cpanfile – Teil 1
Ein cpanfile ist eine Datei, die Abhängigkeiten von Anwendungen und Modulen beschreibt. Diese Dateien sind in der Perl-Welt nichts neues (sie gibt es seit über 8 Jahren) und sie sind eine sehr gute Möglichkeit, die Installation von Abhängigkeiten zu vereinfachen.
Die Nutzung einer solchen Datei eignet sich für folgende Szenarien:
- Ein Projekt soll direkt aus einem Repository heraus installiert werden.
- Neue Entwickler für das Projekt sollen schnell eine eigene Entwicklungsumgebung aufbauen können.
- Es soll immer eine reproduzierbare Umgebung aufgebaut werden können (es sollen immer die gleichen Versionen der Abhängigkeiten genutzt werden).
- und vermutlich noch viele weitere ...
Integration in Modulinstaller
cpanm kann die Abhängigkeiten aus einem cpanfile auslesen und diese installieren.
cpanm --installdeps .
liest die Datei namens cpanfile im aktuellen Verzeichnis aus.
Die nachfolgenden Abschnitten beschreiben die grundsätzlichen Möglichkeiten innerhalb des cpanfiles. Der nächste Artikel über cpanfiles wird noch weitergehen.
Standardabhängigkeiten werden einfach mit requires angegeben:
requires 'Mojolicious';
In diesem Fall wird einfach nur erwartet, dass irgendeine Version von Mojolicious installiert ist. Viele Module ändern ihr API, so dass man eine Mindestversion angeben sollte. Bei Mojolicious wurde z.B. mit Version 8.0 die Methode chmod in Mojo::File eingeführt. Benötigt die Anwendung diese Methode, muss sich das im cpanfile widerspiegeln:
requires 'Mojolicious' => 8;
Sollte eine Methode in 9.0 wieder abgeschafft werden und sie wird weiter verwendet, dann kann man auch einen Bereich angeben:
requires 'Mojolicious' => '>=8,<9';
Enthält eine Version der Abhängigkeit einen Bug, kann man diese Version explizit ausschließen:
requires 'Mojolicious' => '>8, != 8.12';
Diese Bedingungen sind mit und verknüpft.
In vielen Fällen werden für die Entwicklung der Anwendung oder des Moduls extra Abhängigkeiten benötigt. Wird die Anwendung ausgerollt oder das Modul installiert, sollen diese Abhängigkeiten nicht installiert werden.
Deshalb können sogenannte Phasen genutzt werden. Die oben gezeigten Beispiele gelten für die Phase runtime. Das ist die Standardphase und muss nicht extra angegeben werden. Gelten Abhängigkeiten nur für die Entwicklung, ist die Phase develop zu wählen. Abhängigkeiten, die für die Tests nötig sind, müssen für die Phase test installiert werden.
on 'develop' => sub {
requires 'Dist::Zilla' => 0.1;
};
on 'test' => sub {
requires 'Test::BDD::Cucumber' => 2;
};
Hier wird mit on bestimmt, dass die Phase sich ändert und in einer Subroutinen-Referenz werden dann die requires aufgelistet. Module::CPANfile kennt als Phasen runtime, develop, test und configure.
Die Installation mit cpanm über cpanm --installdeps . installiert nur die Module für die runtime und test. Sollen die Abhängigkeiten anderer Phasen installiert werden, muss das mit --with-<phase>, also z.B.
cpanm --with-develop --installdeps .
Soweit die Basisinformationen zu cpanfiles. Sie sind ein empfehlenswertes Werkzeug und mit den hier gezeigten Möglichkeiten kommt man in den allermeisten Fällen aus.
Permalink: /2022-06-29-cpanfile-a-teil-1
Einführung in Dist::Zilla
Eine Perl-Distribution besteht neben dem eigentlichen Code auch aus Dateien und Code, um die Distribution über CPAN zur Verfügung zu stellen. Das manuelle Erstellen dieser Dateien hält vom Entwickeln ab und wird schnell lästig. Dist::Zilla automatisiert diese Vorgänge. In diesem Artikel gebe ich einen Überblick über den Zweck von Dist::Zilla und zeige einen Einstieg in dessen Verwendung.
Das Problem: Langsam durch Handarbeit
CPAN ist der Ort, an dem Perl-Distributionen liegen. Damit Distributionen über CPAN bereitgestellt und von dort installiert werden können, muss ihr Inhalt und ihre Form einigen Anforderungen genügen. Diese Anforderungen können Autoren durch Handarbeit erfüllen.
