup_id" will be truncated to "contract_remuneration_engineering_idx_contract_remuneration_eng"
NOTICE: identifier "contract_remuneration_facilitygroup_costgroup_idx_contract_remuneration_engineering_facilitygroup_id" will be truncated to "contract_remuneration_facilitygroup_costgroup_idx_contract_remu"
NOTICE: identifier "contract_remuneration_engineering_costgroup_idx_contract_remuneration_engineering_id" will be truncated to "contract_remuneration_engineering_costgroup_idx_contract_remune"
Ursache ist, dass in PostgreSQL die Identifier nicht länger als 63 Zeichen sein. Sind sie es doch, werden sie gekürzt. Jetzt haben uns zwei Fragen beschäftigt:
- Können wir längere Identifier erlauben?
- Wo kommen die langen Namen eigentlich her?
Die erste Frage war relativ schnell beantwortet: Ja, geht. Aber dazu muss man PostgreSQL selbst kompilieren, da die maximale Länge im Quellcode hinterlegt ist (Immerhin, mit Closed Source hätte man nicht mal die Chance die Änderungen vorzunehmen und die Software neu zu bauen 😉 ). Mehr dazu gibt es in der Postgres-Doku.
Die zweite Frage war etwas schwieriger zu beantworten. Wir haben diese Identifier nirgends definiert. Also mussten wir nachvollziehen, wie DBIx::Class::DeploymentHandler arbeitet.
Da der fehlerhafte Befehl in der SQL-Datei erstmals auftaucht, musste es beim Erstellen der SQL-Befehle passieren. Das SQL kommt von dem Modul SQL::Translator, und der Index wird in der Methode add_index aus SQL::Translator::Schema::Table erstellt.
Letztendlich war die Lösung relativ einfach: Wir überschreiben einfach genau diese Methode:
use SQL::Translator::Schema::Table;
use Digest::MD5 qw(md5_hex);
{
no warnings 'redefine';
my %indexes;
sub SQL::Translator::Schema::Table::add_index {
my $self = shift;
my $index_class = 'SQL::Translator::Schema::Index';
my $index;
if ( UNIVERSAL::isa( $_[0], $index_class ) ) {
$index = shift;
$index->table( $self );
}
else {
my %args = @_;
$args{'table'} = $self;
my $md5 = md5_hex( $args{$name} );
$args{name} = 'idx__' . $args{table} . '__' . $md5;
$index = $index_class->new( \%args ) or return
$self->error( $index_class->error );
}
foreach my $ex_index ($self->get_indices) {
return if ($ex_index->equals($index));
}
push @{ $self->_indices }, $index;
return $index;
}
}
Das ist das Schöne an Perl: Man kann Lösungen finden und anwenden ohne dass man den ursprünglichen Code anfasst. Hier nutzen wir die Möglichkeit, Subroutinen von jeder beliebigen Stelle aus für alle möglichen Namensräume zu definieren. Dazu muss nur der Vollqualifizierte
Name der Subroutine angegeben werden.
Das einzige was wir beachten müssen ist, dass wir das Modul SQL::Translator::Schema::Table laden bevor wir die Subroutine definieren, denn sonst würde die Methode aus dem Modul unsere Subroutine wieder überschreiben.
Solche Änderungen sollten aber immer das letzte Mittel sein, da das Überschreiben von Subroutinen an ganz anderen Stellen als sie eigentlich definiert wurden, zu längeren Debugging-Sitzungen führen kann wenn mal Fehler auftreten.
Permalink: /2020-09-07-dbix-class-deployment-handler
Neues OpenSource-Commitment: Perl::Critic und Abhängigkeiten
Aus unseren Unternehmenswerten, die wir in einem internen Wiki aufgeschrieben haben:
Förderung von Open Source. Wir nutzen Open Source und wollen etwas an die Gemeinschaft zurückgeben. Im Speziellen wollen wir uns um Perl kümmern, da uns viel an der Sprache und der Community liegt.
Wir machen schon relativ viel. So haben Gregor und Renée schon einige CPAN-Module veröffentlicht (die zum Teil in Zukunft in unserem Account PERLSRVDE auftauchen werden), helfen bei der Organisation des Deutschen Perl-Workshops und betreiben eine Art CPAN für ((OTRS)) Community Edition Erweiterungen.
