Test::Perl::Critic::Progressive – Codier-Richtlinien Schritt für Schritt durchsetzen
Codier-Richtlinien haben als Ziel, die Formulierung von Code zu vereinheitlichen und ihn dadurch zu verbessern. Wenn sie bei einer bestehenden Code-Basis eingeführt werden, gibt es in der Regel zu Beginn viele Verstöße. Test::Perl::Critic::Progressive ist ein Werkzeug, um die Richtlinien für Perl-Code schrittweise durchzusetzen.
Die Einhaltung von Richtlinien mit perlcritic prüfen
Das Werkzeug perlcritic ist seit vielen Jahren das Standardwerkzeug, um Perl-Code statisch zu prüfen. Eine statische Prüfung wird im Gegensatz zur dynamischen Prüfung vor der Ausführung durchgeführt; es bedeutet also, dass der Code untersucht wird, ohne ihn auszuführen. Mit perlcritic kann so die Einhaltung von Codier-Richtlinien festgestellt werden.
Das folgende Beispiel zeigt einen Aufruf von perlcritic, der eine Datei auf Einhaltung der Richtlinie CodeLayout::RequireTidy prüft und einen Verstoß meldet:
$ perlcritic -s CodeLayout::RequireTidy lib/App/perldebs.pm
[CodeLayout::RequireTidyCode] Code is not tidy at lib/App/perldebs.pm line 1.
Durch die Einhaltung von Richtlinien kann eine Team unter anderem Folgendes erreichen:
- Das Verständnis über den Code wird verbessert, da er einheitlich geschrieben ist. Die Pflege und Erweiterung wird dadurch vereinfacht.
- Mitarbeiter können besser und schneller eingearbeitet werden, da die Richtlinien eine Hilfestellung zur Codierpraxis geben.
- Die Verwendung unsicherer Sprachkonstrukte kann aufgedeckt werden. Dadurch werden Sicherheitsprobleme verhindert.
Prüfen von Richtlinien als Test
Die Ablauflogik des Kommandozeilenwerkzeugs perlcritic kann über das\
Modul Test::Perl::Critic in die Testsuite eingebunden werden. Verstöße gegen die Richtlinien können so recht einfach aufgedeckt werden:
use Test::Perl::Critic;
all_critic_ok();
Eine Organisation erstellt selten zunächst ihre Richtlinien und entwickelt dann erst die Software anhand dieser Richtlinien. In der Regel ist der umgekehrte Fall der Normalfall: Eine existierende Code-Basis ist ohne Richtlinien geschrieben worden und die Organisation erhofft sich durch Durchsetzung der Richtlinien beispielsweise die oben genannten Vorteile.
Wenn nun bei vorhandener Code-Basis Richtlinien eingeführt werden, gibt es üblicherweise eine Reihe von Verstößen, da der Code vorher beliebig formuliert werden konnte. Die Entwickler sehen sich nun mit dem Problem konfrontiert, dass sie sich einerseits an die Richtlinien halten wollen oder sogar müssen, andererseits der existierende Code nicht zusätzlich zum Tagesgeschäft kurzfristig umgeschrieben werden kann.
Wie kann dieses Problem gelöst werden?
Iterative Verbesserung
Das Modul Test::Perl::Critic::Progressive kann hier eine technische Hilfestellung bieten. Es ist hiermit möglich, bei einer beliebigen Anzahl von Verstößen diese Schritt für Schritt zu beheben. Die Code-Basis kann so iterativ in eine Form überführt werden, die den Richtlinien entspricht.
Wie arbeiten dieses Modul nun?
Test::Perl::Critic::Progressive arbeitet ähnlich wie Test::Perl::Critic. Es verwendet die Prüflogik von perlcritic und sammelt beim ersten Aufruf die Anzahl der Verstöße jeder einzelnen Richtlinie. Die Sammlung wird in der Datei .perlcritic-history als Hash abgelegt:
$VAR1 = [
{
'Perl::Critic::Policy::CodeLayout::RequireTidy' => 10,
'Perl::Critic::Policy::BuiltinFunctions::ProhibitStringyEval' => 85,
'Perl::Critic::Policy::BuiltinFunctions::RequireGlobFunction' => 0,
'Perl::Critic::Policy::ClassHierarchies::ProhibitOneArgBless' => 2,
...
}
];
Bei jedem weiteren Aufruf wird diese Sammlung erneut erstellt. Beide Sammlungen werden nun in einem Test miteinander verglichen. Dieser Test schlägt fehl, wenn die Anzahl von Verstößen bei einer Richtlinie angestiegen ist:
CodeLayout::RequireTidy: Got 54 violation(s). Expected no more than 36.
Mit Test::Perl::Critic::Progressive kann man also sicherstellen, dass die Anzahl der Verstöße gegen die festgelegten Richtlinien nicht ansteigt.
Neben dieser technischen Lösung muss es noch organisatorische Änderungen geben, damit der Code auch wirklich verbessert wird. In der Regel bedeutet dies, dass den Entwicklern Zeit für die Verbesserung gegeben werden muss.
Nur dann, wenn das Team neben den technischen Lösung des Auffindens von Problemen zusätzlich noch Verfahren umsetzt, um den Code anhand der Empfehlungen der Richtlinien umzuformulieren, können die Entwickler schrittweise die Verstöße reduzieren. Sie werden dann nach und nach die Code-Basis überarbeiten und im Sinne der Richtlinien verbessern.
Best Practice
- Grundsätzlich ist
Test::Perl::Critic::Progressivedurch seine iterative Arbeitsweise gut geeignet, in agilen Entwicklungsteams eingesetzt zu werden. - Der Basissatz von Richtlinien, die bei der Installation von
perlcriticvorhanden sind, sollte auf keinen Fall vollständig eingebunden werden, da er veraltet ist. - Es ist ratsam, mit wenigen Richtlinien zu beginnen. Die Entwickler werden so durch schnelle Erfolgserlebnisse motiviert und erfahren den praktischen Nutzen von Richtlinien. Außerdem sollten die Entwickler bei der Auswahl der Richtlinien beteiligt werden, um die Akzeptanz zu erhöhen.
- Das Team sollte entscheiden, ob es zunächst die Verstöße einzelner Richtlinien auf 0 verringern möchte oder ob einzelne Dateien vollständig bereinigt werden sollen.
- Wenn das Team problematische Codierweisen entdeckt hat, sollte es für die Aufdeckung dieser Schreibweisen auf CPAN nach ergänzenden Richtlinien suchen oder eigene Richtlinien entwickeln.