Diese Handarbeit ist allerdings lästig und hält von der Hauptaufgabe ab: Code schreiben! Dist::Zilla ist eine Distribution, die das Werkzeug dzil bereitstellt, mit dem diese Handarbeit automatisiert werden kann. Dadurch werden Autoren schneller und als angenehme Nebenwirkung vereinheitlichen sie ihre Distributionen.
Die Notwendigkeit von Infrastruktur-Code
Perl-Distributionen sind im Kern ein Archiv von Dateien mit bestimmten Aufbau. Nur ein Teil dieses Archivs ist der eigentliche Code. Viele andere Dateien davon bilden nur die Infrastruktur, damit die Distribution auf CPAN bereitgestellt und von dort geladen werden kann; daher sind diese Dateien grundsätzlich notwendig. Leider ist es jedoch so, dass sie nicht nur einmal erstellt, sondern teilweise vor jedem erneuten Release geändert werden müssen.
Automatisierung hilft
Dist::Zilla nimmt dem Autor einer Distribution die Erstellung und Pflege dieser Dateien durch Automatisierung ab. Im Ergebnis muss dann (fast) nur noch der eigentliche Code geschrieben werden. Die Einschränkung betrifft die Konfiguration von dzil, die in der Datei dist.ini getroffen wird.
In dieser Konfiguration werden Metadaten und weitere Informationen untergebracht. Die Funktionsweise von Dist::Zilla kann der Autor über Plugins erweitern; die Plugins werden ebenfalls in dieser Datei konfiguriert.
Das Tool dzil
Das Werkzeug dzil bietet viele Kommandos, die durch den Aufruf von dzil angezeigt werden:
$ dzil
dzil <command> [-?hIVv] [long options...]
-v --verbose log additional output
-V STR... --verbose-plugin STR... log additional output from some
plugins only
-I STR... --lib-inc STR... additional @INC dirs
-? -h --help show help
Available commands:
commands: list the application's commands
help: display a command's help screen
add: add modules to an existing dist
authordeps: list your distribution's author dependencies
build: build your dist
clean: clean up after build, test, or install
cover: code coverage metrics for your distribution
install: install your dist
listdeps: print your distribution's prerequisites
new: mint a new dist
nop: do nothing: initialize dzil, then exit
perltidy: perltidy your dist
regenerate: write release staging contents into source tree
release: release your dist
run: run stuff in a dir where your dist is built
setup: set up a basic global config file
smoke: smoke your dist
test: test your dist
xtest: run xt tests for your dist
Für den Einstieg sind folgende drei Kommandos wichtig: build, test und release.
- Durch den Aufruf von
dzil builderstellt der Autor die Distribution anhand der Konfigurationdist.ini. - Mit
dzil testerstellt der Autor die Distribution und lässt darin die Tests ablaufen. - Schließlich kann der Autor die Distribution mit
dzil releaseauf CPAN veröffentlichen.
Zusammenfassung
In diesem Artikel habe ich einen kurzen Überblick über Dist::Zilla gegeben und die Möglichkeiten aufgezeigt. In den nächsten Teilen dieser Artikelserie werde ich auf die einzelnen Aspekte näher eingehen. Wenn du neugierig geworden bist und schon selbst ein bisschen durch das vorhandene Material stöbern möchtest, empfehle ich dir folgende Seiten:
- Die Homepage von
Dist::Zilla - Dist::Zilla auf MetaCPAN
- Ein Walk-Through durch eine echte
dist.ini
Permalink: /2022-06-08-einfa14hrung-in-distzilla
CPAN-News Januar 2021
Der Januar ist rum, Zeit mal nachzuschauen was wir im Januar so alles auf CPAN geladen haben.
Zurerst ein Blick auf komplett neue Module:
Dist-Zilla-Plugin-SyncCPANfile
Wir nutzen *cpanfile*s um die Abhängigkeiten in unseren Projekten zu definieren. Und wir nutzen Dist::Zilla zum Bauen von Distributionen. Dafür gibt es das Plugin Dist::Zilla::Plugin::CPANFile. Das erstellt das cpanfile aber erst in der Distribution. Wir möchten die Datei aber direkt im Repository haben.
Aus diesem Grund haben wir Dist::Zilla::Plugin::SyncCPANfile geschrieben, das die in der dist.ini gelisteten Abhängigkeiten in ein cpanfile schreibt.
