CPAN-Updates November/Dezember 2020
Auch in den letzten beiden Monaten dieses Jahres waren wir nicht ganz untätig – teilweise mit Hilfe anderer Perl-Programmierer*innen.
In den folgenden Abschnitten stelle ich unsere neuen bzw. aktualisierten CPAN-Pakete vor:
CPANfile::Parse::PPI
Ein neues Modul, das ein statisches Parsen von *cpanfile*s ermöglicht. Ich habe schon in einem Blogpost erwähnt, warum wir nicht Module::CPANfile nutzen. Da ich noch mehre dieser Anwendungsfälle habe, habe ich ein Modul daraus gebaut: CPANfile::Parse::PPI.
use v5.24;
use CPANfile::Parse::PPI;
my $path = '/path/to/cpanfile';
my $cpanfile = CPANfile::Parse::PPI->new( $path );
# or
# my $cpanfile = CPANfile::Parse::PPI->new( \$content );
for my $module ( $cpanfile->modules->@* ) {
my $stage = "";
$stage = "on $module->{stage}" if $module->{stage};
say sprintf "%s is %s", $module->{name}, $module->{type};
}
Perl::Critic::RENEEB
In dieser Distribution habe ich zwei neue Regeln hinzugefügt:
Zum einen eine Regel, mit der die Nutzung von *List::Util*s first gefordert wird, wenn im Code ein grep genutzt aber nur das erste Element weiterverwendet wird, wie in diesem Beispiel:
my ($first_even) = grep{
$_ % 2 == 0
} @array;
Die zweite Regel fordert die Nutzung des postderef-Features. Das heißt, dass dieser Code
my @array = @{ $arrayref };
umgeschrieben werden soll als
my @array = $arrayref->@*;
Außerdem gab es kleine Änderungen an den Metadaten. Danke an Gabor Szabo für den Pull Request.
Mojolicious::Command::Author::generate::localplugin
Hier haben wir keine Arbeit aufwenden müssen, sondern durften auf die Fähigkeiten in der Perl-Community zurückgreifen. Andrew Fresh hat einen Pull Request eingereicht, der die Tests die dieses Modul für das generierte Plugin erstellt, lauffähig macht. Vielen Dank dafür!
Mojolicious::Plugin::FormFieldsFromJSON
Auch hier haben wir Pull Requests aus der Perl-Community erhalten:
- Interne POD-Links wurden korrigiert (Danke an Håkon Hægland)
- Ein paar Perl::Critic-Warnungen wurden korrigiert (Danke an Lubos Kolouch)
- Der Grund von FAIL-Reports der CPANTester wurde gefixt (Danke an Mohammad S Anwar)
OTRS::OPM::Maker::Command::sopm
Vor kurzem kam die erste Anforderung, eines unserer Module für OTOBO zu portieren. Da wir die Spezifikationsdateien unserer Erweiterungen generieren lassen, musste das Kommando entsprechend angepasst werden.
In der Metadaten-Datei (z.B. die für DashboardMyTickets) muss nur noch als Produkt OTOBO
angegeben werden, dann wird die .sopm-Datei richtig generiert.
OTRS::OPM::Parser
Das ist das zweite Modul, das für die Nutzung mit OTOBO ertüchtigt wurde. Mit der neuesten Version können Addons für OTOBO geparst werden. Das wurde notwendig, um einen OPAR-Klon für OTOBO aufsetzen zu können.
Zusätzlich wurde die Synopsis durch Håkon Hægland verbessert. Danke für den entsprechenden Pull Request.
Permalink: /2020-12-29-cpan-update-november-dezember
Arbeiten mit Nuclino Teil 3
In den vergangenen beiden Artikeln über unser Nuclino-Backup habe ich erst vorgestellt, wie wir die Backups erstellen und anschließend wie wir das Programm schneller gemacht haben.
Jetzt wo wir das Backup haben, kommen natürlich noch weitere Ideen. Wie können wir die Daten nutzen, so dass wir Nuclino als eine große Datenquelle nutzen und dann alle möglichen Produkte
daraus ziehen: Dokumentation für Kunden, Schulungsunterlagen als PDF, Konzepte für Projekte, Blogposts etc.
Die Texte in Nuclino sind alle mit Markdown verfasst. Die Blogposts sind seit jeher als Markdown gespeichert und PDFs kann man bequem mit pandoc aus Markdown-Dateien generieren.
Was wir als erstes brauchen ist ein Mapping, damit wir bei den Brains – Sammlungen von Dokumenten in einem Workspace – anstelle der UUIDs mit konkreten Namen arbeiten können.
Außerdem benötigen wir ein Mapping der UUIDs zu Dateinamen und Titeln. Mit Hilfe dieses Mappings Übersetzen wir die Links mit der Nuclino-Domain in Links mit einer beliebigen neuen Domain setzen die Titel der Dateien als Überschrift in die Dokumente ein.
Wir wollen also so etwas:
{
"brains" : {
"0184e034-3156-11eb-bf6d-2bbce7395d9b":"Kunden",
"0f0b2e2a-3156-11eb-a397-97d9e025800c":"FeatureAddons",
"14c45b66-3156-11eb-bf04-835bcdf7bdc7":"PerlAcademy",
...
},
"documents" : {
"19c8e5e6-3156-11eb-ba6d-8beba50b7276": {
"file":"index.html",
"title":"index.html"
},
"27fc869a-3156-11eb-98f5-8f9deed3e298": {
"file":"GraphQL vs. REST 0051eb4b.md",
"title":"GraphQL vs. REST"
},
...
}
}
Wer sich mit Nuclino auseinandersetzt, wird schnell feststellen, dass da nur ganz wenige normale
HTTP-Anfragen abgesetzt werden. Der Informationsaustausch zwischen Browser und Server erfolgt über Websockets.