- Nach Möglichkeit sollte
Test::Perl::Critic::Progressivein Versionskontrollsystemen so eingesetzt werden, dass abgelehnter Code nicht eingecheckt werden kann, um dem Entwickler schnellstmögliche Rückmeldung zu geben. - Unterstützend kann ein mit
Test::Perl::Critic::Progressivedurchgeführter Test in einem CI-System zu Beginn der Testsuite laufen, um dem Entwickler schnell Rückmeldung zu geben. Test::Perl::Critic::ProgressiveverwendetPerl::Criticund somit die DistributionPPI. Letztere ist bei großen Codemengen langsam und führt zu langen Feedback-Zyklen.Test::Perl::Critic::Progressivesollte in einem CI-System daher nicht auf allen Quellen angewendet werden. Ist das nicht möglich, so sollte die Verwendung parallel zur restlichen Testsuite ablaufen.
Zusammenfassung
Test::Perl::Critic::Progressive ist ein Werkzeug, um Codier-Richtlinien schrittweise durchzusetzen. In Verbindung mit einem Vorgehen zum Beheben von Verstößen gegen diese Richtlinien kann es eingesetzt werden, um eine Code-Basis im Team nach und nach zu verbessern.
Links
- Test::Perl::Critic::Progressive
- Test::Perl::Critic
- Perlcritic-Richtlinien auf CPAN
- Anleitung zum Schreiben eigener Perlcritic-Richtlinien
- perlcritic
- PPI
- Gradually improving our code quality with Test::Perl::Critic::Progressive: Einsatz von\
Test::Perl::Critic::Progressiveauf Jenkins unter Verwendung von Git. - App::Critique – An incremental refactoring tool for Perl powered by
Perl::Critic: Ein verwandtes Werkzeug, mit dem eine Entwicklerin iterativ in einer Arbeitssitzung Verstöße gegen Richtlinien beheben kann.
Permalink: /2020-08-25-test-perl-critic-progressive
Messung der Modul-Verwendung
Mich selbst interessiert auch die Frage, welches Modul vom CPAN wird eigentlich besonders häufig genutzt? Da CPAN keine Daten dazu speichert, wie oft ein Modul heruntergeladen wird ist das nicht so einfach zu beantworten. Ein Tweet hat mich dazu gebracht eine kleine Anwendung zu schreiben, bei der jeder seine/ihre cpanfiles hochladen kann: https://usage.perl-academy.de.
Momentan werden dabei nur die requires ausgewertet.
Ja, so lange es nicht besonders weit verbreitet ist, ist die Datenlage sehr dünn und natürlich kann man das leicht manipulieren in dem man die eigenen cpanfiles mehrfach hochlädt. Um eine Idee von häufig genutzten Modulen zu bekommen, ist die Anwendung ganz nützlich.
Ich plane mit der Zeit noch einige statistische Auswertungen hinzuzufügen. Ich werde dann hier im Blog davon berichten. Bis dahin hoffe ich, dass noch einige cpanfiles hochgeladen werden. Jede/r kann mithelfen!
Mit was haben wir die Anwendung umgesetzt? Natürlich mit Mojolicious. Weiterhin kommen noch Minion als JobQueue und PPI zum Parsen der cpanfiles zum Einsatz. Diese beiden Module werden wir hier im Blog noch genauer vorstellen.
Permalink: /2020-08-17-module-usage
Nuclino-Backup mit Mojolicious - Teil 1
Wir bei Perl-Services.de nutzen seit längerem Nuclino als Wissensdatenbank. Natürlich wollen wir unser Wissen auch gut gesichert wissen. Zum einen falls Nuclino irgendwann mal dicht machen sollte, zum anderen aber auch, damit wir jederzeit den Anbieter wechseln könnten.
Aus diesem Grund haben wir uns die Frage gestellt, wie wir ein Backup der Nuclino-Seiten umsetzen können. Aktuell gibt es leider noch kein API, über das wir das Backup erstellen und herunterladen können. Also müssen wir irgendwie anders an die Daten kommen. Jede einzelne Seite besuchen und herunterladen? Da bräuchten wir eine Liste der Seiten. Das muss doch auch anders gehen...
Was ist Nuclino?
Nuclino ist eine Webanwendung, in der man schnell viel Texte ablegen kann. Diese Texte werden in hierarchischer Form abgelegt. Man kann sogenannte Workspaces zu den verschiedensten Themen anlegen. Innerhalb dieser Workspaces kann man die Texte wiederum in Clustern gruppieren.
Das sieht dann beispielsweise so aus:
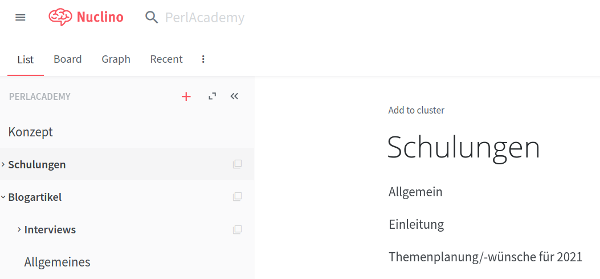
Zur Formatierung wird Markdown eingesetzt. Die Markdown-Syntax wird auch direkt umgesetzt und gerendert. Ein Vorteil der Anwendung ist, dass mehrere Personen gleichzeitig an einem Dokument arbeiten können und man bekommt die Änderungen gleich mit. So ist es z.B. möglich, direkt während eines Telefonats Dokumente zu ändern und über die Änderungen zu sprechen.
Die Gliederung der Texte ist erstmal - wie bereits gezeigt - hierarchisch. Man kann aber auch andere Darstellungen wählen, z.B. als Graphen oder als Board:
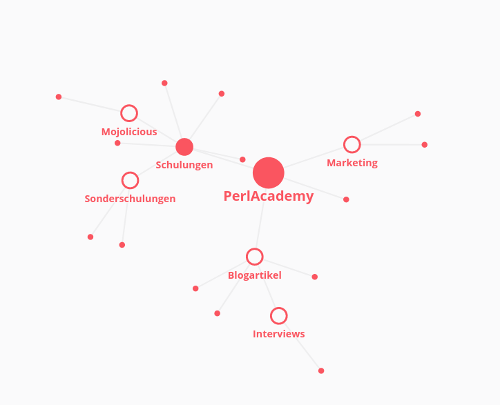
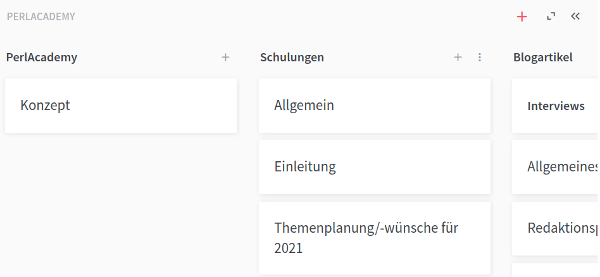
In den Texten selbst können Inhalte aus verschiedenen Diensten wie zum Beispiel Prezi oder Draw.io eingebettet werden.
