Git-Hooks mit Perl
Git ist eine weit verbreitete Software zur Versionsverwaltung. Wir nutzen Git seit vielen Jahren, um unseren Perl-Code zu verwalten. Soll im Git-Workflow etwas erzwungen werden, kommen sogenannte Git-Hooks zum Einsatz.
Wenn Code committet oder zum Server ge*pusht* wird, werden diese Hooks ausgeführt. Das sind Skripte, die automatisch bei diesen Events ausgeführt werden. Eine Liste mit den ganzen Events ist im Git-Handbuch zu finden. Man unterscheidet die Hooks danach, ob sie auf dem Client oder auf dem Server ausgeführt werden.
Git ist bei den Hooks sehr flexibel und die Hooks können in allen möglichen Programmiersprachen umgesetzt werden – auch in Perl. Hier soll ein Beispiel gezeigt werden, wie ein solcher Hook aussehen kann. Ziel ist es, bei einem vorhandenen cpanfile die darin genannten Perl-Module zu prüfen, ob sie in CPAN::Audit genannt sind. Damit soll einfach sichergestellt werden, dass schon bei der Entwicklung auf Sicherheitslücken in eingesetzten Perl-Modulen hingewiesen wird.
Client-Hooks
Im ersten Schritt schreiben wir ein Skript, das auf dem Client ausgeführt wird. Die Hooks liegen im Ordner .git/hook. Dort erstellen wir eine Datei mit dem Namen des Events auf das wir reagieren wollen. In diesem Fall möchten wir die Prüfung nach jedem Commit machen. Daher erstellen wir die Datei post-commit und machen diese ausführbar.
In diesem Fall werden keine Paramter übergeben. Wir werten mit CPANfile::Parse::PPI die Datei cpanfile aus und prüfen dann die Module mittels CPAN::Audit:
#!/usr/bin/perl
use v5.24;
use strict;
use warnings;
use File::Basename;
use File::Spec;
use CPAN::Audit::DB;
use CPAN::Audit::Query;
use CPANfile::Parse::PPI;
my $basedir = File::Spec->catdir( dirname(__FILE__), '..','..');
my $file = File::Spec->catfile( $basedir, qw/cpanfile/ );
my $db = CPAN::Audit::DB->db;
my $query = CPAN::Audit::Query->new( db => $db );
my $cpanfile = CPANfile::Parse::PPI->new( $file );
MODULE:
for my $module ( $cpanfile->modules->@* ) {
my $distname = $db->{module2dist}->{$module->{name}};
next MODULE if !$distname;
my @advisories = $query->advisories_for( $distname, $module->{version} );
next MODULE if !@advisories;
print sprintf "There are advisories for %s %s\n", $module->{name}, $module->{version};
}
Angenommen wir haben folgendes cpanfile:
requires 'Mojolicious' => 8.42;
requires 'Archive::Zip' => 0;
Dann kommt bei einem Commit diese Meldung:

So kann schon während der Entwicklung sichergestellt werden, dass man auf Module aufmerksam gemacht wird, für die Sicherheitslücken bekannt sind.
Dieser Git-Hook ist ganz praktisch, hat aber – wie alle clientseitigen Hooks – das Problem, dass sie bei einem git clone nicht mitgeklont werden. Die Hooks müssen also auf anderem Wege verteilt werden. Und es ist nicht sichergestellt, dass alle Hooks in den Arbeitskopien auch tatsächlich angewendet werden.
Sollen also gewisse Richtlinien erzwungen werden, ist es notwendig die Hooks auf dem Server einzurichten – mit einem passenden Event.
Server-Hooks
Soll der gleiche Hook wie auf dem Server nach einem push ausgeführt werden, muss das Skript direkt auf dem Server abgelegt werden. Testen können wir das, indem ein neues Git-Repository erstellt wird:
mkdir TestRepository
cd TestRepository
git init --bare
Da wir das init mit dem Parameter --bare aufgerufen haben, werden in dem Repository keine Dateien mit Code zu finden sein. Die Verzeichnisstruktur ist auch eine andere. Hier haben wir direkt die Struktur, wie sie in der Arbeitskopie im Verzeichnis .git/ zu finden ist.