Folgendes einfach in die dist.ini schreiben (aus der SYNOPSIS):
# in dist.ini
[SyncCPANfile]
# configure it yourself
[SyncCPANfile]
filename = my-cpanfile
comment = This is my cpanfile
OTRS-OPM-Validate
Ein weiteres Modul, das neu geschrieben wurde, ist OTRS::OPM::Validate. Mit diesem Modul ist es möglich, Erweiterungen für Ticketsysteme wie Znuny, OTOBO, ((OTRS)) Community Edition validieren. Die Dateien sind XML-Dateien mit bestimmten Inhalten.
Da die Entwicklung aber nicht mit einem bestimmten Schema erfolgte und XML::LibXML::Schema nicht das neueste XML-Schema unterstützt, musste was eigenes her.
Das Modul nutzt Reguläre Ausdrücke sehr intensiv...
Aber auch bestehende Module haben ein Update erfahren:
DNS::Hetzner
Dieses Modul ermöglicht es, das REST-API für DNS von Hetzner zu nutzen. Im Januar wurde das Modul mehr oder weniger komplett neu geschrieben, es hat etliche Tests bekommen und die Klassen für das API wurden neu generiert, so dass auch die neuesten Endpunkte unterstützt werden.
use DNS::Hetzner;
use Data::Printer;
my $dns = DNS::Hetzner->new(
token => 'ABCDEFG1234567', # your api token
);
my $records = $dns->records;
my $zones = $dns->zones;
my $all_records = $records->list;
p $all_records;
CPANfile::Parse::PPI
Da dieses Modul ein statischer Parser für *cpanfile*s ist, wurde ein strict-Modus eingeführt. Damit bricht das Modul ab, wenn dynamische Konstrukte wie
for my (qw/
IO::All
Zydeco::Lite::App
/) {
requires , '0';
}
in der Datei stehen.
use CPANfile::Parse::PPI -strict;
use Data::Printer;
my $required = do { local $/; <DATA> };
my $cpanfile = CPANfile::Parse::PPI->new( \$required );
my $modules = $cpanfile->modules;
__DATA__
for my $module (qw/
IO::All
Zydeco::Lite::App
/) {
requires $module, '0';
}
OTRS-OPM-Installer
Hier wurden nur ein paar Änderungen vorgenommen, weil OTRS::OPM::Parser auf Moo umgestellt wurde und sich das Verhalten ein wenig geändert hat (einige Attribute liefern keine Arrays mehr, sondern Arrayreferenzen).
OTRS-OPM-Parser
Jetzt wird zum Validieren der .opm-Dateien unser neues Module OTRS::OPM::Validate genutzt.
Permalink: /2021-02-06-cpannews-januar-2021
Frohes Neues Jahr 2021
Das in vielerlei Hinsicht ungewöhnliche Jahr 2020 ist vorbei. Wir wünschen allen treuen und neuen Leser*innen unseres Blogs ein frohes neues Jahr. Wir hoffen, dass Sie gut durch das vergangene Jahr gekommen sind und dass 2021 besser wird.
Trotz der vielen Einschränkungen waren wir nicht untätig. Erstmal ein paar Daten:
- Wir haben 33 Releases von unseren CPAN-Modulen gemacht, darunter auch neue Module wie CPANfile::Parse::PPI und Markdown::Table
- Wir haben 40 Blogposts geschrieben
- 29 hier bei perl-academy.de
- 11 bei feature-addons.de
- Einen Artikel für die iX haben wir beigesteuert
- Wir haben sechs Schulungen (vier längerfristige Schulungen, zwei Sonderschulungen für den Deutschen Perl-/Raku-Workshop) konzipiert
- Wir waren beim Deutschen Perl-/Raku-Workshop 2020 in Erlangen
- Die ersten Addons wurden von der ((OTRS)) Community Edition auf OTOBO portiert
- Für einige freie Addons für die ((OTRS)) Community Edition gab es neue Versionen
- etliche Perl-Projekte wurden erfolgreich abgearbeitet
- und vieles mehr.
Wir möchten uns bei all unseren Kunden und Freunden bedanken. Nur mit Ihnen/Euch konnte das Jahr so erfolgreich abgeschlossen werden. Wir haben viele Ideen bekommen, die wir größtenteils umsetzen konnten.