Wie arbeitet die Anwendung?
Doch zurück zum Backup. Da es keine API gibt, mussten wir uns anschauen, wie die Anwendung arbeitet. Welche Funktionalitäten gibt es in der Webanwendung? Wie werden diese erreicht? Welche Requests werden ausgelöst?
Wer in der Anwendung etwas stöbert oder einfach die Hilfeseiten besucht, wird bei den Workspace-Settings die Funktion
Workspace exportieren
finden:
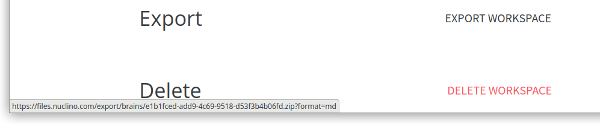
Man sieht beim Browser die Zieladresse des Links. Man bekommt also ein Zip-Archiv mit den Dokumenten im Markdown-Format – allerdings
nur, wenn man die UUID des Workspaces (oder wie im Link bezeichnet des Brains
) kennt.
Eine Liste der Workspaces händisch pflegen? Kommt nicht in Frage, das muss auch anders gehen! Die Anwendung selbst muss ja auch
irgendwoher wissen, welche Workspaces (oder Brains
) es gibt. Also mal die Developertools des Browsers geöffnet und dann schauen was passiert...
Wenn man sich die Netzwerkanalyse anschaut, fällt beim Login auf, dass neben Google-Analytics und Google-Fonts einige Requests an api.nuclino.com geschickt werden. Unter anderem der Login an sich, aber auch etwas mit inital-state.
Auf den Request sendet der Server als Antwort eine JSON-Struktur, in der auch die Brains
zu finden sind:
{
"response":{
"userId":"<user-uuid>",
"teams":[
{
"id":"<team-uuid>",
"data":{
"name":"<team-name>",
"brains":[
"734eaf2c-b066-11ea-81bd-a36778484b6c",
"820c6310-b066-11ea-9648-bbd09f732919",
...
],
...
Das passende Perl-Skript
Jetzt haben wir alle Informationen, um die Daten aus Nuclino zu sichern. Wir wollen aber mehr. Wir wollen auch die Änderungen sehen, die von Mal zu Mal vorgenommen wurden. Dafür verwalten wir unsere Datensicherung in einem Git-Repository.
Unser Skript muss also folgendes tun:
- Sich bei Nuclino einloggen
- Die UUIDs der Brains holen
- Für jeden Brain ...
- das Zip-Archiv herunterladen
- das Archiv in das Git-Repository entpacken
- Die Änderungen committen
- Die Änderungen auf den Server pushen
Die ersten beiden Punkte werden wie folgt abgearbeitet:
use Mojo::File qw(path);
use Mojo::JSON qw(decode_json);
use Mojo::UserAgent;
use Mojo::UserAgent::CookieJar;
my $ua = Mojo::UserAgent->new(
cookie_jar => Mojo::UserAgent::CookieJar->new,
max_connections => 200,
);
my $config = decode_json path(__FILE__)->sibling('nuclino.json')->slurp;
my $header = {
# header wie in den Developertools zu sehen
};
my $base_url = 'https://api.nuclino.com/api/users/';
my $tx_init = $ua->get('https://app.nuclino.com/login');
my $tx_login = $ua->post(
$base_url . 'auth' => $header => json => $config,
);
my $tx_initial_state = $ua->get(
$base_url . 'me/initial-state' => $header
);
my @brains = @{ $tx_initial_state->res->json('/response/teams/0/data/brains') || [] };
In $ua steckt ein Objekt von Mojo::UserAgent.
Mit diesem wird erstmal die Login-Seite abgerufen, um
ein initiales Cookie zu erhalten. Ohne dieses Cookie ist der Login nicht möglich.
Anschließend loggt sich das Skript bei Nuclino ein. Hier müssen die Header so gesetzt werden, wie es der Browser auch macht.
Mit dem Request an initial-state wird dann das JSON geholt, in dem die UUIDs der Brains
stehen.
Hier zeigt sich dann auch die Eleganz der Mojo-Klassen: Mit
$tx->res->json('/response/teams/0/data/brains');
kommt man sehr einfach an die Daten. Wenn die Gegenstelle in den HTTP-Headern den richtigen
Content-Type setzt, kann man über das Response-Objekt (->res) auf ein
Mojo::JSON::Pointer-Objekt
(->json) und damit auf die JSON-Datenstruktur zugreifen. Dazu wird ein XPath-änlicher String
übergeben.
Jetzt, wo wir die UUIDs der Brains
haben, können wir die Zip-Archive einfach herunterladen:
my $backup_path = path(__FILE__)->dirname->child('..', 'backups');
for my $brain ( @brains ) {
my $url = sprintf 'https://files.nuclino.com/export/brains/%s.zip?format=md', $brain;
my $tx_backup = $ua->get(
$url => {
# header wie in den Developertools zu sehen
},
);
my $dir = $backup_path->child( $brain );
$dir->make_path;
my $zip_file = $dir->child( $brain . '.zip' );
push @zips, $zip_file->to_abs;
$tx_backup->res->save_to( $zip_file );
}
Hier wird mit Mojo::File erstmal das Zielverzeichnis erstellt.
Anschließend wird für jeden Workspace das Zip-Archiv geholt. Für jeden Workspace wird ein eigenes
Verzeichnis erstellt, in das wir dann später die Dateien entpacken können.
Als Ergebnis des GET-Requests bekommen wir ein Mojo::Transaction-Objekt.
Wie schon oben gesehen, wollen wir wieder etwas mit der Antwort
(->res) anfangen. Wenn es keine Multipart-Antwort ist, kann der Inhalt der Antwort mit save_to in eine
Datei gespeichert werden.
Im nächsten Teil vollenden wir das Skript, indem wir die Dateien im Git-Repository speichern und das Skript noch etwas schneller machen.
