Nuclino-Backup mit Mojolicious - Teil 1
Wir bei Perl-Services.de nutzen seit längerem Nuclino als Wissensdatenbank. Natürlich wollen wir unser Wissen auch gut gesichert wissen. Zum einen falls Nuclino irgendwann mal dicht machen sollte, zum anderen aber auch, damit wir jederzeit den Anbieter wechseln könnten.
Aus diesem Grund haben wir uns die Frage gestellt, wie wir ein Backup der Nuclino-Seiten umsetzen können. Aktuell gibt es leider noch kein API, über das wir das Backup erstellen und herunterladen können. Also müssen wir irgendwie anders an die Daten kommen. Jede einzelne Seite besuchen und herunterladen? Da bräuchten wir eine Liste der Seiten. Das muss doch auch anders gehen...
Was ist Nuclino?
Nuclino ist eine Webanwendung, in der man schnell viel Texte ablegen kann. Diese Texte werden in hierarchischer Form abgelegt. Man kann sogenannte Workspaces zu den verschiedensten Themen anlegen. Innerhalb dieser Workspaces kann man die Texte wiederum in Clustern gruppieren.
Das sieht dann beispielsweise so aus:
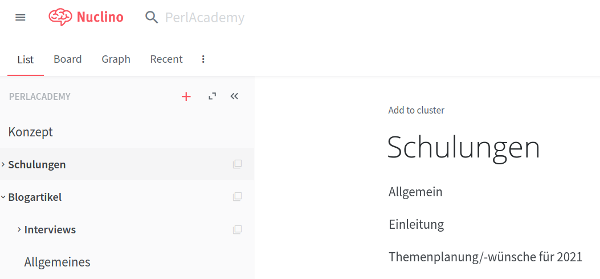
Zur Formatierung wird Markdown eingesetzt. Die Markdown-Syntax wird auch direkt umgesetzt und gerendert. Ein Vorteil der Anwendung ist, dass mehrere Personen gleichzeitig an einem Dokument arbeiten können und man bekommt die Änderungen gleich mit. So ist es z.B. möglich, direkt während eines Telefonats Dokumente zu ändern und über die Änderungen zu sprechen.
Die Gliederung der Texte ist erstmal - wie bereits gezeigt - hierarchisch. Man kann aber auch andere Darstellungen wählen, z.B. als Graphen oder als Board:
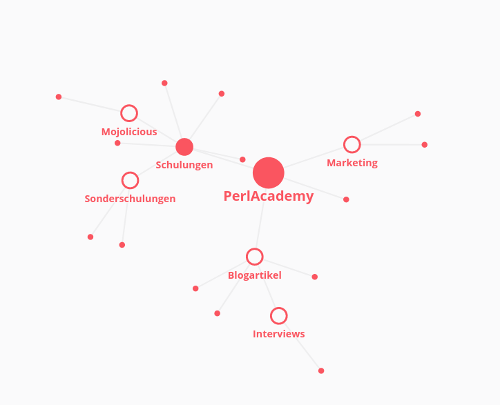
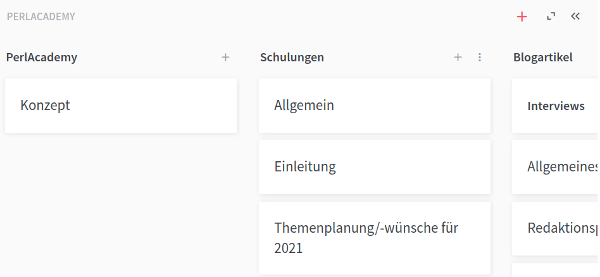
In den Texten selbst können Inhalte aus verschiedenen Diensten wie zum Beispiel Prezi oder Draw.io eingebettet werden.
Wie arbeitet die Anwendung?
Doch zurück zum Backup. Da es keine API gibt, mussten wir uns anschauen, wie die Anwendung arbeitet. Welche Funktionalitäten gibt es in der Webanwendung? Wie werden diese erreicht? Welche Requests werden ausgelöst?
Wer in der Anwendung etwas stöbert oder einfach die Hilfeseiten besucht, wird bei den Workspace-Settings die Funktion
Workspace exportieren
finden:
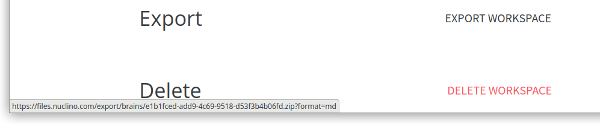
Man sieht beim Browser die Zieladresse des Links. Man bekommt also ein Zip-Archiv mit den Dokumenten im Markdown-Format – allerdings
nur, wenn man die UUID des Workspaces (oder wie im Link bezeichnet des Brains
) kennt.