Also ist wieder eine Analyse der Kommunikation notwendig. Da helfen wieder die Entwicklertools des Browsers mit der Netzwerkanalyse. Auch wenn man in Nuclino arbeitet, kommen keine weiteren Requests in der Übersicht hinzu.
Dann kommt man schnell zu dem einen Websocket...

Diese Kommunikation muss mit Mojolicious nachgebaut werden. Das schöne an Mojolicious ist, dass es schon alles mitbringt – so auch die Unterstützung für Websockets.
my $ua = Mojo::UserAgent->new(
cookie_jar => Mojo::UserAgent::CookieJar->new,
max_connections => 200,
inactivity_timeout => 20,
request_timeout => 20,
);
my ($info, @brains) = _get_brains( $ua );
my @promises = _create_mapping( $ua, $info, \@brains, $home_dir );
Mit der Funktion _get_brains werden die Zip-Dateien der Brains geholt und in $info stehen der Benutzername und weitere Infos. Auch bei _create_mapping arbeiten wir wieder mit Promises. Ein Promise repräsentiert das Ergebnis einer asynchronen Operation. Je nachdem, ob die Operation erfolgreich oder fehlerhaft beendet wurde, wird das Promise entsprechend gekennzeichnet.
In _create_mapping bauen wir die Websocket-Verbindung mit Nuclino auf.
sub _create_mapping {
my ( $ua, $info, $brains, $home_dir ) = @_;
my $mapping = {};
my $promise = Mojo::Promise->new;
$ua->websocket(
'wss://api.nuclino.com/syncing' => {
Via => '1.1 vegur',
Origin => 'https://app.nuclino.com',
} => ['v1.proto'] => sub {
# ... hier der Code fuer den Informationsaustausch
});
}
Ist die Verbindung aufgebaut, müssen wir festlegen, was mit eingehenden Nachrichten passieren soll. Und wenn die Verbindung geschlossen wird, müssen die zusammengetragenen Informationen als JSON-Datei gespeichert wird.
Betrachten wir also nur die Subroutine, die bei websocket als Callback übergeben wird:
my ($ua, $tx) = @_;
return if !$tx->isa('Mojo::Transaction::WebSocket');
$tx->on( message => sub {
my ($tx, $msg) = @_;
_handle_message( $tx, $msg, $mapping );
});
$tx->on( finish => sub {
my ($tx) = @_;
# generate JSON file for mapping
$home_dir->child('backups', 'mapping.json')->spurt(
encode_json $mapping
);
$promise->resolve(1);
});
Trifft eine Nachricht vom Server ein, wird ein message-Event gefeuert. Wir reagieren mit $tx->on( message => sub {...} ); darauf. Was in der Funktion _handle_message passiert, schauen wir uns später an.
Mit $tx->on( finish => sub {...} ); reagieren wir auf das Ende der Verbindung. Da wird einfach nur die JSON-Datei geschrieben und mit $promise->resolve(1) wird gesagt, dass das Promise erfolgreich abgearbeitet wurde.
Im weiteren Verlauf des Callbacks setzen wir die Eingangs-Requests ab, die weiter oben beschrieben sind:
$tx->send( encode_json +{
ns => 'sd',
data => {
a => 's',
c => 'ot_config',
d => 'a16b46be-31a7-11eb-ad70-e338b15b7ae1',
}
});
# hier noch die Requests fuer die Kommandos
# ot_user, ot_user_private, ot_team
Mojo::IOLoop->timer( 3 => sub {
for my $brain ( @{$brains} ) {
$tx->send( encode_json +{
ns => 'sd',
data => {
a => 's',
c => 'ot_brain',
d => $brain,
}
});
}
});
Die UUID im ersten Request ist immer die gleiche. Das ist vermutlich die UUID unseres Unternehmensaccounts.
Danach folgen noch drei weitere Requests. Diese können direkt nacheinander abgesetzt werden.
Abschließend folgt noch für jeden brain ein Request. Hier hat es in den Tests nie geklappt, die direkt nach den zuvor genannten Requests abzusetzen. Die genannten vier Requests müssen erst abgearbeitet sein, bevor es weiter geht.
Mit den hier gezeigten Requests werden die Infos zu einem brain geholt. Die Daten kommen als JSON an und sehen folgendermaßen aus:
{
"ns":"sd",
"data":{
"data":{
"v":2,
"data":{
"kind":"PUBLIC",
"name":"Werkzeuge",
"teamId":"1f2966e2-321d-11eb-8f00-5b043dffbd53",
"members":[],
"createdAt":"2019-07-17T15:40:28.897Z",
"creatorId":"2a9e9ad8-321d-11eb-a81f-631faf46d6c4",
"mainCellId":"320c3df2-321d-11eb-9604-fbfbed008d34",
"defaultView":"TREE",
"trashCellId":"377bf386-321d-11eb-b969-3fea1f109107",
"archiveCellId":"3de4e624-321d-11eb-a864-67366681e78f",
"formerMembers":[],
"pinnedCellIds":[],
"defaultMemberRole":"MEMBER"
},
"type":"https://nuclino.com/ot-types/json01"
},
"a":"s",
"c":"ot_brain",
"d":"7091aff1-1513-4e68-ae9f-d6f8936fcf14"
}
}
Die Funktion _handle_message nimmt die Antworten des Servers auseinander und sammelt die Daten für das Mapping. Die Antworten des Servers für ot_brain enthalten Angaben über die Zellen – also die Seiten des Brains. Für jede dieser Seiten werden wieder Requests abgesetzt.
sub _handle_message {
my ($tx, $msg, $mapping) = @_;
my $data;
eval {
$data = decode_json( encode_utf8 $msg );
};
return if !$data;
my $command = $data->{data}->{c} || '';
return if !( first { $command eq $_ }qw(ot_cell ot_brain) );
# ziehe die Informationen aus den JSON-Antworten
for my $cell ( @cell_ids ) {
$tx->send( encode_json +{
ns => 'sd',
data => {
a => 's',
c => 'ot_cell',
d => $cell,
}
});
}
}
Die Ergebnisse der weiter oben gezeigten Kommandos wie ot_user,* ot_user_private*, *ot_config und ot_team* interessieren uns nicht, da dort keine Informationen über die Dateien zu finden sind. Aus diesem Grund werden die hier nicht behandelt.