Permalink: /2020-08-15-nuclino-backup-I
FrOSCon 2020
Auch wenn in diesem Jahr dank Corona einiges durcheinandergewirbelt wird, lässt sich für viele Probleme eine Lösung finden. So standen und stehen die Veranstalter von Konferenzen vor dem Problem, dass sich nicht allzuviele Leute auf engem Raum treffen dürfen.
Gerade im IT-Bereich ist es aber kein Problem Konferenzen auch rein virtuell abzuhalten. So gab es im Juni die erste Perl und Raku Conference in the Cloud
und gerade vor ein paar Tagen haben wir an der ContainerConf
einige sehr interessante Vorträge gehört.
Auch die Macher der FrOSCon halten die diesjährige Konferenz online ab. Diesesmal sind wir als Partner/Sponsor mit dabei - wie schon häufiger in den letzten Jahren.

Die FrOSCon ist eine zweitägige Veranstaltung rund um Freie und Open Source Software. Normalerweise an der Hochschule Bonn-Rhein-Sieg in St. Augustin, diesmal eben online.
Auch wenn es schade ist, dass wir die vielen Leute nicht offline treffen können, freuen wir uns auf ein spannendes Vortragsprogramm. Schaut einfach mal vorbei!
Vor einigen Jahren haben wir mehrere Perl-Dev-Rooms auf der FrOSCon veranstaltet. Wenn Ihr Interesse an einem solchen Raum auf zukünftigen Veranstaltungen habt, meldet euch doch.
Permalink: /2020-08-06-froscon
Test2::V0
Perl hat eine lange Tradition im Testen. Klassischerweise werden Tests mit Hilfe der Distribution Test::More geschrieben und mit prove ausgeführt. Test::More wird jedoch seit längerem schon vielen Anforderungen nicht mehr gerecht.
Test2 ist eine Neuentwicklung eines Test-Frameworks, das diese Anforderungen erfüllt und für zukünftige Erweiterungen gerüstet ist. In diesem Artikel stellen wir dieses Framework vor.
Einleitung
In den letzten Jahren haben sich die Anforderungen an ein Test-Framework geändert. Die Verwendung von Test::More ist teilweise problematisch. Einige Probleme möchte ich hier aufführen:
- Tests und das sie ausführende Programm kommunizieren über das Textprotokoll TAP (
Test Anything Protocol
). Dieses Protokoll ist eher für Maschinen als Menschen gemacht und teilweise schwer zu lesen. Zudem unterstützt es Subtests nicht vollständig. - Die Ausgabe von TAP ist in Tests mit normaler Ausgabe vermischt. Diagnosemeldungen können nur schlecht mit Testausgaben synchronisiert werden.
- Erweiterungen sind nur schwer möglich, sodass die Weiterentwicklung mit neuen Features praktisch nicht stattfindet.
- Best Practices im Schreiben von modernem Perl-Code sind boilerplate und tribal knowledge. Praktisch immer verwendete Argumente beim Aufruf von Tests müssen immer wieder angegeben werden und sind nicht voreingestellt.* *Das macht die Verwendung umständlich.
- Das Ergebnis eines Testlaufs ist als Text in der Konsole zu sehen. Nur dort. Untersuchungen des Testlaufs kann man nur durch Inspektion dieser Ausgabe vornehmen. Es ist nicht möglich, das Ergebnis eines Testlaufs auf einem anderen Rechner zu untersuchen.
Test2 soll alles besser machen und erweiterbar sein. Zudem bietet es erweiterte Funktionalitäten und wird aktiv weiterentwickelt. Der Autor Chad Granum stellt seit 2015 wesentliche Neuentwicklungen auf der Perl Konferenz vor.
Test2 ist praktisch gut ausgreift, sodass Teile von Test::More dieses neue Framework bereits seit Jahren verwenden.
TAP und Test::More
TAP ist das Test Anything Protocol, das Testprogramme und deren Aufrufer verbindet. Es sind in der Ausgabe von Testprogrammen die Zeilen, die mit # beginnen. Sie werden von den Funktionen, die in den auf Test::Builder basierten Modulen implementiert sind, auf STDOUT ausgegeben. Außerdem gibt es Funktionen, die Diagnosemeldungen auf STDERR ausgeben.
Der Aufrufer von Testprogrammen ist bei Perl bisher in der Regel prove, das Test::Harness (Test-Harnisch
) zum Parsen von TAP verwendet und bei Bedarf STDOUT und STDERR teilweise oder ganz ausgibt.
Die Tests werden mit Test::More implementiert, das wiederum auf Test::Builder aufsetzt. Große Tests können in kleinere Subtests unterteilt werden, die dann im TAP etwas eingerückt dargestellt werden.
Im Wesentlichen werden hier von dem aufrufenden prove Textausgaben verarbeitet.
Vorteile von Test2
Test2 bietet eine Reihe von Vorzügen, die ich hier nur in Teilen ausführen kann.
Das Design ist mit den Erfahrungen der letzten 30 Jahre Perl gewählt worden und macht Erweiterungen einfacher möglich. Wegen der einfacheren Arbeit wird Test2 im Gegensatz zu Test::Harness weiterentwickelt. Ein neueres Feature ist zum Beispiel das Setzen von Timeouts, nach dessen Überschreitung ein Test abgebrochen wird.
Die Standard-Testwerkzeuge wurden behutsam sinnvoll ergänzt, andere Module werden dadurch überflüssig. is und like können nun zum Beispiel auch Datenstrukturen vergleichen. Dafür musste bisher ein eigenes Testmodul geladen werden.
Ein kurzes Beispiel:
use Test2::V0;
my $some_hash = { a => 1, b => 2, c => 3 };
is(
$some_hash,
{ a => 1, b => 2, c => 4 },
"The hash we got matches our expectations"
);
done_testing;
Wenn man dieses Testprogramm mit dem prove-Ersatz yath aufruft, erhält man folgende Ausgabe:
$ yath test2-tools-compare-is.t
** Defaulting to the 'test' command **
[ FAIL ] job 1 + The hash we got matches our expectations
[ DEBUG ] job 1 test2-tools-compare-is.t line 5
( DIAG ) job 1 +------+-----+----+-------+
( DIAG ) job 1 | PATH | GOT | OP | CHECK |
( DIAG ) job 1 +------+-----+----+-------+
( DIAG ) job 1 | {c} | 3 | eq | 4 |
( DIAG ) job 1 +------+-----+----+-------+
( DIAG ) job 1 Seeded srand with seed '20200721' from local date.