Vor kurzem haben wir beschlossen, dass wir noch mehr machen wollen. Es ist jetzt vorgesehen, dass jeder von uns pro Quartal mindestens an einen Ticket bei Perl::Critic und dessen Abhängigkeiten arbeiten wird.
Klingt nicht viel, aber es ist ein weiterer Punkt, um unsere Unternehmenswerte zu leben. Und irgendwann müssen wir auch noch Geld verdienen...
Wir werden hier über unsere Arbeiten berichten. Die ersten Sachen haben wir auch schon gemacht. Bei der Ursachensuche zu Perl-Critic/Perl-Critic#917 bin ich darauf gestoßen, dass format in PPI falsch geparst wird und habe dann einen entsprechenden Fix geschrieben, der leider noch nicht integriert wurde. Außerdem wurde der Pull-Request #922 angenommen.
Permalink: /2020-09-04-neues-opensource-committment
Wie nutzen wir Gitlab?
Gitlab ist eine webbasierte Plattform für die kontinuierliche Auslieferung von Software. Diese Plattform bietet viele Funktionen, die über die reine Softwareentwicklung und das Deployment hinausgehen. Wir erstellen damit Perl-Distributionen, Docker-Images sowie Dokumentation.
Hauptteil
Gitlab ist eine webbasierte Plattform für die kontinuierliche Auslieferung von Software. Unter anderem integriert es Komponenten wie ein Wiki, ein Ticket-System und die Unterstützung des Versionskontrollsystems Git. Außerdem bietet es eine automatisierte Ausführung von beliebigem Code in Docker-Images an, die von Commits ausgelöst werden können.
Welche Befehle ausgeführt werden, kann man in einer YAML-Datei beschreiben. Dort wird auch beschrieben, welches Docker-Image dafür verwendet werden soll und unter welchen Bedingungen die Befehle ausgeführt werden sollen.
Wie wir bei Perl-Services diese Möglichkeiten nutzen, beschreibe ich in diesem Artikel.
Automatisiertes Erstellen von Perl-Distributionen
Als wir begonnen haben, Gitlab zu evaluieren, haben wir zunächst kleinere Perl-Distributionen als Projekt angelegt und die Git-Repositorys eingebunden. In den YAML-Dateien dieser Projekte haben wir dann konfiguriert, dass nach jedem Commit die Unit-Tests ausgeführt werden und zum Abschluss die Perl-Distribution paketiert werden sollen. Hier ein Auszug aus einem mittlerweile so nicht mehr existenten Projekt:
image: ubuntu:rolling
build:
script:
- apt-get update -qq
- cpanm --installdeps .
- dzil authordeps | cpanm
- dzil listdeps | cpanm
- dzil build
artifacts:
when: always
name: "${CI_BUILD_STAGE}_${CI_BUILD_REF_NAME}"
paths:
- *.tar.gz
Unser Ansatz war zunächst, Fehler durch Tests zu finden und bei erfolgreichem Testdurchlauf die Perl-Distribution zu erstellen. Die benötigten Abhängigkeiten haben wir mit cpanm installiert. Dabei haben wir festgestellt, dass wir gerne schneller Rückmeldung erhalten würden. Dies führte dann dazu, dass wir die Build-Pipeline optimiert haben.
Verkürzte Durchlaufzeiten erreichen wir einerseits durch eine Anpassung der Befehle, andererseits aber auch dadurch, dass wir ein Docker-Image verwenden, das für diese Distribution optimiert ist und bereits alle Abhängigkeiten enthält.
Was sind die nächsten Schritte? Wir prüfen, ob wir die erfolgreich gebauten Distributionen automatisiert in einen Pinto-Server laden oder auf CPAN veröffentlichen.
Erzeugen von Docker-Images
Im vorherigen Abschnitt habe ich erwähnt, dass wir Docker-Images für die Entwicklung von Perl-Distributionen optimieren. Wir wollen dafür alle Abhängigkeiten einer Perl-Distribution in einem Docker-Image zur Verfügung stellen, damit wir die Durchlaufzeit der Perl-Distribution klein halten und dann schnell Rückmeldung nach einem Commit bekommen.