In den Antworten für das ot_brain stehen dann Informationen, mit denen wir weiterarbeiten können. In mainCellId steht die UUID des Hauptdokuments. Für dieses Dokument holen wir mit ot_cell die näheren Informationen*.*
{
"ns":"sd",
"data":{
"data":{
"v":18,
"data":{
"kind":"MAIN",
"title":"Main",
"brainId":"a29de3ff-18a5-4d51-ab9b-a6c3b5d82b6c",
"sharing":{},
"childIds":[
"bb10e948-ba91-4097-83a1-60c9ea6ec17b",
"4d44737d-e113-4786-bb98-06d8755d2bb7",
"..."
],
"createdAt":"2019-07-17T14:47:35.743Z",
"creatorId":"34e53829-cafb-4859-9e7b-0aae34295d04",
"memberIds":[],
"updatedAt":"2019-07-17T14:47:35.743Z",
"activities":[],
"contentMeta":{},
},
"type":"https://nuclino.com/ot-types/json01"
},
"a":"s",
"c":"ot_cell",
"d":"d56942a8-aa6e-4197-93fd-1f88967dedc6"
}
}
Die wichtigen Informationen sind der Typ des Dokuments – MAIN ist das Startdokument eines brains, PARENT ein Knoten und LEAF ein Dokument mit Text –, der Titel und die Kinddokumente, für die dann ebenfalls die Informationen geholt werden.
Was haben wir gelernt? Wir haben die Websocket-Kommunikation zwischen Nuclino und dem Browser analysiert, und wir haben gesehen, dass Mojolicious bei der Umsetzung extrem hilfreich ist, weil die Unterstützung für Websockets direkt mit eingebaut ist.
Permalink: /2020-12-11-nuclino-backup-III
Perl-Schulungen 2021
Nachdem wir uns das Jahr 2020 Zeit genommen haben, um die Perl-Academy etwas umzubauen (mit neuem Design, der Einführung dieses Blogs, mit Gregor als zusätzlicher Trainer, ...), wollen wir heute unseren Plan für 2021 vorstellen.
Wir werden wenige feste Termine für offene Schulungen haben. Wir wollen mehr Firmenschulungen anbieten und offene Schulungen zusätzlich planen, wenn sich Interessenten melden.
Unsere Schulungsthemen werden wir am Lebenszyklus einer Anwendung ausrichten. Auch in agilen Umgebungen hat man immer wieder den Lebenszyklus in klein. Momentan haben wir vier Themen geplant:
Einsteigen werden wir mit User Story Mapping
. Kein originäres Perl-Thema, aber eine ganz praktische Vorgehensweise, um eine Anwendung aus Sicht des Benutzers zu planen.
Die mit User Story Mapping
geplante Software werden wir mit Mojolicious umsetzen. Dabei werden wir mit einer kleinen Version anfangen um die Grundlagen von Mojolicious kennenzulernen. Anschließend werden wir die Anwendung wachsen lassen, um die weitergehenden Fähigkeiten von Mojolicious nutzen zu können.
Natürlich muss man nicht erst die User-Story-Mapping Schulung besucht haben, um an der Mojolicious-Schulung teilzunehmen.
Das Thema Sicherheit in Perl-Anwendungen
spielt natürlich auch bei Mojolicious-Anwendungen ein Thema. Wir haben eine eigene Schulung daraus gemacht, um dem Ganzen genügend Raum zu geben und uns nicht auf Mojolicious zu beschränken.
Als viertes Thema bieten wir Gitlab und Perl
an. Die Versionsverwaltung begleitet die Anwendung ein Leben lang. Wir zeigen, was man abseits der reinen Versionsverwaltung mit Gitlab machen kann – von Continuous Integration
bis zum Ausliefern der Anwendung.
Interesse an einer der Schulungen? Dann melden Sie sich bei uns!
Permalink: /2020-12-07-schulungen-2021
Perl-Schulungen vor dem Deutschen Perl-/Raku-Workshop 2021 in Leipzig
Auch während der aktuell hohen Infektionszahlen in der Corona-Pandemie schauen wir nach vorne. Nach aktuellem Stand findet der Deutsche Perl-/Raku-Workshop 2021 Ende März in Leipzig statt (sollte die Corona-Situation das nicht hergeben, wird da mit Sicherheit reagiert).
Wir wollen den Workshop zum Anlass nehmen, am Tag vorher (23. März 2021) zwei Halbtagesschulungen anzubieten:
- Gitlab und Perl
- REST-APIs mit Mojolicious umsetzen
Den Tag beginnen wird Gregor mit Gitlab und Perl
. In dem Kurs, der von 08:00 Uhr bis 12:00 Uhr stattfinden wird, geht es um die Entwicklung von Perl-Distributionen mit Hilfe der Plattform Gitlab. Gregor wird anhand einer CPAN-Distribution kurz die hierfür relevanten integrierten Komponenten der Plattform vorstellen und insbesondere auf die continuous integration eingehen. Ein Schwerpunkt liegt hier auf der schnellen Rückmeldung an Entwickler nach einem Commit.
Am Nachmittag (13:30 Uhr bis 17:30 Uhr) geht es dann um REST-APIs mit Mojolicious. Ich werde hierbei kurz auf REST an sich eingehen, bevor eine Schnittstelle definiert und dann als Mojolicious-Anwendung mit Leben gefüllt wird. Dabei werden dann auch Themen wie Sicherheit etc. angesprochen. Zum Abschluss wird die Schnittstelle noch getestet.