( FAILED ) job 1 test2-tools-compare-is.t
< REASON > job 1 Test script returned error (Err: 1)
< REASON > job 1 Assertion failures were encountered (Count: 1)
The following jobs failed:
+--------------------------------------+--------------------------+
| Job ID | Test File |
+--------------------------------------+--------------------------+
| 3DC85D18-CB27-11EA-A9FD-3FD6B4ADC425 | test2-tools-compare-is.t |
+--------------------------------------+--------------------------+
Yath Result Summary
-----------------------------------------------------------------------------------
Fail Count: 1
File Count: 1
Assertion Count: 1
Wall Time: 0.30 seconds
CPU Time: 0.49 seconds (usr: 0.12s | sys: 0.03s | cusr: 0.27s | csys: 0.07s)
CPU Usage: 165%
--> Result: FAILED <--
Im Gegensatz zum alleinigen TAP kann Test2 beliebige Ausgaben erzeugen, die man als Plugins nachrüsten kann. TAP ist nur eine Variante.
Das Programm prove wurde durch yath (yet another test harness
) ersetzt. Die damit erzeugte Ausgabe ist für Menschen lesbar, und nicht für Maschinen. yath protokolliert Testergebnisse als Ereignisse in Form von JSON in Dateien, die dann gut automatisiert verarbeitet werden können. Dieses Protokoll kannst du hinterher mit Bordmitteln von yath oder durch andere Programme untersuchen.
Es ist möglich, eine Testsuite mit yath ohne jegliche Ausgabe in zum Beispiel einer CI-Umgebung laufen zu lassen und das Protokoll des Testlaufs bei einem Fehlschlag beliebig oft zu untersuchen. Der folgende Aufruf ruft alle Tests im Verzeichnis t/ rekursiv auf und speichert das Protokoll des Testlaufs in komprimierter Form:
$ yath -q -B
** Defaulting to the 'test' command **
Wrote log file: /private/var/folders/cz/3j2yfjp51xq3sm7x1_f77wdh0000gn/T/2020-07-21_17:25:38_6E265890-CB66-11EA-B019-30DDB4ADC425.jsonl.bz2
The following jobs failed:
+--------------------------------------+-----------+
| Job ID | Test File |
+--------------------------------------+-----------+
| 6E274872-CB66-11EA-B019-30DDB4ADC425 | t/fail.t |
+--------------------------------------+-----------+
Yath Result Summary
-----------------------------------------------------------------------------------
Fail Count: 1
File Count: 2
Assertion Count: 4
Wall Time: 0.34 seconds
CPU Time: 0.56 seconds (usr: 0.13s | sys: 0.03s | cusr: 0.31s | csys: 0.09s)
CPU Usage: 162%
--> Result: FAILED <--
Dieses Protokoll kann dann beispielsweise auf einen Entwicklerrechner heruntergeladen und dort untersucht werden. Beispielsweise kannst du die Ereignisse eines fehlgeschlagenen Tests über dessen UUID erneut abspielen, ohne den Test selbst laufen zu lassen. Du erhältst dann exakt die gleiche Ausgabe wie bei der Ausführung der Tests:
$ yath replay /private/var/folders/cz/3j2yfjp51xq3sm7x1_f77wdh0000gn/T/2020-07-21_17:25:38_6E265890-CB66-11EA-B019-30DDB4ADC425.jsonl.bz2 6E274872-CB66-11EA-B019-30DDB4ADC425
[ FAIL ] job 1 + The hash we got matches our expectations
[ DEBUG ] job 1 t/fail.t line 5
( DIAG ) job 1 +------+-----+----+-------+
( DIAG ) job 1 | PATH | GOT | OP | CHECK |
( DIAG ) job 1 +------+-----+----+-------+
( DIAG ) job 1 | {c} | 3 | eq | 4 |
( DIAG ) job 1 +------+-----+----+-------+
( DIAG ) job 1 Seeded srand with seed '20200721' from local date.
( FAILED ) job 1 t/fail.t
< REASON > job 1 Test script returned error (Err: 1)
< REASON > job 1 Assertion failures were encountered (Count: 1)
The following jobs failed:
+--------------------------------------+-----------+
| Job ID | Test File |
+--------------------------------------+-----------+
| 6E274872-CB66-11EA-B019-30DDB4ADC425 | t/fail.t |
+--------------------------------------+-----------+
Yath Result Summary
---------------------------------------
Fail Count: 1
File Count: 2
Assertion Count: 4
--> Result: FAILED <--
STDOUT und STDERR können selbst bei Trennung von nebenläufig ausgeführten Tests über die erwähnten Ereignisse synchronisiert werden. Es ist also problemlos möglich, die Diagnosemeldungen einzelnen Tests zuzuordnen (das ist in obigem Beispiel über die angegebene Jobnummer zu erkennen). Insbesondere die Ausgabe von nebenläufig ausgeführten Tests kann weiterhin den Tests einfach zugeordnet werden. Das war mit prove bisher nicht möglich.
In der Distribution Test2::Harness::UI wird eine Webanwendung geliefert, mit der du die Ergebnisse des Testlaufs untersuchen kannst. Sie ist noch in einem frühen Entwicklungsstadium, funktioniert aber bereits. Beispiele dafür kannst du in einem Vortrag von seinem Autor Chad Granum sehen (YouTube-Video).
yath kann als Prozess laufen und Module vorladen, sodass sie nicht in jedem Testprogramm geladen werden müssen. Das bringt enorme Geschwindigkeitsvorteile – der Entwickler erhält schneller Rückmeldung und muss nicht auf Testergebnisse warten.
Testprogramm können mit Kommentaren versehen werden, die yath auswertet. Beispielsweise zeichnet der Kommentar #HARNESS-CAT-LONG ein Testprogramm als Langläufer aus, der bei nebenläufigem Aufruf vor den Kurzläufern gestartet wird, damit man nicht am Ende einer Testsuite noch auf den Langläufer warten muss.
Migrationspfad von Test::More zu Test2
Grundsätzlich sind Test2 und yath stabil und für den Produktiveinsatz geeignet.
Tatsächlich wird Test2 bereits seit Jahren von Test::More verwendet, da dies teilweise darin neu implementiert wurde (schau dir mal Test::Builder.pm an).
Eine Umstellung von Testprogrammen von Test::More auf Test2 ist in der Regel mit wenig Aufwand möglich. Es gibt dafür in der Test2-Distribution eine ausführliche Anleitung, in der die wenigen Inkompatibilitäten erklärt sind.
yath kannst du sofort ohne weiteren Aufwand als Ersatz für prove einsetzen.