Wir hoffen, dass der Deutsche Perl-/Raku-Workshop 2021 in Leipzig auch offline stattfinden kann. Dann werden auch wir unsere Schulungen wie geplant abhalten können. Auf dem Workshop werden wir wahrscheinlich ein paar Vorträge halten. Sobald die Organisatoren das Programm veröffentlichen werden wir uns auf diesem Kanal melden.
Auch für die geplanten anderen Schulungen planen wir zweigleisig – sowohl als Präsenzveranstaltung als auch in einer Online-Variante.
Wir wünschen Ihnen ein erfolgreiches Jahr 2021 und freuen uns auf ein spannendes Jahr.
Permalink: /2021-01-01-frohes-neues-jahr
CPAN-Updates November/Dezember 2020
Auch in den letzten beiden Monaten dieses Jahres waren wir nicht ganz untätig – teilweise mit Hilfe anderer Perl-Programmierer*innen.
In den folgenden Abschnitten stelle ich unsere neuen bzw. aktualisierten CPAN-Pakete vor:
CPANfile::Parse::PPI
Ein neues Modul, das ein statisches Parsen von *cpanfile*s ermöglicht. Ich habe schon in einem Blogpost erwähnt, warum wir nicht Module::CPANfile nutzen. Da ich noch mehre dieser Anwendungsfälle habe, habe ich ein Modul daraus gebaut: CPANfile::Parse::PPI.
use v5.24;
use CPANfile::Parse::PPI;
my $path = '/path/to/cpanfile';
my $cpanfile = CPANfile::Parse::PPI->new( $path );
# or
# my $cpanfile = CPANfile::Parse::PPI->new( \$content );
for my $module ( $cpanfile->modules->@* ) {
my $stage = "";
$stage = "on $module->{stage}" if $module->{stage};
say sprintf "%s is %s", $module->{name}, $module->{type};
}
Perl::Critic::RENEEB
In dieser Distribution habe ich zwei neue Regeln hinzugefügt:
Zum einen eine Regel, mit der die Nutzung von *List::Util*s first gefordert wird, wenn im Code ein grep genutzt aber nur das erste Element weiterverwendet wird, wie in diesem Beispiel:
my ($first_even) = grep{
$_ % 2 == 0
} @array;
Die zweite Regel fordert die Nutzung des postderef-Features. Das heißt, dass dieser Code
my @array = @{ $arrayref };
umgeschrieben werden soll als
my @array = $arrayref->@*;
Außerdem gab es kleine Änderungen an den Metadaten. Danke an Gabor Szabo für den Pull Request.
Mojolicious::Command::Author::generate::localplugin
Hier haben wir keine Arbeit aufwenden müssen, sondern durften auf die Fähigkeiten in der Perl-Community zurückgreifen. Andrew Fresh hat einen Pull Request eingereicht, der die Tests die dieses Modul für das generierte Plugin erstellt, lauffähig macht. Vielen Dank dafür!
Mojolicious::Plugin::FormFieldsFromJSON
Auch hier haben wir Pull Requests aus der Perl-Community erhalten:
- Interne POD-Links wurden korrigiert (Danke an Håkon Hægland)
- Ein paar Perl::Critic-Warnungen wurden korrigiert (Danke an Lubos Kolouch)
- Der Grund von FAIL-Reports der CPANTester wurde gefixt (Danke an Mohammad S Anwar)
OTRS::OPM::Maker::Command::sopm
Vor kurzem kam die erste Anforderung, eines unserer Module für OTOBO zu portieren. Da wir die Spezifikationsdateien unserer Erweiterungen generieren lassen, musste das Kommando entsprechend angepasst werden.
In der Metadaten-Datei (z.B. die für DashboardMyTickets) muss nur noch als Produkt OTOBO
angegeben werden, dann wird die .sopm-Datei richtig generiert.
OTRS::OPM::Parser
Das ist das zweite Modul, das für die Nutzung mit OTOBO ertüchtigt wurde. Mit der neuesten Version können Addons für OTOBO geparst werden. Das wurde notwendig, um einen OPAR-Klon für OTOBO aufsetzen zu können.
Zusätzlich wurde die Synopsis durch Håkon Hægland verbessert. Danke für den entsprechenden Pull Request.
Permalink: /2020-12-29-cpan-update-november-dezember
CPAN-Updates September 2020
Ja, ich weiß dass der September schon vorbei ist. Aber der Inhalt bezieht sich auf das was im September so passiert ist ;-) In den letzten Wochen haben wir wieder ein paar unserer Module auf CPAN aktualisiert. Dieser Artikel gibt einen kurzen Überblick, was sich so getan hat.