Als Veranstaltungsort ist das Hotel Michaelis geplant und die Teilnehmerzahl ist auf 10 Personen pro Schulung beschränkt.
Wer Interesse an einer der Schulungen hat, kann sich gerne bei uns melden. Die Teilnahme an einer Schulung kostet 200,00 € netto (238,00 € inkl. MwSt), ein Kombiticket für beide Schulungen kostet 350,00 € netto (416,50 € inkl. MwSt).
Wir werden natürlich die Entwicklungen bzgl. Corona weiter im Auge behalten. Sollte eine Präsenzveranstaltung nicht möglich sein, werden wir die Schulungen als Online-Veranstaltung anbieten.
Permalink: /2020-11-10-gpw-schulungen
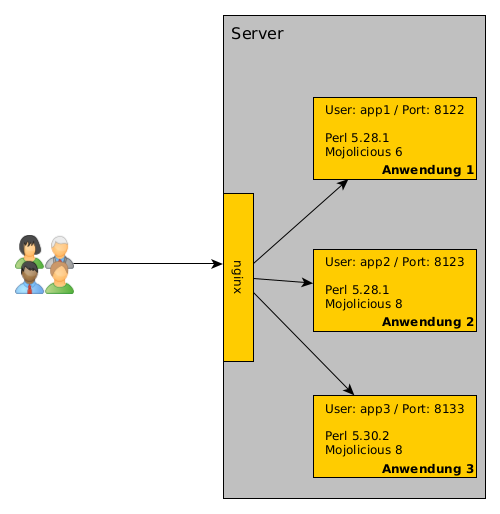
Wie wir unsere Apps betreiben...
Wir haben bei uns etliche Mojolicious-Anwendungen laufen. Dieses Blog, Perl-Academy.de sind Anwendungen und bei OPMToolbox.de sind es mehrere Anwendungen.
Die liegen teilweise auf dem gleichen Server. Jetzt stellt sich vielleicht die Frage, wie wir das dann betreiben. Die Antwort ist einfach: In der Regel gibt es für jede Anwendung einen eigenen User auf dem Server. Der startet die Anwendung mit hypnotoad. Und es gibt einen nginx, der als Reverse Proxy dient.
Installation der Anwendung
Warum jeweils ein eigener User? Warum alles hinter dem nginx?
Es gibt immer einen eigenen User, weil wir nicht alles mit root oder einem anderen User laufen lassen möchten. Und es hat den Vorteil, dass wir bei jedem User eine eigene Perl-Umgebung aufbauen können. Das heißt, dass wir mit perlbrew mindestens die Perl-Version installieren, mit der die Anwendung entwickelt wurde und auch die Module installieren, die die Anwendung braucht.
Das sieht dann so aus
$ useradd -m -s /bin/bash academy-blog
$ su - academy-blog
$ wget -O - https://install.perlbrew.pl | bash
$ source perl5/perlbrew/etc/bashrc
$ perlbrew install 5.30.2
$ perlbrew use 5.30.2
$ wget -O - https://cpanmin.us | perl - App::cpanminus
$ git clone <academy-blog> blog
$ cd blog
$ cpanm --installdeps .
$ hypnotoad blog
So muss ich auch nicht aufpassen, ob eine neue Mojolicious-Version eine Funktion rausgeschmissen hat oder eine andere Inkompatibilität mit sich bringt. So lange es läuft und an der Anwendung nichts geändert wird, kann die Umgebung so bleiben wie sie ist.
Eine andere Anwendung beeinflusst diese nicht. Egal, ob die andere Anwendung mit einer neuere Mojolicious-Version entwickelt wurde oder es vielleicht auch Module gibt, die sich gegenseitig ausschließen.
Natürlich bringt das unter Umständen mehr Aufwand mit sich, wenn in Modulen Sicherheitslücken auftauchen und dann eben mehrere Installationen angepasst werden müssen. Aber das kommt zum Glück nicht häufig vor.
Damit der User immer gleich das richtige
Perl nutzt, nehmen wir noch eine kleine Änderung in der .bashrc vor: Wir laden dort perlbrew und die richtige Perl-Version:
source /home/academy-blog/perl5/perlbrew/etc/bashrc
perlbrew use 5.30.2
Wie wir sicherstellen, dass die Anwendung auch nach einem Serverneustart automatisch starten, zeige ich in einem späteren Blogpost.
Warum keine Container wie z.B. Docker? Weil wir (noch) nicht dazu gekommen sind, alles in Docker-Container zu packen. Das wird langfristig unser Ziel sein. Sobald wir soweit sind, berichten wir hier auch darüber.
Wenn alles installiert ist und die Anwendung läuft, ist sie von außen noch nicht erreichbar, weil wir die Anwendung immer nur auf 127.0.0.1:#port
lauschen lassen. Es wäre ja auch blöd, wenn die Besucher*innen bei jeder Anwendung auch den Port kennen müssen.
Aus diesem Grund nutzen wir den nginx als Reverse Proxy. Außerdem ist die Nutzung von SSL damit ziemlich einfach.
nginx
Als erstes installieren wir den nginx
$ apt install nginx
Nach der Installation von nginx, packen wir für jede Anwendung eine eigene Konfigurationsdatei in den Ordner /etc/nginx/conf.d.\ Hier ein Beispiel:
upstream academy-blog {
server 127.0.0.1:8080;
}
server {
listen 80;
server_name blog.perl-academy.de;
location /.well-known/acme-challenge {
root /home/academy-blog/letsencrypt/challenge/;
}
location / {
return 301 https://blog.perl-academy.de$request_uri;
}
}
server {
listen 443 ssl;
server_name perl-academy.de www.perl-academy.de;
ssl_certificate /home/academy-blog/letsencrypt/live/blog.perl-academy.de/fullchain.pem
ssl_certificate_key /home/academy-blog/letsencrypt/live/blog.perl-academy.de/privkey.pem;
root /home/academy-blog/web/public/;
try_files $uri @academy_app;
location @academy_app {
proxy_read_timeout 300;
proxy_pass http://academy-blog;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-HTTPS 0;
}
}
Der upstream-Block bestimmt einen anderen Server, an den Anfragen weitergeleitet werden können. Hier nutzen wir einen sprechenden Namen. Es ist zu sehen, dass hypnotoad hier auf Port 8080 lauscht.