Eine Liste der Workspaces händisch pflegen? Kommt nicht in Frage, das muss auch anders gehen! Die Anwendung selbst muss ja auch
irgendwoher wissen, welche Workspaces (oder Brains
) es gibt. Also mal die Developertools des Browsers geöffnet und dann schauen was passiert...
Wenn man sich die Netzwerkanalyse anschaut, fällt beim Login auf, dass neben Google-Analytics und Google-Fonts einige Requests an api.nuclino.com geschickt werden. Unter anderem der Login an sich, aber auch etwas mit inital-state.
Auf den Request sendet der Server als Antwort eine JSON-Struktur, in der auch die Brains
zu finden sind:
{
"response":{
"userId":"<user-uuid>",
"teams":[
{
"id":"<team-uuid>",
"data":{
"name":"<team-name>",
"brains":[
"734eaf2c-b066-11ea-81bd-a36778484b6c",
"820c6310-b066-11ea-9648-bbd09f732919",
...
],
...
Das passende Perl-Skript
Jetzt haben wir alle Informationen, um die Daten aus Nuclino zu sichern. Wir wollen aber mehr. Wir wollen auch die Änderungen sehen, die von Mal zu Mal vorgenommen wurden. Dafür verwalten wir unsere Datensicherung in einem Git-Repository.
Unser Skript muss also folgendes tun:
- Sich bei Nuclino einloggen
- Die UUIDs der Brains holen
- Für jeden Brain ...
- das Zip-Archiv herunterladen
- das Archiv in das Git-Repository entpacken
- Die Änderungen committen
- Die Änderungen auf den Server pushen
Die ersten beiden Punkte werden wie folgt abgearbeitet:
use Mojo::File qw(path);
use Mojo::JSON qw(decode_json);
use Mojo::UserAgent;
use Mojo::UserAgent::CookieJar;
my $ua = Mojo::UserAgent->new(
cookie_jar => Mojo::UserAgent::CookieJar->new,
max_connections => 200,
);
my $config = decode_json path(__FILE__)->sibling('nuclino.json')->slurp;
my $header = {
# header wie in den Developertools zu sehen
};
my $base_url = 'https://api.nuclino.com/api/users/';
my $tx_init = $ua->get('https://app.nuclino.com/login');
my $tx_login = $ua->post(
$base_url . 'auth' => $header => json => $config,
);
my $tx_initial_state = $ua->get(
$base_url . 'me/initial-state' => $header
);
my @brains = @{ $tx_initial_state->res->json('/response/teams/0/data/brains') || [] };
In $ua steckt ein Objekt von Mojo::UserAgent.
Mit diesem wird erstmal die Login-Seite abgerufen, um
ein initiales Cookie zu erhalten. Ohne dieses Cookie ist der Login nicht möglich.
Anschließend loggt sich das Skript bei Nuclino ein. Hier müssen die Header so gesetzt werden, wie es der Browser auch macht.
Mit dem Request an initial-state wird dann das JSON geholt, in dem die UUIDs der Brains
stehen.
Hier zeigt sich dann auch die Eleganz der Mojo-Klassen: Mit
$tx->res->json('/response/teams/0/data/brains');
kommt man sehr einfach an die Daten. Wenn die Gegenstelle in den HTTP-Headern den richtigen
Content-Type setzt, kann man über das Response-Objekt (->res) auf ein
Mojo::JSON::Pointer-Objekt
(->json) und damit auf die JSON-Datenstruktur zugreifen. Dazu wird ein XPath-änlicher String
übergeben.
Jetzt, wo wir die UUIDs der Brains
haben, können wir die Zip-Archive einfach herunterladen:
my $backup_path = path(__FILE__)->dirname->child('..', 'backups');
for my $brain ( @brains ) {
my $url = sprintf 'https://files.nuclino.com/export/brains/%s.zip?format=md', $brain;
my $tx_backup = $ua->get(
$url => {
# header wie in den Developertools zu sehen
},
);
my $dir = $backup_path->child( $brain );
$dir->make_path;
my $zip_file = $dir->child( $brain . '.zip' );
push @zips, $zip_file->to_abs;
$tx_backup->res->save_to( $zip_file );
}
Hier wird mit Mojo::File erstmal das Zielverzeichnis erstellt.
Anschließend wird für jeden Workspace das Zip-Archiv geholt. Für jeden Workspace wird ein eigenes
Verzeichnis erstellt, in das wir dann später die Dateien entpacken können.
Als Ergebnis des GET-Requests bekommen wir ein Mojo::Transaction-Objekt.
Wie schon oben gesehen, wollen wir wieder etwas mit der Antwort
(->res) anfangen. Wenn es keine Multipart-Antwort ist, kann der Inhalt der Antwort mit save_to in eine
Datei gespeichert werden.
Im nächsten Teil vollenden wir das Skript, indem wir die Dateien im Git-Repository speichern und das Skript noch etwas schneller machen.
Permalink: /2020-08-15-nuclino-backup-I