Markdown::Table
Markdown::Table ist ein neues Modul, das wir zum Generieren von Tabellen in Markdown nutzen können. Der für uns aktuell wichtigere Teil ist aber das Parsen von Tabellen in Markdown-Dokumenten.
Wir nutzen - wie vielleicht schon bekannt - Nuclino zur Ablage von Informationen. Unter anderem auch für den Redaktionsplan
für dieses Blog. Dort steht in einer Tabelle, wann welcher Artikel geplant ist.
Mit den Daten dieser Tabelle soll ein interner Kalender gepflegt werden, so dass Erinnerungen etc. generiert werden.
Aus der SYNOPSIS:
use Markdown::Table;
my $markdown = q~
This table shows all employees and their role.
| Id | Name | Role |
|---|---|---|
| 1 | John Smith | Testrole |
| 2 | Jane Smith | Admin |
~;
my @tables = Markdown::Table->parse(
$markdown,
);
print $tables[0]->get_table;
OTRS::OPM::Maker::Command::sopm
Wir machen auch ziemlich viel mit der ((OTRS)) Community Edition: Schulungen, Anpassungen und vieles mehr. Für Erweiterungen gibt es im ((OTRS)) einen Paketmanager, der die Pakete in einem bestimmten XML-Format erwartet (sog. OPM-Dateien). Die Spezifikation
für die Pakete wird selbst auch in XML festgehalten. Mir ist das zu aufwendig und schreibe die Meta-Daten in eine JSON-Datei. Die wird dann mit dem sopm-Kommando des Tools opmbuild ausgewertet und die Spezifikationsdatei (.sopm) wird geschrieben.
Neu ist die Unterstützung vom Löschen von Spalten in Tabellen mittels ColumnDrop.
Mojolicious::Plugin::Data::Validate::WithYAML
Vor einigen Tagen habe ich ja Data::Validate::WithYAML vorgestellt. Das aktualisierte Modul ist das passende Mojolicious-Plugin dazu. Damit wird die Validierung der Benutzereingaben zum Kinderspiel.
In der neuen Version nutzen wir die Module, die Mojolicious mitliefert anstelle von File::Spec und File::Basename. Mojo::File ist ein tolles Modul wenn man mit Dateien arbeitet.
Weiterhin gibt es in dem Plugin jetzt eine Unterstützung für steps
in den YAML-Dateien. Damit kann man die gleichen Dateien nutzen, die man bei reiner Data::Validate::WithYAML-Nutzung verwendet.
Permalink: /2020-10-02-cpan-news-september-2020
Messung der Modul-Verwendung
Mich selbst interessiert auch die Frage, welches Modul vom CPAN wird eigentlich besonders häufig genutzt? Da CPAN keine Daten dazu speichert, wie oft ein Modul heruntergeladen wird ist das nicht so einfach zu beantworten. Ein Tweet hat mich dazu gebracht eine kleine Anwendung zu schreiben, bei der jeder seine/ihre cpanfiles hochladen kann: https://usage.perl-academy.de.
Momentan werden dabei nur die requires ausgewertet.
Ja, so lange es nicht besonders weit verbreitet ist, ist die Datenlage sehr dünn und natürlich kann man das leicht manipulieren in dem man die eigenen cpanfiles mehrfach hochlädt. Um eine Idee von häufig genutzten Modulen zu bekommen, ist die Anwendung ganz nützlich.
Ich plane mit der Zeit noch einige statistische Auswertungen hinzuzufügen. Ich werde dann hier im Blog davon berichten. Bis dahin hoffe ich, dass noch einige cpanfiles hochgeladen werden. Jede/r kann mithelfen!
Mit was haben wir die Anwendung umgesetzt? Natürlich mit Mojolicious. Weiterhin kommen noch Minion als JobQueue und PPI zum Parsen der cpanfiles zum Einsatz. Diese beiden Module werden wir hier im Blog noch genauer vorstellen.
Permalink: /2020-08-17-module-usage
CPAN Updates - Juli 2020
Gregor und ich haben einige CPAN-Module. Wir wollen hier an dieser Stelle auch immer wieder auf wichtige Neuerungen in unseren Modulen aufmerksam machen.
In den letzten Wochen habe ich vermehrt an MySQL::Workbench::Parser
und MySQL::Workbench::DBIC gearbeitet um die Abbildung von
Views zu unterstützen.