Anschließend kommt ein server-Block, der Anfragen auf Port 80 (http) behandelt. Wir legen den Servernamen fest. Es werden also Anfragen auf Port 80 für blog.perl-academy.de behandelt. Innerhalb dieses Blocks gibt es zwei location-Blöcke. Der erste ist wichtig, um später bequem LetsEncrypt-Zertifikate installieren zu können. Der zweit leitet HTTP-Anfragen auf HTTPS um.
Der zweite server-Block sorgt dafür, dass nginx auf Port 443 lauscht und SSL aktiviert ist. So lange die LetsEncrypt-Zertifikate nicht da sind, sollte dieser server-Block deaktiviert/auskommentiert werden.
Wir setzen den root der Dateien auf den public-Ordner der Anwendung. Im Zusammenspiel mit dem try_files sorgen wir dafür, dass statische Dateien nicht über die Mojolicious-Anwendung ausgeliefert werden, sondern direkt vom nginx. try_files prüft, ob eine Datei (die dann in $uri steht) existiert und liefert sie dann aus. Existiert sie nicht, greift der benamte Fallback (hier: @academy_app). Diesen benamten Fallback kann man sich wie eine Subroutine vorstellen. Der Fallback ist dann darauf definiert mit dem location-Block
Das Entscheidende ist die Zeile mit proxy_pass. Die bedeutet, das die Anfragen weitergeleitet werden. Hier taucht auch wieder der Name auf, den wir weiter oben bei upstream definiert haben.
SSL mit LetsEncrypt
Nachdem der nginx läuft, gehen wir den nächsten Schritt an: SSL-Verschlüsselung. Am einfachsten ist es, LetsEncrypt-Zertifikate zu nutzen. Dazu müssen wir certbot installieren:
$ apt install certbot
Anschließend können wir als User die SSL-Zertifikate generieren lassen:
$ su - academy-blog
$ mkdir -p letsencrypt/challenge
$ certbot certonly --config-dir /home/academy-blog/letsencrypt \
--work-dir /home/academy-blog/letsencrypt \
--logs-dir /home/academy-blog/letsencrypt \
-d blog.perl-academy.de
Das Programm führt dann durch die Konfiguration. Da wir in der nginx-Konfiguration schon angegeben haben, wo an welcher Stelle LetsEncrypt auf Dateien zugreifen kann. An diese Stelle soll certbot Dateien packen:
How would you like to authenticate with the ACME CA?
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1: Spin up a temporary webserver (standalone)
2: Place files in webroot directory (webroot)
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Select the appropriate number [1-2] then [enter] (press 'c' to cancel): 2
Plugins selected: Authenticator webroot, Installer None
Enter email address (used for urgent renewal and security notices) (Enter 'c' to
cancel): xxxx@perl-services.de
Man muss noch den Terms of Service
zustimmen und anschließend noch das Verzeichnis, das über nginx erreichbar ist, angeben und dann sollte das Zertifikat erzeugt werden.
Läuft alles durch, kann der server-Block für das SSL in der nginx-Konfiguration wieder aktiviert werden.
Da die LetsEncrypt-Zertifikate nur jeweils 3 Monate gültig sind, müssen diese regelmäßig erneuert werden. Hier empfiehlt es sich, einen Cronjob einzurichten:
$ crontab -e
Und dort
0 5 15,30 * * certbot renew --config-dir ... --work-dir ... --logs-dir ...
eintragen.
Zusammenfassung
Für jede Anwendung nutzen wir einen eigenen User, damit wir komplett eigenständige Umgebungen haben. Die Anwendungen sind hinter\
einem nginx als Reverse Proxy. Für die SSL-Verschlüsselung nutzen wir certbot. In einem Bild zusammengefasst, sieht\
das dann so aus:
Sollten Sie noch Fragen oder Anregungen haben, melden Sie sich einfach.
Permalink: /2020-10-05-wie-wir-apps-betreiben
Nuclino-Backup mit Mojolicious - Teil 2
Im ersten Teil habe ich gezeigt, wie wir mit Mojolicious das Login umsetzen und die sogenannten Brains von Nuclino als zip-Archiv holen. Jetzt geht es zum einen darum, die Inhalte als einzelne Markdown-Dateien abzulegen und in unserem Gitlab zu speichern und zum anderen die Abarbeitung zu beschleunigen.
Fangen wir mit dem Entpacken an... Hier nutzen wir Archive::Zip
# siehe Blogpost vom 15.08.2020
my ($info,@brains) = _get_brains( $ua );
my @zips = _download_backups( $ua, \@brains );
# ab hier ist es neuer Code
_extract_backups( \@zips );
_commit_and_push( $home_dir );
sub _extract_backups {
my $zips = shift;
say 'Extract backups ...';
my $obj = Archive::Zip->new;
for my $zip ( @{ $zips || [] } ) {
$obj->read( $zip->to_string );
$obj->extractTree('', $zip->dirname->to_string );
}
$_->remove for @{ $zips || [] };
}
Jedes einzelne zip-Datei wird eingelesen und der Inhalt wird in den backups-Ordner entpackt. Wir verzichten auf das Kommandozeilentool unzip, weil wir die Perl-Abhängigkeiten in einem cpanfile beschreiben können und nicht daran denken müssen das Tool zu installieren.
sub _commit_and_push {
my $home_dir = shift;
my $git = Git::Repository->new(
work_tree => $home_dir->to_string,
);
say "commit the changes";
$git->run(qw/add --all backups/);
my $date = Mojo::Date->new->to_datetime;
$git->run("commit", "-m", "nuclino backup $date") ;
$git->run(qw/push origin master/);
}
Zur Interaktion mit git nehmen wir Git::Repository, damit wir uns nicht um das Wechseln in Verzeichnisse etc. kümmern müssen. Die einzelnen run-Befehle enthält die gleichen Parameter wie git-Kommandos im Terminal.