Zum Weiterlesen und -sehen
- Wie man Test2 zum Schreiben von Tests verwendet (YouTube)
- Wie man yast verwendet (YouTube)
- yath, der neue
Test-Harnisch
- Test2::V0, Version 0 des empfohlenen Test2-Bundles (metacpan)
- Test2, das neue Test-Framework, das Test::Builder ersetzt (metacpan)
- Einführung in das Testen mit Test2 (metacpan)
- Anleitung zum Migrieren eines Testprogramms von Test::More zu Test2 (metacpan)
- Plugin zum Testabbruch bei Warnungen (metacpan)
- Webanwendung zum Inspizieren des Protokolls eines Testlaufs (metacpan)
- Ausgaben von Test2 als JUnit zum Einsatz in zum Beispiel Jenkins (metacpan)
- Schwarze Magie in Test2, um Preloading von Modulen umzusetzen (YouTube)
Permalink: /2020-08-01-test2
Neues in Perl 5.32
Vor etwas mehr als einem Monat hat Sawyer X eine neue Version von Perl 5 veröffentlicht: Perl 5.32. Wie schon in den Versionen davor gibt es wieder einige nützliche Features, die hinzugekommen sind.
Diese werde ich in den folgenden Abschnitten etwas näher erläutern.
Der isa-Operator
Wenn man wissen möchte, ob ein Objekt das Objekt einer bestimmten Klasse ist, war das bisher umständlich. Eine Möglichkeit ist, mit Scalar::Utils’-Funktion blessed und der universellen Methode isa zu arbeiten:
use v5.10;
use strict;
use warnings;
use Scalar::Util qw(blessed);
use HTTP::Tiny;
my $ua = HTTP::Tiny->new;
say blessed($ua) && $ua->isa('HTTP::Tiny');
Warum das blessed? Weil es sein könnte, dass in $c irgendetwas drinsteckt. Es muss ja kein Objekt sein. Und wenn es eine einfache Arrayreferenz wäre, dann käme ohne das blessed eine Fehlermeldung:
Can't call method "isa" on unblessed reference at blessed_and_isa.pl ....
Eine weitere – unschönere Möglichkeit – wäre es, mit ref zu arbeiten:
use v5.10;
use strict;
use warnings;
use HTTP::Tiny;
my $ua = HTTP::Tiny->new;
say ref( $ua ) eq 'HTTP::Tiny';
Das berücksichtigt keine Vererbung.
Mit dem neuen Infix-Operator isa ist diese Prüfung auf elegante Art und Weise möglich:
use v5.32;
use strict;
use warnings;
use feature 'isa';
no warnings 'experimental::isa';
use HTTP::Tiny;
my $ua = HTTP::Tiny->new;
say $ua isa HTTP::Tiny;
Noch ist das Feature als experimentelles Feature umgesetzt und dementsprechend muss man das Feature einschalten und dann die Warnung dazu ausschalten. Aber es vereinfacht die Abfrage, ob ein Objekt zu einer Klasse gehört oder nicht.
Auf der rechten Seite von isa kann übrigens auch ein String oder eine Variable stehen:
say $ua isa "HTTP::Tiny";
# oder
my $class = 'HTTP::Tiny';
say $ua isa $class;
Wenn sich nichts an dem Feature ändert, wird es in der Version 5.36 seinen experimentellen Status verlieren.
Verkettete Vergleiche
Endlich!
möchte man rufen und den Perl-Entwicklern danken, denn endlich sind verkette Vergleiche möglich. Jedenfalls mit einigen Operatoren und wenn sie die gleiche Vorrangigkeit haben. So kann man z.B. wesentlich einfacher und lesbarer prüfen, ob eine Zahl zwischen zwei Werten ist:
use v5.10;
use strict;
use warnings;
my $zahl = 3;
if ( 1 < $zahl < 10) {
say "Zahl zwischen 1 und 10"
}
Auch mit den String-Vergleichen und einem Misch-Masch funktioniert das:
$ perl -E 'my $str = "b"; say 1 if "a" lt $str lt "z";'
1
$ perl -E 'my $str = "d"; say 1 if "a" lt $str gt "c";'
1
$ perl -E 'my $str = "b"; say 1 if "a" lt $str gt "c";'
$ perl -E 'my $str = "d"; say 1 if "a" lt $str >= 0;'
1
$ perl -E 'my $str = "3d"; say 1 if "a" lt $str >= 0;'
$ perl -E 'my $str = "3d"; say 1 if "a" gt $str >= 0;'
1
$ perl -E 'my $str = "3d"; say 1 if "a" gt $str >= 10;'
$ perl -E 'my $str = "30d"; say 1 if "a" gt $str >= 10;'
1
Unicode in regulären Ausdrücken
Mit Perl 5.32 wird Unicode 13.0 ausgeliefert. Diese Version enthält 4 neue Skripte (u.a. jesidisch) und etliche neue Emoticons. Das macht insgesamt 5.930 neue Zeichen in Unicode.
Auch die Unterstützung von Unicode wurde verbessert. So können in Regulären Ausdrücken neben den bekannten \N{...} Ausdrücken auch in \p{...} die Namen der Zeichen verwendet werden:
use v5.32;
use strict;
use warnings;
my $string = "A";
if ( $string =~ m/^\p{na=LATIN CAPITAL LETTER A}$/) {
say "yupp, ist 'A'"
}
Besonders interessant wird es, wenn man hier Variableninterpolation nutzt:
my $string = "A";
for my $wanted ( 'SMALL', 'CAPITAL') {
if ( $string =~ m/^\p{na=LATIN $wanted LETTER A}$/) {
say $wanted;
}
}
Das funktioniert mit \N{...} nicht.
Das ganze kann man auch weiter treiben mit den Subpatterns (was allerdings schon seit Perl 5.30 geht):
no warnings 'experimental::uniprop_wildcards';
my @strings = (
"\N{GRINNING FACE}",
"\N{GRINNING FACE WITH SMILING EYES}",
"\N{KISSING FACE}",
);
for my $string ( @strings ) {
if ( $string =~ m!^\p{na=/(GRINNING|SMILING) FACE/}$!) {
say "It's a grinning or smiling face";
}
}
Sicherheitslücken geschlossen
Es wurden drei Sicherheitslücken geschlossen:
Alle drei Sicherheit betreffen Reguläre Ausdrücke. In der Regel ist man davon aber nur betroffen, wenn man ungeprüft Reguläre Ausdrücke von anderen ausführt.
