Nuclino-Backup mit Mojolicious - Teil 2
Im ersten Teil habe ich gezeigt, wie wir mit Mojolicious das Login umsetzen und die sogenannten Brains von Nuclino als zip-Archiv holen. Jetzt geht es zum einen darum, die Inhalte als einzelne Markdown-Dateien abzulegen und in unserem Gitlab zu speichern und zum anderen die Abarbeitung zu beschleunigen.
Fangen wir mit dem Entpacken an... Hier nutzen wir Archive::Zip
# siehe Blogpost vom 15.08.2020
my ($info,@brains) = _get_brains( $ua );
my @zips = _download_backups( $ua, \@brains );
# ab hier ist es neuer Code
_extract_backups( \@zips );
_commit_and_push( $home_dir );
sub _extract_backups {
my $zips = shift;
say 'Extract backups ...';
my $obj = Archive::Zip->new;
for my $zip ( @{ $zips || [] } ) {
$obj->read( $zip->to_string );
$obj->extractTree('', $zip->dirname->to_string );
}
$_->remove for @{ $zips || [] };
}
Jedes einzelne zip-Datei wird eingelesen und der Inhalt wird in den backups-Ordner entpackt. Wir verzichten auf das Kommandozeilentool unzip, weil wir die Perl-Abhängigkeiten in einem cpanfile beschreiben können und nicht daran denken müssen das Tool zu installieren.
sub _commit_and_push {
my $home_dir = shift;
my $git = Git::Repository->new(
work_tree => $home_dir->to_string,
);
say "commit the changes";
$git->run(qw/add --all backups/);
my $date = Mojo::Date->new->to_datetime;
$git->run("commit", "-m", "nuclino backup $date") ;
$git->run(qw/push origin master/);
}
Zur Interaktion mit git nehmen wir Git::Repository, damit wir uns nicht um das Wechseln in Verzeichnisse etc. kümmern müssen. Die einzelnen run-Befehle enthält die gleichen Parameter wie git-Kommandos im Terminal.
Damit hätten wir ein Backup unserer Nuclino-Dokumente in einem git-Repository. Jetzt kümmern wir uns um Kleinigkeiten
.
Die Laufzeit spielt in diesem Skript nicht wirklich eine Rolle, da der aktuelle Stand nur einige Male am Tag geholt wird, ist es dann egal ob das Skript 10 oder 20 Sekunden läuft. Wir wollen aber die Möglichkeiten von Mojolicious nutzen.
Um die Zeit optimal zu nutzen, sollen mehrere Brains parallel abgeholt werden. Mit dem Committen der Änderungen muss allerdings gewartet werden, bis die zip-Dateien aller Brains abgeholt und entpackt wurden.
Zum Parallelisieren und wieder zusammenführen, nutzen wir Promises. Der Mojo::UserAgent hat schon entsprechende Methoden parat, mit denen Promises erzeugt werden können. Auf Promises werde ich auch in einem späteren Blogpost noch näher eingehen.
Bildlich dargestellt, soll das Ergebnis sich folgendermaßen verhalten:
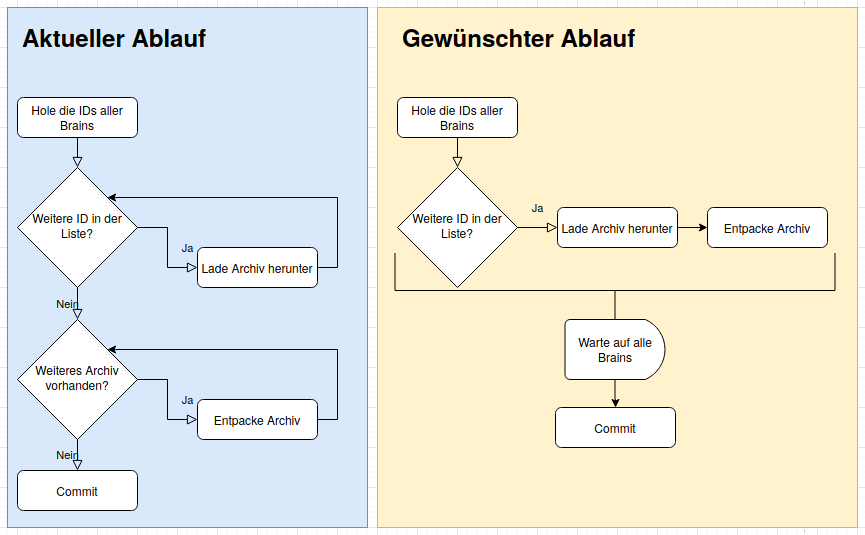
Durch die Promises stößt man das Herunterladen des Archivs an und ohne auf das Ergebnis zu warten, geht man zum nächsten Brain weiter. Damit das Programm aber nicht weitermacht bis alle Archive heruntergeladen und entpackt sind, benötigt man einen Mechanismus, der auf die ganzen Promises wartet.