Damit hätten wir ein Backup unserer Nuclino-Dokumente in einem git-Repository. Jetzt kümmern wir uns um Kleinigkeiten
.
Die Laufzeit spielt in diesem Skript nicht wirklich eine Rolle, da der aktuelle Stand nur einige Male am Tag geholt wird, ist es dann egal ob das Skript 10 oder 20 Sekunden läuft. Wir wollen aber die Möglichkeiten von Mojolicious nutzen.
Um die Zeit optimal zu nutzen, sollen mehrere Brains parallel abgeholt werden. Mit dem Committen der Änderungen muss allerdings gewartet werden, bis die zip-Dateien aller Brains abgeholt und entpackt wurden.
Zum Parallelisieren und wieder zusammenführen, nutzen wir Promises. Der Mojo::UserAgent hat schon entsprechende Methoden parat, mit denen Promises erzeugt werden können. Auf Promises werde ich auch in einem späteren Blogpost noch näher eingehen.
Bildlich dargestellt, soll das Ergebnis sich folgendermaßen verhalten:
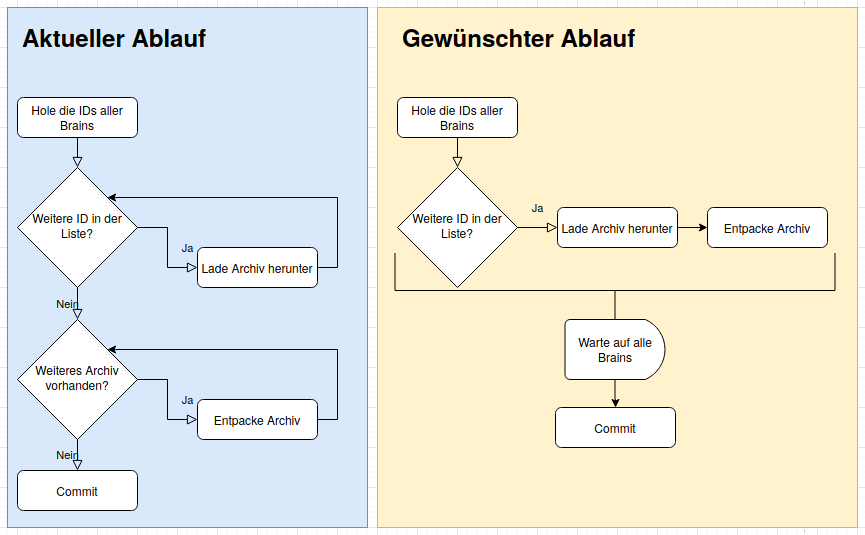
Durch die Promises stößt man das Herunterladen des Archivs an und ohne auf das Ergebnis zu warten, geht man zum nächsten Brain weiter. Damit das Programm aber nicht weitermacht bis alle Archive heruntergeladen und entpackt sind, benötigt man einen Mechanismus, der auf die ganzen Promises wartet.
Um parallel zwei URLs abzurufen und die Titel der Seiten auszugeben, kann man dieses einfache Programm nehmen.
#!/usr/bin/perl
use Mojo::Base -strict;
use Mojo::UserAgent;
my $ua = Mojo::UserAgent->new;
for my $url ( qw/perl-academy.de perl-services.de/ ) {
$ua->get_p( "https://www." . $url )->then( sub {
my ($tx) = @_;
say $tx->res->dom->find('title')->first->text;
})->wait;
}
An die bekannten Methoden wie get, post usw. wird einfach das _p angehängt und man bekommt ein Objekt vom Typ Mojo::Promise zurück. Wird kein Fehler geworfen, wird die Subroutine ausgeführt, die man der Methode then übergibt. Möchte man einen Fehler abfangen, muss man die Methode catch verwenden.
Um die Mojo-eigene Eventloop zu starten (und zu stoppen wenn der Promise erfüllt wurde) wird anschließend noch wait aufgerufen.
In dem Callback, den ich hier der Methode then übergebe wird einfach aus der Antwort ($tx->res) das DOM geholt, dort nach dem title-Tag gesucht und den Text des ersten Treffers ausgegeben.
Übertragen auf unser Nuclino-Backup rufen wir das Archiv des Brains nicht mehr mit get ab, sondern mit get_p. Wir warten nicht, bis alle Archive geholten wurden, bis diese entpackt werden. Das machen wir für das jeweilige Archiv wenn der Promise erfolgreich aufgelöst wurde (then).
Allerdings wollen wir den commit erst machen, wenn alle Archive geholt wurden.
Unser obiges Beispiel sieht entsprechend angepasst so aus:
#!/usr/bin/perl
use Mojo::Base -strict;
use Mojo::UserAgent;
use Mojo::Promise;
my $counter = 0;
my $ua = Mojo::UserAgent->new;
my @promises;
for my $url ( qw/perl-academy.de perl-services.de/ ) {
my $promise = $ua->get_p( "https://www." . $url )->then( sub {
my ($tx) = @_;
say $tx->res->dom->find('title')->first->text;
$counter++;
});
push @promises, $promise;
}
Mojo::Promise->all( @promises )->then( sub {
say "Found $counter titles";
})->wait;
Um zu zeigen, dass wirklich auf beide Abfragen gewartet wird, habe ich einen Zähler eingebaut. Wir nutzen auch kein wait beim get_p-Aufruf. Um auf eine Reihe von Promises zu warten nutzen wir all von Mojo::Promise. Das selbst wieder ein Promise zurückliefert. Wenn dieses all-Promise erfolgreich ist, wird der Callback ausgeführt, der bei then übergeben wird.