Wie haben wir dies mit Gitlab erreicht? Wir setzen Dist::Zilla ein und beschreiben Abhängigkeiten über dessen Konfiguration dist.ini und das cpanfile. Im verwendeten Docker-Image werden diese darüber beschriebenen Abhängigkeiten mit cpanm installiert.
Dafür haben wir Gitlab so konfiguriert, dass bei einer Änderung dieser Dateien im Master-Branch der Perl-Distribution das verwendete Docker-Image neu erstellt wird. Hier ein beispielhafter Auszug aus einer Gitlab-Konfiguration:
trigger_image_build:
stage: trigger
script:
- curl --request POST --form "token=$CI_JOB_TOKEN" --form ref=master https://gitlab.com/api/v4/projects/9398220/trigger/pipeline
only:
refs:
- /^master$/
changes:
- cpanfile
- dist.ini
Die Beschreibungen der Abhängigkeiten werden beim Erstellen des Docker-Images aus dem abhängigen Projekt gelesen. Hier ein beispielhafter Auszug aus einem Dockerfile:
RUN cd /home/mydocker/src && \
git clone https://gitlab-ci-token:${CI_TOKEN}@gitlab.com/perlservices/project.git && \
[...]
RUN cd /home/mydocker/src/project && \
cpanm --skip-satisfied --installdeps . && \
dzil authordeps --missing | cpanm --skip-satisfied && \
dzil listdeps | cpanm --skip-satisfied
Die Gitlab-Dokumentation hat uns hier teilweise eher verwirrt als geholfen, aber letzten Endes haben wir ein perfekt abgestimmtes Image erhalten, in dem alle Abhängigkeiten enthalten sind. Dadurch können in dem Projekt, das auf diesem Image basiert, nach einem Commit sofort die Unit-Tests ausgeführt werden können.
Die Durchlaufzeiten sind daher sehr gering und liegen bei einem gehosteten Gitlab-Repository bei etwa drei Minuten. Der Löwenanteil dieser drei Minuten liegt darin begründet, dass wir auf einen freien Gitlab-Runner warten müssen.
Um die Durchlaufzeiten weiter zu verringern, migrieren wir die Repositorys derzeit auf einen eigenen Gitlab-Server.
Hinweis: Das müssen wir wegen dem Fall des Privacy Shields ohnehin machen 🙂
Dokumentation erstellen
Die in Projekten zu erstellende Dokumentation reicht je nach Wunsch des Kunden von kurzen Beschreibungen über HTML-Dateien bis zu sauber mit LaTeX gesetzten Dokumenten. Das Ausgangsformat der Dokumente ist für uns stets Markdown, da dies einfach zu schreiben ist, wir uns auf das Wesentliche konzentrieren können und alle gewünschten Zielformate erzeugt werden können.
In Gitlab erzeugen wir mit pandoc aus den Quelldateien das Zielformat. Gegebenenfalls verarbeiten wir das Resultat automatisiert weiter. Wenn als Ergebnis beispielsweise ein PDF erzeugt werden soll, dann bedeutet dies, dass wir aus Markdown LaTeX-Dokumente erzeugen und diese im Anschluss mit lualatex in ein PDF wandeln. Damit dies möglich ist, haben wir uns ein Docker-Image erstellt, in dem TeX Live installiert ist.
Da wir lualatex aus TeX Live einsetzen, ist unser Docker-Image mehrere Gigabyte groß. Diese Kröte müssen wir wohl schlucken
. Pandoc leistet sehr gute Dienste und die Entscheidung für Markdown als Ausgangsformat hat sich bewährt.
Wir werden diese Kombination beibehalten, jedoch gelegentlich prüfen, ob wir das Docker-Image etwas verkleinern können 🙂
Zusammenfassung
Wir erstellen mit Gitlab automatisiert Perl-Distributionen, Docker-Images und Dokumente in unterschiedlichen Formaten. Gitlab als Plattform hat sich hierfür bewährt. Durch den Einsatz einer selbst betriebenen Gitlab-Instanz erhoffen wir uns geringere Durchlaufzeiten.