Um parallel zwei URLs abzurufen und die Titel der Seiten auszugeben, kann man dieses einfache Programm nehmen.
#!/usr/bin/perl
use Mojo::Base -strict;
use Mojo::UserAgent;
my $ua = Mojo::UserAgent->new;
for my $url ( qw/perl-academy.de perl-services.de/ ) {
$ua->get_p( "https://www." . $url )->then( sub {
my ($tx) = @_;
say $tx->res->dom->find('title')->first->text;
})->wait;
}
An die bekannten Methoden wie get, post usw. wird einfach das _p angehängt und man bekommt ein Objekt vom Typ Mojo::Promise zurück. Wird kein Fehler geworfen, wird die Subroutine ausgeführt, die man der Methode then übergibt. Möchte man einen Fehler abfangen, muss man die Methode catch verwenden.
Um die Mojo-eigene Eventloop zu starten (und zu stoppen wenn der Promise erfüllt wurde) wird anschließend noch wait aufgerufen.
In dem Callback, den ich hier der Methode then übergebe wird einfach aus der Antwort ($tx->res) das DOM geholt, dort nach dem title-Tag gesucht und den Text des ersten Treffers ausgegeben.
Übertragen auf unser Nuclino-Backup rufen wir das Archiv des Brains nicht mehr mit get ab, sondern mit get_p. Wir warten nicht, bis alle Archive geholten wurden, bis diese entpackt werden. Das machen wir für das jeweilige Archiv wenn der Promise erfolgreich aufgelöst wurde (then).
Allerdings wollen wir den commit erst machen, wenn alle Archive geholt wurden.
Unser obiges Beispiel sieht entsprechend angepasst so aus:
#!/usr/bin/perl
use Mojo::Base -strict;
use Mojo::UserAgent;
use Mojo::Promise;
my $counter = 0;
my $ua = Mojo::UserAgent->new;
my @promises;
for my $url ( qw/perl-academy.de perl-services.de/ ) {
my $promise = $ua->get_p( "https://www." . $url )->then( sub {
my ($tx) = @_;
say $tx->res->dom->find('title')->first->text;
$counter++;
});
push @promises, $promise;
}
Mojo::Promise->all( @promises )->then( sub {
say "Found $counter titles";
})->wait;
Um zu zeigen, dass wirklich auf beide Abfragen gewartet wird, habe ich einen Zähler eingebaut. Wir nutzen auch kein wait beim get_p-Aufruf. Um auf eine Reihe von Promises zu warten nutzen wir all von Mojo::Promise. Das selbst wieder ein Promise zurückliefert. Wenn dieses all-Promise erfolgreich ist, wird der Callback ausgeführt, der bei then übergeben wird.
Der angepasste Code in unserem Programm sieht dann so aus:
# siehe Blogpost vom 15.08.20
my ($info,@brains) = _get_brains( $ua );
my @promises = _download_backups( $ua, \@brains );
Mojo::Promise->all( @promises )->then( sub {
_commit_and_push( $home_dir );
})->wait;
sub _download_backups {
my $ua = shift;
my $brains = shift;
say 'Download backups...';
my @promises;
my $backup_path = path(__FILE__)->dirname->child('..', 'backups')->realpath;
$backup_path->remove_tree({ keep_root => 1 });
for my $brain ( @{ $brains || [] } ) {
say '... for brain ' . $brain;
my $url = sprintf 'https://files.nuclino.com/export/brains/%s.zip?format=md', $brain;
my $promise = $ua->get_p(
$url
)->then( sub {
my ($tx_backup) = @_;
my $dir = $backup_path->child( $brain );
$dir->make_path;
my $zip_file = $dir->child( $brain . '.zip' );
$tx_backup->res->save_to( $zip_file->to_string );
_extract_backups( $zip_file->to_abs );
});
push @promises, $promise;
}
return @promises;
}
Es wird noch einen dritten Teil der Reihe geben, weil wir mittlerweile das Backup als Datenquelle für andere Anwendungen nutzen und dafür weitere Arbeiten nötig waren.
Permalink: /2020-09-22-nuclino-backup-II