Etliche Module aktualisiert
Der Perl-Core liefert viele Module mit. Viele dieser Module werden aber parallel dazu auch auf CPAN veröffentlicht, so dass man auch in älteren Perl-Versionen die verbesserten Module nutzen kann.
Eine Vielzahl dieser Module wurden im Perl-Core auch aktualisiert. Dies sind z.B.
- Encode
- Time::Piece
- Unicode::Normalize
- threads
Dokumentation zur Funktion open
überarbeitet
Die Perl-Dokumentation ist sehr umfangreich, aber auch dort gibt es unmodernen Perl-Code und manchmal sind Zusammenhänge nicht ausführlich beschrieben.
Die Funktion open ist essentiell in Perl. Die Dokumentation dazu wurde von Jason McIntosh im Zuge eines Grants der Perl-Foundation umgeschrieben. Im gleichen Zug wurde auch die Dokumentation perlopentut – das etliche Code-Schnipsel für open enthält – erweitert.
Perl wird auf Github entwickelt
Ok, das ist keine Weiterentwicklung der Sprache an sich, aber ich sehe das dennoch als gute Sache – es wird für die Community einfacher, sich an der Enwicklung zu beteiligen.
Einen GitHub-Account haben viele, so dass die Beteiligung deutlich einfacher ist. Viele sind auch eher auf GitHub unterwegs als dass sie auf rt.cpan.org geschaut haben. So bekommt man als interessierte Person Diskussionen in den Tickets besser mit.
Durch den Umstieg können auch die GitHub-Actions genutzt werden, so dass die Commits gleich in mehreren Konfigurationen getestet werden können.
Wer die neuen Features wie den isa-Operator ausprobieren möchte, dem kann ich perlbanjo.com empfehlen. Einfach die einzelnen Code-Snippets dorthin kopieren und laufen lassen.
Eine ausführlichere Liste der Änderungen – z.B. mit der Liste der aktualisierten Module – ist wie immer in den perldelta - what is new for perl v5.32.0 - Perldoc Browser zu finden.
Noch Fragen? Dann am besten eine Mail an uns schicken oder uns auf Twitter kontaktieren.
Permalink: /2020-07-22-neues-in-perl5-32
CPAN Updates - Juli 2020
Gregor und ich haben einige CPAN-Module. Wir wollen hier an dieser Stelle auch immer wieder auf wichtige Neuerungen in unseren Modulen aufmerksam machen.
In den letzten Wochen habe ich vermehrt an MySQL::Workbench::Parser
und MySQL::Workbench::DBIC gearbeitet um die Abbildung von
Views zu unterstützen.
In der Workbench können ganz einfach Views hinzugefügt werden. In der Konfiguration muss nur das SQL-Statement angegeben werden, wie der View aufgebaut werden soll:
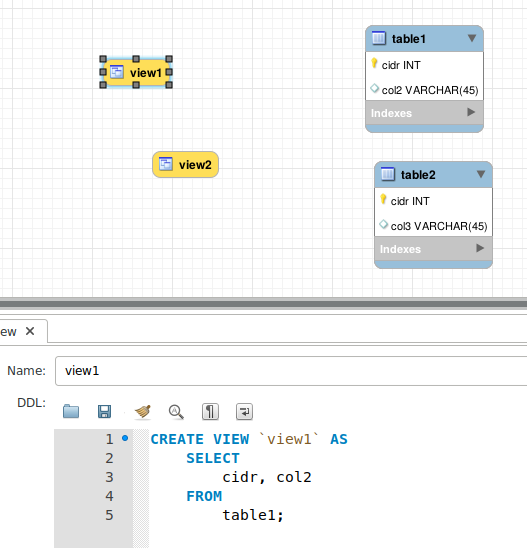
Der Vorteil der Workbench liegt darin, dass man mit Kunden und auch untereinander einfach die Workbench-Datei austauschen kann und man etwas grafisches vor Augen hat wenn man das Datenbankschema bespricht.
Wir nutzen die Workbench und die beiden Module in verschiedenen Projekten um
DBIx::Class-Klassen für den Zugriff auf die Datenbank zu erzeugen.
Mit einem kleinen Skript lässt sich der Perl-Code ganz einfach generieren:
use Mojo::File qw(curfile);
use MySQL::Workbench::DBIC;
my $foo = MySQL::Workbench::DBIC->new(
file => curfile->sibling('view.mwb')->to_string,
output_path => curfile->sibling('lib')->to_string,
namespace => 'Project::DB',
schema_name => 'Schema',
column_details => 1, # default 1
);
$foo->create_schema;
print sprintf "Version %s of DB created\n", $foo->version;
Damit werden dann folgende Dateien erstellt:
$ tree lib
lib
└── Project
└── DB
├── Schema
│ └── Result
│ ├── table1.pm
│ └── table2.pm
└── Schema.pm
table1.pm und table2.pm repräsentieren die entsprechenden Tabellen (siehe Abbildung weiter oben) und
mit den neuen Versionen von MySQL::Workbench::Parser und MySQL::Workbench::DBIC werden die Klassen
view1.pm und view2.pm erzeugt.
Die Klassen sehen wie folgt aus:
package Project::DB::Schema::Result::view1;
# ABSTRACT: Result class for view1
use strict;
use warnings;
use base qw(DBIx::Class);
our $VERSION = 0.05;
__PACKAGE__->load_components( qw/PK::Auto Core/ );
__PACKAGE__->table_class('DBIx::Class::ResultSource::View');
__PACKAGE__->table( 'view1' );
__PACKAGE__->result_source_instance->view_definition(
"CREATE VIEW `view1` AS
SELECT
cidr, col2
FROM
table1;"
);
__PACKAGE__->result_source_instance->deploy_depends_on(
["Project::DB::Schema::Result::table1"]
);
__PACKAGE__->add_columns(
cidr => {
data_type => 'INT',
is_numeric => 1,
},
col2 => {
data_type => 'VARCHAR',
is_nullable => 1,
size => 45,
},
);
Die entscheidenden Zeilen sind
__PACKAGE__->table_class('DBIx::Class::ResultSource::View');
__PACKAGE__->result_source_instance->view_definition(
"CREATE VIEW `view1` AS
SELECT
cidr, col2
FROM
table1;"
);
Als Klasse, wird hier DBIx::Class::ResultSource::View verwendet, das extra für Views
existiert. Anschließend erfolgt die SQL-Definition, wie sie in der Workbench eingetragen
wurde.
Hier wird absichtlich kein
__PACKAGE__->result_source_instance->is_virtual(1);
verwendet, weil die Views tatsächlich in der Datenbank angelegt werden sollen. Mit is_virtual(1)
wird der View rein virtuell behandelt.