Links
- Produktübersicht von Gitlab
- Homepage von Docker
- Online-Handbuch von dzil
- YAML: Homepage zum Format und Referenz zur Konfiguration von Gitlab
- Anleitung zu Pinto
- Übersicht zu TeX Live
- Anleitung von pandoc
- Eine der vielen Seiten zu Markdown
Permalink: /2020-09-01-wie-nutzen-wir-gitlab
Test::Perl::Critic::Progressive – Codier-Richtlinien Schritt für Schritt durchsetzen
Codier-Richtlinien haben als Ziel, die Formulierung von Code zu vereinheitlichen und ihn dadurch zu verbessern. Wenn sie bei einer bestehenden Code-Basis eingeführt werden, gibt es in der Regel zu Beginn viele Verstöße. Test::Perl::Critic::Progressive ist ein Werkzeug, um die Richtlinien für Perl-Code schrittweise durchzusetzen.
Die Einhaltung von Richtlinien mit perlcritic prüfen
Das Werkzeug perlcritic ist seit vielen Jahren das Standardwerkzeug, um Perl-Code statisch zu prüfen. Eine statische Prüfung wird im Gegensatz zur dynamischen Prüfung vor der Ausführung durchgeführt; es bedeutet also, dass der Code untersucht wird, ohne ihn auszuführen. Mit perlcritic kann so die Einhaltung von Codier-Richtlinien festgestellt werden.
Das folgende Beispiel zeigt einen Aufruf von perlcritic, der eine Datei auf Einhaltung der Richtlinie CodeLayout::RequireTidy prüft und einen Verstoß meldet:
$ perlcritic -s CodeLayout::RequireTidy lib/App/perldebs.pm
[CodeLayout::RequireTidyCode] Code is not tidy at lib/App/perldebs.pm line 1.
Durch die Einhaltung von Richtlinien kann eine Team unter anderem Folgendes erreichen:
- Das Verständnis über den Code wird verbessert, da er einheitlich geschrieben ist. Die Pflege und Erweiterung wird dadurch vereinfacht.
- Mitarbeiter können besser und schneller eingearbeitet werden, da die Richtlinien eine Hilfestellung zur Codierpraxis geben.
- Die Verwendung unsicherer Sprachkonstrukte kann aufgedeckt werden. Dadurch werden Sicherheitsprobleme verhindert.
Prüfen von Richtlinien als Test
Die Ablauflogik des Kommandozeilenwerkzeugs perlcritic kann über das\
Modul Test::Perl::Critic in die Testsuite eingebunden werden. Verstöße gegen die Richtlinien können so recht einfach aufgedeckt werden:
use Test::Perl::Critic;
all_critic_ok();
Eine Organisation erstellt selten zunächst ihre Richtlinien und entwickelt dann erst die Software anhand dieser Richtlinien. In der Regel ist der umgekehrte Fall der Normalfall: Eine existierende Code-Basis ist ohne Richtlinien geschrieben worden und die Organisation erhofft sich durch Durchsetzung der Richtlinien beispielsweise die oben genannten Vorteile.
Wenn nun bei vorhandener Code-Basis Richtlinien eingeführt werden, gibt es üblicherweise eine Reihe von Verstößen, da der Code vorher beliebig formuliert werden konnte. Die Entwickler sehen sich nun mit dem Problem konfrontiert, dass sie sich einerseits an die Richtlinien halten wollen oder sogar müssen, andererseits der existierende Code nicht zusätzlich zum Tagesgeschäft kurzfristig umgeschrieben werden kann.
Wie kann dieses Problem gelöst werden?
Iterative Verbesserung
Das Modul Test::Perl::Critic::Progressive kann hier eine technische Hilfestellung bieten. Es ist hiermit möglich, bei einer beliebigen Anzahl von Verstößen diese Schritt für Schritt zu beheben. Die Code-Basis kann so iterativ in eine Form überführt werden, die den Richtlinien entspricht.
Wie arbeiten dieses Modul nun?
Test::Perl::Critic::Progressive arbeitet ähnlich wie Test::Perl::Critic. Es verwendet die Prüflogik von perlcritic und sammelt beim ersten Aufruf die Anzahl der Verstöße jeder einzelnen Richtlinie. Die Sammlung wird in der Datei .perlcritic-history als Hash abgelegt:
$VAR1 = [
{
'Perl::Critic::Policy::CodeLayout::RequireTidy' => 10,
'Perl::Critic::Policy::BuiltinFunctions::ProhibitStringyEval' => 85,
'Perl::Critic::Policy::BuiltinFunctions::RequireGlobFunction' => 0,
'Perl::Critic::Policy::ClassHierarchies::ProhibitOneArgBless' => 2,
...