Der Hook von oben muss in das Verzeichnis hooks/ kopiert werden, aber mit einem neuen Namen: post-receive. Das ist das Event, das nach einem push ausgelöst wird. Es verhindert also nicht, dass die Entwickler*innen Code auf den Server schieben, aber man kann beliebige Meldungen ausgeben. Soll ein push erfolglos sein, wenn ein Modul mit Sicherheitslücken im cpanfile gelistet ist, müssen wir den Hook von oben als pre-receive speichern.
Eine weitere Änderung ist notwendig, da – wie oben geschrieben – keine Dateien mit Code im Repository zu finden sind. Inhalte der Dateien lassen sich mit git show auslesen, daher sieht hier der entsprechende Teil des Hooks folgendermaßen aus:
my @args = <>;
chomp @args;
my $branch = (split /\s+/, $args[0])[-1];
my $required = qx{git show $branch:cpanfile};
my $db = CPAN::Audit::DB->db;
my $query = CPAN::Audit::Query->new( db => $db );
my $cpanfile = CPANfile::Parse::PPI->new( \$required );
Dieser Hook bekommt die Parameter alter Commithash
, neuer Commithash
und Branch über STDIN. Hier wird also immer das cpanfile des Branchs ausgelesen, der zum Server geschickt wird.
Wird jetzt ein push der Änderungen gemacht, meldet sich der Server mit
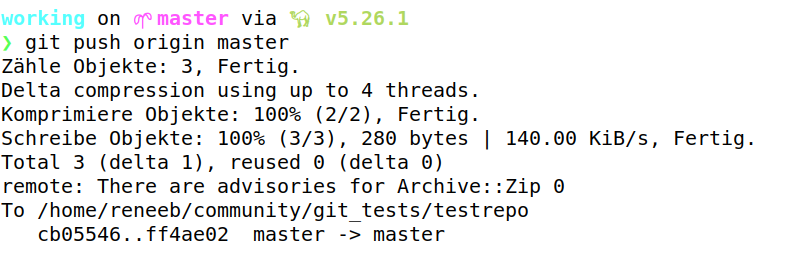
Das was bisher gezeigt wurde, gilt für git pur. Wir verwenden zur Verwaltung unserer Git-Repositories Gitlab. Neben den klassischen Git-Features nutzen wir hier vor allem die Continuous Integration Features.
Mit Gitlab sieht der Einsatz der serverseitigen Hooks etwas anders aus: Zuerst brauchen wir den Pfad zum (bereits existierenden) Repository. Dazu öffnen wir den Adminbereich und schauen uns das gewünschte Projekt/Repository an. Dort finden wir einen Eintrag Gitaly relative path: **@hashed/2c/69/2c69\[...\]bde.git**. Wir müssen auf dem Server in das Verzeichnis von Gitaly, z.B. /srv/gitlab/data/git-data/repositories/. Danach in das Verzeichnis wechseln, das im Adminbereich von Gitlab ausgelesen wurde.
Gitlab hat den oben gezeigten hooks-Ordner für etwas anderes benutzt. Aus diesem Grund dürfen die Hooks aber nicht in das Verzeichnis hooks/, sondern es muss ein Verzeichnis custom_hooks/ angelegt werden. Dort wird der Hook gespeichert. Der Rest bleibt wie gezeigt.
Quellen:
- https://www.digitalocean.com/community/tutorials/how-to-use-git-hooks-to-automate-development-and-deployment-tasks
- https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks
- https://medium.com/weekly-webtips/how-to-create-and-run-git-hooks-d395ec60d0d
- https://www.atlassian.com/git/tutorials/git-hooks
Permalink: /2021-01-06-git-hooks-mit-perl