Über diese Module habe ich übrigens im letzten Jahr auf dem Deutschen Perl-Workshop einen Vortrag gehalten:
Die Code-Beispiele liegen wieder im Gitlab-Repository.
Permalink: /2020-07-17-cpan-updates
Modul des Monats Juli 2020
Markdown ist ziemlich weit verbreitet, wenn es um Textdokumente geht. Das Format bietet auch viele Vorteile gegenüber anderen Auszeichnungssprachen:
- Es ist schlank und es behindert den Lesefluss nicht.
- Es ist einfach zu erlernen.
- Für (fast) alle Sprachen gibt es Module, um es z.B. nach HTML zu konvertieren.
- Die Integration in verschiedene Tools ist weit verbreitet.
Das Ursprungsmarkdown kann nur einen beschränkten Satz an Befehlen
wie Überschriften, Hervorhebung und Links.
Mit der Zeit sind – wie zu erwarten war – einige Erweiterungen entwickelt
worden. So gibt es z.B. noch MultiMarkdown,
CommonMark und Hoedown.
Mit diesen Erweiterungen werden dann auch Tabellen, Code-Blöcke und noch mehr unterstützt.
Wir setzen bei verschiedensten Projekte Markdown ein – z.B. sind die Artikel für dieses Blog alle in Markdown geschrieben. Das hat den Vorteil, dass wir die Texte in jedem Editor schreiben können und wenn sie auf Gitlab landen, werden sie auch im Browser gleich ansehnlich dargestellt.
Damit Sie die Artikel auch hier im Blog so ansehnlich angezeigt bekommen, müssen wir das Markdown in HTML
umwandeln. Dazu setzen wir das Modul Text::Markdown::Hoedown
ein.
Es ist daher unser erstes Modul des Monats!
Die Nutzung des Moduls ist ziemlich einfach:
use v5.20;
use Text::Markdown::Hoedown;
my $md = q~
# Blogartikel
Das [Perl-Academy Blog](https://blog.perl-academy.de)
enthält einige *interessante* Blogartikel
~;
say markdown $md;
Der obige Code gibt folgendes HTML aus:
$ perl hoedown/hoedown.pl
<h1 id="toc_0">Blogartikel</h1>
<p>Das <a href="https://blog.perl-academy.de">Perl-Academy Blog</a>
enthält einige <em>interessante</em> Blogartikel</p>
Wie weiter oben schon erwähnt, enthält das Standardmarkdown nur wenige Elemente. Hoedown unterstützt aber einige Erweiterungen, die man explizit und einzeln aktivieren muss. Tabellen werden im Standard nicht unterstützt. Die Erweiterungen unterstützen aber zum Glück einheitliche Syntax, für Tabellen sieht das so aus:
my $md = q~
# veröffentlichte Artikel
Datum | Titel
------+-------
01.07.2020 | Blog-Revival
10.07.2020 | Modul des Monats Juli 2020
~;
say markdown $md
Das gibt erstmal nur
$ perl hoedown/table.pl
<h1 id="toc_0">veröffentlichte Artikel</h1>
<p>Datum | Titel
-----------+-------
01.07.2020 | Blog-Revival
10.07.2020 | Modul des Monats Juli 2020</p>
aus. Bei dem markdown-Aufruf kann man noch Optionen mitgeben. Unter anderem
kann man hier festlegen, welche Erweiterungen aktiviert werden sollen. Für die Tabellen
wäre das HOEDOWN_EXT_TABLES. Der Aufruf sieht dann folgendermaßen aus:
say markdown $md,
extensions => HOEDOWN_EXT_TABLES;
Damit Sie die Code-Beispiele mit so einem schönen Highlighting sehen können, nutzen
wir im Markdown sogenannte Fenced codes
. Diese werden mit ``` eingeschlossen.
Damit das korrekte Highlighting für die Programmiersprache verwendet
wird, muss diese zu Beginn angegeben werden. Für Perl-Code sieht dies
dann so aus:
# Perl-Code
```perl
use Text::Markdown::Hoedown;
my $md = '# Test';
print markdown $md;
```
Da das ebenfalls nicht zum Standard gehört, muss man die entsprechende Erweiterung aktivieren:
say markdown $md,
extensions => HOEDOWN_EXT_TABLES | HOEDOWN_EXT_FENCED_CODE;
Der Code-Block ergibt folgenden HTML-Code:
<pre><code class="language-perl">use Text::Markdown::Hoedown;
my $md = '# Test';
print markdown $md;
</code></pre>
Das Highlighting wird also nicht von Hoedown gemacht, sondern es wird
nur ein einfacher <code>-Block erzeugt, dessen Klasse entsprechend
der angegebenen Programmiersprache gesetzt wird.
Für die Farbgebung hier nutzen wir prism.js.
Die Beispielprogramme habe ich in einem extra Gitlab-Repository bereitgestellt.
Permalink: /2020-07-10-modul-des-monats-markdown
Die Perl-Academy lebt!
Auf Perl-Academy.de war es jetzt längere Zeit ziemlich ruhig. Seit über einem Jahr haben wir keine Schulungstermine mehr veröffentlicht und noch länger war hier nichts zu lesen.
Wenn man zeigen möchte, dass etwas nicht in der Versenkung verschwindet, sondern wie Phönix aus der Asche aufsteht, dann muss das auch offensichtlich sein. Die erste augenscheinliche Änderung auf Perl-Academy ist das Design.
Die zweite Änderung ist hier dieser Blog. Vorher gab es nur einige sporadische Einträge im News
-Bereich. Diesen Blog wollen
wir allgemeiner halten und dazu in regelmäßigen Abständen Artikel zu Perl,
Modulen, Softwareentwicklung allgemein und unseren Schulungen veröffentlichen.
Hier kommt eine weitere Änderung zum Tragen: Ich bin nicht mehr alleine. Neben mir wird auch Gregor in diesem Blog und bei Schulungen aktiv werden. Gregor wird sich bei Gelegenheit auch hier noch vorstellen.
Außerdem überarbeiten wir unser Schulungsangebot. Einige Themen nehmen wir aus dem Programm, andere Schulungen gestalten wir etwas um.
Wenn Sie Fragen, Wünsche oder Anregungen haben, schreiben Sie uns doch bitte eine Nachricht.
In diesem Sinne wünsche ich Ihnen schon einmal viel Spaß beim Durchstöbern der Artikel.
Permalink: /2020-07-01-academy-revival