}
];
Bei jedem weiteren Aufruf wird diese Sammlung erneut erstellt. Beide Sammlungen werden nun in einem Test miteinander verglichen. Dieser Test schlägt fehl, wenn die Anzahl von Verstößen bei einer Richtlinie angestiegen ist:
CodeLayout::RequireTidy: Got 54 violation(s). Expected no more than 36.
Mit Test::Perl::Critic::Progressive kann man also sicherstellen, dass die Anzahl der Verstöße gegen die festgelegten Richtlinien nicht ansteigt.
Neben dieser technischen Lösung muss es noch organisatorische Änderungen geben, damit der Code auch wirklich verbessert wird. In der Regel bedeutet dies, dass den Entwicklern Zeit für die Verbesserung gegeben werden muss.
Nur dann, wenn das Team neben den technischen Lösung des Auffindens von Problemen zusätzlich noch Verfahren umsetzt, um den Code anhand der Empfehlungen der Richtlinien umzuformulieren, können die Entwickler schrittweise die Verstöße reduzieren. Sie werden dann nach und nach die Code-Basis überarbeiten und im Sinne der Richtlinien verbessern.
Best Practice
- Grundsätzlich ist
Test::Perl::Critic::Progressivedurch seine iterative Arbeitsweise gut geeignet, in agilen Entwicklungsteams eingesetzt zu werden. - Der Basissatz von Richtlinien, die bei der Installation von
perlcriticvorhanden sind, sollte auf keinen Fall vollständig eingebunden werden, da er veraltet ist. - Es ist ratsam, mit wenigen Richtlinien zu beginnen. Die Entwickler werden so durch schnelle Erfolgserlebnisse motiviert und erfahren den praktischen Nutzen von Richtlinien. Außerdem sollten die Entwickler bei der Auswahl der Richtlinien beteiligt werden, um die Akzeptanz zu erhöhen.
- Das Team sollte entscheiden, ob es zunächst die Verstöße einzelner Richtlinien auf 0 verringern möchte oder ob einzelne Dateien vollständig bereinigt werden sollen.
- Wenn das Team problematische Codierweisen entdeckt hat, sollte es für die Aufdeckung dieser Schreibweisen auf CPAN nach ergänzenden Richtlinien suchen oder eigene Richtlinien entwickeln.
- Nach Möglichkeit sollte
Test::Perl::Critic::Progressivein Versionskontrollsystemen so eingesetzt werden, dass abgelehnter Code nicht eingecheckt werden kann, um dem Entwickler schnellstmögliche Rückmeldung zu geben. - Unterstützend kann ein mit
Test::Perl::Critic::Progressivedurchgeführter Test in einem CI-System zu Beginn der Testsuite laufen, um dem Entwickler schnell Rückmeldung zu geben. Test::Perl::Critic::ProgressiveverwendetPerl::Criticund somit die DistributionPPI. Letztere ist bei großen Codemengen langsam und führt zu langen Feedback-Zyklen.Test::Perl::Critic::Progressivesollte in einem CI-System daher nicht auf allen Quellen angewendet werden. Ist das nicht möglich, so sollte die Verwendung parallel zur restlichen Testsuite ablaufen.
Zusammenfassung
Test::Perl::Critic::Progressive ist ein Werkzeug, um Codier-Richtlinien schrittweise durchzusetzen. In Verbindung mit einem Vorgehen zum Beheben von Verstößen gegen diese Richtlinien kann es eingesetzt werden, um eine Code-Basis im Team nach und nach zu verbessern.
Links
- Test::Perl::Critic::Progressive
- Test::Perl::Critic
- Perlcritic-Richtlinien auf CPAN
- Anleitung zum Schreiben eigener Perlcritic-Richtlinien
- perlcritic
- PPI
- Gradually improving our code quality with Test::Perl::Critic::Progressive: Einsatz von\
Test::Perl::Critic::Progressiveauf Jenkins unter Verwendung von Git. - App::Critique – An incremental refactoring tool for Perl powered by
Perl::Critic: Ein verwandtes Werkzeug, mit dem eine Entwicklerin iterativ in einer Arbeitssitzung Verstöße gegen Richtlinien beheben kann.
Permalink: /2020-08-25-test-perl-critic-progressive