Der angepasste Code in unserem Programm sieht dann so aus:
# siehe Blogpost vom 15.08.20
my ($info,@brains) = _get_brains( $ua );
my @promises = _download_backups( $ua, \@brains );
Mojo::Promise->all( @promises )->then( sub {
_commit_and_push( $home_dir );
})->wait;
sub _download_backups {
my $ua = shift;
my $brains = shift;
say 'Download backups...';
my @promises;
my $backup_path = path(__FILE__)->dirname->child('..', 'backups')->realpath;
$backup_path->remove_tree({ keep_root => 1 });
for my $brain ( @{ $brains || [] } ) {
say '... for brain ' . $brain;
my $url = sprintf 'https://files.nuclino.com/export/brains/%s.zip?format=md', $brain;
my $promise = $ua->get_p(
$url
)->then( sub {
my ($tx_backup) = @_;
my $dir = $backup_path->child( $brain );
$dir->make_path;
my $zip_file = $dir->child( $brain . '.zip' );
$tx_backup->res->save_to( $zip_file->to_string );
_extract_backups( $zip_file->to_abs );
});
push @promises, $promise;
}
return @promises;
}
Es wird noch einen dritten Teil der Reihe geben, weil wir mittlerweile das Backup als Datenquelle für andere Anwendungen nutzen und dafür weitere Arbeiten nötig waren.
Permalink: /2020-09-22-nuclino-backup-II
Messung der Modul-Verwendung
Mich selbst interessiert auch die Frage, welches Modul vom CPAN wird eigentlich besonders häufig genutzt? Da CPAN keine Daten dazu speichert, wie oft ein Modul heruntergeladen wird ist das nicht so einfach zu beantworten. Ein Tweet hat mich dazu gebracht eine kleine Anwendung zu schreiben, bei der jeder seine/ihre cpanfiles hochladen kann: https://usage.perl-academy.de.
Momentan werden dabei nur die requires ausgewertet.
Ja, so lange es nicht besonders weit verbreitet ist, ist die Datenlage sehr dünn und natürlich kann man das leicht manipulieren in dem man die eigenen cpanfiles mehrfach hochlädt. Um eine Idee von häufig genutzten Modulen zu bekommen, ist die Anwendung ganz nützlich.
Ich plane mit der Zeit noch einige statistische Auswertungen hinzuzufügen. Ich werde dann hier im Blog davon berichten. Bis dahin hoffe ich, dass noch einige cpanfiles hochgeladen werden. Jede/r kann mithelfen!
Mit was haben wir die Anwendung umgesetzt? Natürlich mit Mojolicious. Weiterhin kommen noch Minion als JobQueue und PPI zum Parsen der cpanfiles zum Einsatz. Diese beiden Module werden wir hier im Blog noch genauer vorstellen.
Permalink: /2020-08-17-module-usage
Nuclino-Backup mit Mojolicious - Teil 1
Wir bei Perl-Services.de nutzen seit längerem Nuclino als Wissensdatenbank. Natürlich wollen wir unser Wissen auch gut gesichert wissen. Zum einen falls Nuclino irgendwann mal dicht machen sollte, zum anderen aber auch, damit wir jederzeit den Anbieter wechseln könnten.
Aus diesem Grund haben wir uns die Frage gestellt, wie wir ein Backup der Nuclino-Seiten umsetzen können. Aktuell gibt es leider noch kein API, über das wir das Backup erstellen und herunterladen können. Also müssen wir irgendwie anders an die Daten kommen. Jede einzelne Seite besuchen und herunterladen? Da bräuchten wir eine Liste der Seiten. Das muss doch auch anders gehen...
Was ist Nuclino?
Nuclino ist eine Webanwendung, in der man schnell viel Texte ablegen kann. Diese Texte werden in hierarchischer Form abgelegt. Man kann sogenannte Workspaces zu den verschiedensten Themen anlegen. Innerhalb dieser Workspaces kann man die Texte wiederum in Clustern gruppieren.
Das sieht dann beispielsweise so aus:
Zur Formatierung wird Markdown eingesetzt. Die Markdown-Syntax wird auch direkt umgesetzt und gerendert. Ein Vorteil der Anwendung ist, dass mehrere Personen gleichzeitig an einem Dokument arbeiten können und man bekommt die Änderungen gleich mit. So ist es z.B. möglich, direkt während eines Telefonats Dokumente zu ändern und über die Änderungen zu sprechen.
Die Gliederung der Texte ist erstmal - wie bereits gezeigt - hierarchisch. Man kann aber auch andere Darstellungen wählen, z.B. als Graphen oder als Board:
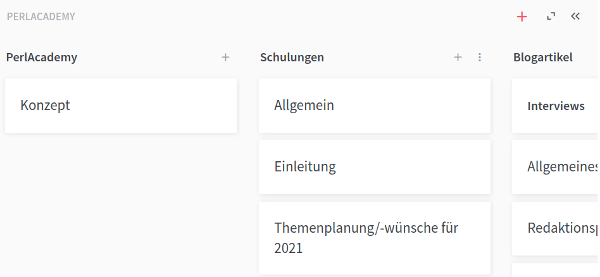
In den Texten selbst können Inhalte aus verschiedenen Diensten wie zum Beispiel Prezi oder Draw.io eingebettet werden.
Wie arbeitet die Anwendung?