In der Workbench können ganz einfach Views hinzugefügt werden. In der Konfiguration muss nur das SQL-Statement angegeben werden, wie der View aufgebaut werden soll:
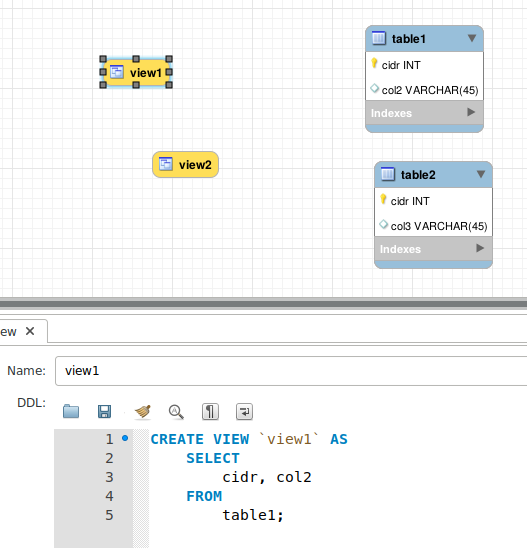
Der Vorteil der Workbench liegt darin, dass man mit Kunden und auch untereinander einfach die Workbench-Datei austauschen kann und man etwas grafisches vor Augen hat wenn man das Datenbankschema bespricht.
Wir nutzen die Workbench und die beiden Module in verschiedenen Projekten um
DBIx::Class-Klassen für den Zugriff auf die Datenbank zu erzeugen.
Mit einem kleinen Skript lässt sich der Perl-Code ganz einfach generieren:
use Mojo::File qw(curfile);
use MySQL::Workbench::DBIC;
my $foo = MySQL::Workbench::DBIC->new(
file => curfile->sibling('view.mwb')->to_string,
output_path => curfile->sibling('lib')->to_string,
namespace => 'Project::DB',
schema_name => 'Schema',
column_details => 1, # default 1
);
$foo->create_schema;
print sprintf "Version %s of DB created\n", $foo->version;
Damit werden dann folgende Dateien erstellt:
$ tree lib
lib
└── Project
└── DB
├── Schema
│ └── Result
│ ├── table1.pm
│ └── table2.pm
└── Schema.pm
table1.pm und table2.pm repräsentieren die entsprechenden Tabellen (siehe Abbildung weiter oben) und
mit den neuen Versionen von MySQL::Workbench::Parser und MySQL::Workbench::DBIC werden die Klassen
view1.pm und view2.pm erzeugt.
Die Klassen sehen wie folgt aus:
package Project::DB::Schema::Result::view1;
# ABSTRACT: Result class for view1
use strict;
use warnings;
use base qw(DBIx::Class);
our $VERSION = 0.05;
__PACKAGE__->load_components( qw/PK::Auto Core/ );
__PACKAGE__->table_class('DBIx::Class::ResultSource::View');
__PACKAGE__->table( 'view1' );
__PACKAGE__->result_source_instance->view_definition(
"CREATE VIEW `view1` AS
SELECT
cidr, col2
FROM
table1;"
);
__PACKAGE__->result_source_instance->deploy_depends_on(
["Project::DB::Schema::Result::table1"]
);
__PACKAGE__->add_columns(
cidr => {
data_type => 'INT',
is_numeric => 1,
},
col2 => {
data_type => 'VARCHAR',
is_nullable => 1,
size => 45,
},
);
Die entscheidenden Zeilen sind
__PACKAGE__->table_class('DBIx::Class::ResultSource::View');
__PACKAGE__->result_source_instance->view_definition(
"CREATE VIEW `view1` AS
SELECT
cidr, col2
FROM
table1;"
);
Als Klasse, wird hier DBIx::Class::ResultSource::View verwendet, das extra für Views
existiert. Anschließend erfolgt die SQL-Definition, wie sie in der Workbench eingetragen
wurde.
Hier wird absichtlich kein
__PACKAGE__->result_source_instance->is_virtual(1);
verwendet, weil die Views tatsächlich in der Datenbank angelegt werden sollen. Mit is_virtual(1)
wird der View rein virtuell behandelt.
Über diese Module habe ich übrigens im letzten Jahr auf dem Deutschen Perl-Workshop einen Vortrag gehalten:
Die Code-Beispiele liegen wieder im Gitlab-Repository.
Permalink: /2020-07-17-cpan-updates