Doch zurück zum Backup. Da es keine API gibt, mussten wir uns anschauen, wie die Anwendung arbeitet. Welche Funktionalitäten gibt es in der Webanwendung? Wie werden diese erreicht? Welche Requests werden ausgelöst?
Wer in der Anwendung etwas stöbert oder einfach die Hilfeseiten besucht, wird bei den Workspace-Settings die Funktion
Workspace exportieren
finden:
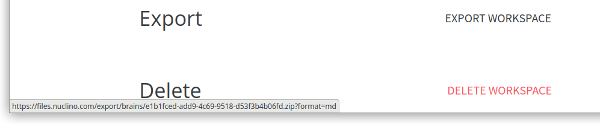
Man sieht beim Browser die Zieladresse des Links. Man bekommt also ein Zip-Archiv mit den Dokumenten im Markdown-Format – allerdings
nur, wenn man die UUID des Workspaces (oder wie im Link bezeichnet des Brains
) kennt.
Eine Liste der Workspaces händisch pflegen? Kommt nicht in Frage, das muss auch anders gehen! Die Anwendung selbst muss ja auch
irgendwoher wissen, welche Workspaces (oder Brains
) es gibt. Also mal die Developertools des Browsers geöffnet und dann schauen was passiert...
Wenn man sich die Netzwerkanalyse anschaut, fällt beim Login auf, dass neben Google-Analytics und Google-Fonts einige Requests an api.nuclino.com geschickt werden. Unter anderem der Login an sich, aber auch etwas mit inital-state.
Auf den Request sendet der Server als Antwort eine JSON-Struktur, in der auch die Brains
zu finden sind:
{
"response":{
"userId":"<user-uuid>",
"teams":[
{
"id":"<team-uuid>",
"data":{
"name":"<team-name>",
"brains":[
"734eaf2c-b066-11ea-81bd-a36778484b6c",
"820c6310-b066-11ea-9648-bbd09f732919",
...
],
...
Das passende Perl-Skript
Jetzt haben wir alle Informationen, um die Daten aus Nuclino zu sichern. Wir wollen aber mehr. Wir wollen auch die Änderungen sehen, die von Mal zu Mal vorgenommen wurden. Dafür verwalten wir unsere Datensicherung in einem Git-Repository.
Unser Skript muss also folgendes tun:
- Sich bei Nuclino einloggen
- Die UUIDs der Brains holen
- Für jeden Brain ...
- das Zip-Archiv herunterladen
- das Archiv in das Git-Repository entpacken
- Die Änderungen committen
- Die Änderungen auf den Server pushen
Die ersten beiden Punkte werden wie folgt abgearbeitet:
use Mojo::File qw(path);
use Mojo::JSON qw(decode_json);
use Mojo::UserAgent;
use Mojo::UserAgent::CookieJar;
my $ua = Mojo::UserAgent->new(
cookie_jar => Mojo::UserAgent::CookieJar->new,
max_connections => 200,
);
my $config = decode_json path(__FILE__)->sibling('nuclino.json')->slurp;
my $header = {
# header wie in den Developertools zu sehen
};
my $base_url = 'https://api.nuclino.com/api/users/';
my $tx_init = $ua->get('https://app.nuclino.com/login');
my $tx_login = $ua->post(
$base_url . 'auth' => $header => json => $config,
);
my $tx_initial_state = $ua->get(
$base_url . 'me/initial-state' => $header
);
my @brains = @{ $tx_initial_state->res->json('/response/teams/0/data/brains') || [] };
In $ua steckt ein Objekt von Mojo::UserAgent.
Mit diesem wird erstmal die Login-Seite abgerufen, um
ein initiales Cookie zu erhalten. Ohne dieses Cookie ist der Login nicht möglich.
Anschließend loggt sich das Skript bei Nuclino ein. Hier müssen die Header so gesetzt werden, wie es der Browser auch macht.
Mit dem Request an initial-state wird dann das JSON geholt, in dem die UUIDs der Brains
stehen.
Hier zeigt sich dann auch die Eleganz der Mojo-Klassen: Mit
$tx->res->json('/response/teams/0/data/brains');
kommt man sehr einfach an die Daten. Wenn die Gegenstelle in den HTTP-Headern den richtigen
Content-Type setzt, kann man über das Response-Objekt (->res) auf ein
Mojo::JSON::Pointer-Objekt
(->json) und damit auf die JSON-Datenstruktur zugreifen. Dazu wird ein XPath-änlicher String
übergeben.
Jetzt, wo wir die UUIDs der Brains
haben, können wir die Zip-Archive einfach herunterladen:
my $backup_path = path(__FILE__)->dirname->child('..', 'backups');
for my $brain ( @brains ) {
my $url = sprintf 'https://files.nuclino.com/export/brains/%s.zip?format=md', $brain;
my $tx_backup = $ua->get(
$url => {
# header wie in den Developertools zu sehen
},
);
my $dir = $backup_path->child( $brain );
$dir->make_path;
my $zip_file = $dir->child( $brain . '.zip' );
push @zips, $zip_file->to_abs;
$tx_backup->res->save_to( $zip_file );
}
Hier wird mit Mojo::File erstmal das Zielverzeichnis erstellt.
Anschließend wird für jeden Workspace das Zip-Archiv geholt. Für jeden Workspace wird ein eigenes
Verzeichnis erstellt, in das wir dann später die Dateien entpacken können.
Als Ergebnis des GET-Requests bekommen wir ein Mojo::Transaction-Objekt.
Wie schon oben gesehen, wollen wir wieder etwas mit der Antwort
(->res) anfangen. Wenn es keine Multipart-Antwort ist, kann der Inhalt der Antwort mit save_to in eine
Datei gespeichert werden.
Im nächsten Teil vollenden wir das Skript, indem wir die Dateien im Git-Repository speichern und das Skript noch etwas schneller machen.
Permalink: /2020-08-15-nuclino-backup-I